Analyzer原理
【常用分词器】
- SimpleAnalyzer
- StopAnalyzer
- WhitespaceAnalyzer
- StandardAnalyze
【TokenStream】
she is a student ==〉TokenStream
TokenStream有2个实现类。Tokenizer、TokenFilter
1) Tokenizer
将数据进行分割形成一定的语汇(所谓语汇是指一个一个独立的词语。)。最终结果将形成TokenStream。

2) TokenFilter
按照规则对语汇进行过滤。如:StopFilter可以对停用词进行过滤。
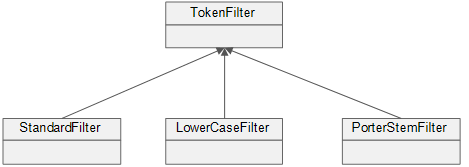
3) 执行过程

【存储方式】

【应用TokenStream】
/**
* 使用TokenStream进行分词
* @param str
* @param analyzer
*/
public static void displayTokenStream(String str, Analyzer analyzer){
try {
//通过Analayer获取TokenStream
//toenStream("域名称或文件名",输入流对象)
TokenStream stream = analyzer.tokenStream("content", new StringReader(str)); //向流中添加一个属性
//容器,存储每次分词所对应的语汇内容
CharTermAttribute charAttr = stream.addAttribute(CharTermAttribute.class); //通过循环语句读取语汇的内容
while(stream.incrementToken()){
System.out.print("[" + charAttr + "] ");
}
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
private Version version = Version.LUCENE_35;
/**
* 测试TokenStream(英文内容)
*/
@Test
public void test01(){
String str = "I'm come from Hanlin,I love Hanlin";
System.out.println("str = " + str);
System.out.println("====================================");
//创建Analyzer对象
Analyzer a1 = new SimpleAnalyzer(version);
Analyzer a2 = new StopAnalyzer(version);
Analyzer a3 = new WhitespaceAnalyzer(version);
Analyzer a4 = new StandardAnalyzer(version);
//测试TokenStream
AnalyzerUtil.displayTokenStream(str, a1);
AnalyzerUtil.displayTokenStream(str, a2);
AnalyzerUtil.displayTokenStream(str, a3);
AnalyzerUtil.displayTokenStream(str, a4);
}
/**
* 测试TokenStream(中文内容)
*/
@Test
public void test02(){
String str = "我来自翰林,我爱翰林";
System.out.println("str = " + str);
System.out.println("===================================="); //创建Analyzer对象
Analyzer a1 = new SimpleAnalyzer(version);
Analyzer a2 = new StopAnalyzer(version);
Analyzer a3 = new WhitespaceAnalyzer(version);
Analyzer a4 = new StandardAnalyzer(version); //测试TokenStream
AnalyzerUtil.displayTokenStream(str, a1);
AnalyzerUtil.displayTokenStream(str, a2);
AnalyzerUtil.displayTokenStream(str, a3);
AnalyzerUtil.displayTokenStream(str, a4);
}
TokenStream可以读取到分词内容.
【Attribute】
/**
* 显示语汇的基本属性
* @param str
* @param anlyzer
*/
public static void displayAttributes(String str, Analyzer anlyzer){
try {
//获取TokenStream对象
TokenStream stream = anlyzer.tokenStream("content", new StringReader(str)); //PositionIncrementAttribute :存储了语汇之间的位置增量
//添加PositionIncrementAttribute属性
PositionIncrementAttribute positionAttr = stream.addAttribute(PositionIncrementAttribute.class); //添加CharTermAttrbute
CharTermAttribute charAttr = stream.addAttribute(CharTermAttribute.class);
//OffsetAttribute:获取语汇的偏移数据
OffsetAttribute offsetAttr = stream.addAttribute(OffsetAttribute.class); //语汇的分词方式类型(了解)
TypeAttribute typeAttr = stream.addAttribute(TypeAttribute.class); //遍历每一个语汇
while(stream.incrementToken()){
System.out.print(positionAttr.getPositionIncrement() + "、");
System.out.print("[" + charAttr + " : " + offsetAttr.startOffset() + "~" + offsetAttr.endOffset()+ "(" + typeAttr.type()+ ")] " );
}
System.out.println(); } catch (IOException e) {
e.printStackTrace();
}
}
/**
* 测试属性的应用
*/
@Test
public void test03(){
String str = "I'm come from Hanlin,I love Hanlin";
System.out.println("str = " + str);
System.out.println("===================================="); //创建Analyzer对象
Analyzer a1 = new SimpleAnalyzer(version);
Analyzer a2 = new StopAnalyzer(version);
Analyzer a3 = new WhitespaceAnalyzer(version);
Analyzer a4 = new StandardAnalyzer(version); //测试TokenStream
AnalyzerUtil.displayAttributes(str, a1);
AnalyzerUtil.displayAttributes(str, a2);
AnalyzerUtil.displayAttributes(str, a3);
AnalyzerUtil.displayAttributes(str, a4);
}
FlagsAttribute:标志位属性信息(了解)
PayloadAttribute:负载属性信息(了解)
说明:每一个语汇单元都存在一定的属性.通过Attribute可以获取到相关的语汇信息。
Analyzer原理的更多相关文章
- Lucene 工作原理 之倒排索引
1.简介 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址.由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排 ...
- Compiler Theory(编译原理)、词法/语法/AST/中间代码优化在Webshell检测上的应用
catalog . 引论 . 构建一个编译器的相关科学 . 程序设计语言基础 . 一个简单的语法制导翻译器 . 简单表达式的翻译器(源代码示例) . 词法分析 . 生成中间代码 . 词法分析器的实现 ...
- LDO稳压器工作原理
LDO稳压器工作原理 随着便携式设备(电池供电)在过去十年间的快速增长,像原来的业界标准 LM340 和LM317 这样的稳压器件已经无法满足新的需要.这些稳压器使用NPN 达林顿管,在本文中称其为N ...
- IKAnalyzer原理分析
IKAnalyzer原理分析 IKAnalyzer自带的 void org.wltea.analyzer.dic.Dictionary.disableWords(Collection<Strin ...
- 免费的Lucene 原理与代码分析完整版下载
Lucene是一个基于Java的高效的全文检索库.那么什么是全文检索,为什么需要全文检索?目前人们生活中出现的数据总的来说分为两类:结构化数据和非结构化数据.很容易理解,结构化数据是有固定格式和结构的 ...
- R语言︱文本挖掘之中文分词包——Rwordseg包(原理、功能、详解)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:与前面的RsowballC分词不同的 ...
- Lucene 的索引文件锁原理
Lucene 的索引文件锁原理 2016/11/24 · IT技术 · lucene 环境 Lucene 6.0.0Java “1.8.0_111”OS Windows 7 Ultimate 线程 ...
- springboot之启动原理解析
前言 SpringBoot为我们做的自动配置,确实方便快捷,但是对于新手来说,如果不大懂SpringBoot内部启动原理,以后难免会吃亏.所以这次博主就跟你们一起一步步揭开SpringBoot的神秘面 ...
- SpringBoot启动原理及相关流程
一.springboot启动原理及相关流程概览 springboot是基于spring的新型的轻量级框架,最厉害的地方当属自动配置.那我们就可以根据启动流程和相关原理来看看,如何实现传奇的自动配置 二 ...
随机推荐
- ROS学习笔记九:ROS工具
ROS有各种工具可以帮助用户使用ROS.应该指出,这些GUI工具是对输入型命令工具的补充.如果包括ROS用户个人发布的工具,那么ROS工具的数量很庞大.其中,本文讨论的工具是对于ROS编程非常有用的辅 ...
- 数据结构 - 动态单链表的实行(C语言)
动态单链表的实现 1 单链表存储结构代码描述 若链表没有头结点,则头指针是指向第一个结点的指针. 若链表有头结点,则头指针是指向头结点的指针. 空链表的示意图: 带有头结点的单链表: 不带头结点的单链 ...
- 配置Ubuntu16.04第03步:安装搜狗输入法
1.进入搜狗官网:https://pinyin.sogou.com/linux/ ,下载搜狗输入法安装包 2.使用dpkg命令安装Deb包: sudo dpkg -i sogoupinyin_2.0. ...
- leaflet在地图上加载本地图片
<link href="~/Scripts/Leaflet/leaflet.css" rel="stylesheet" /><script s ...
- 200 Number of Islands 岛屿的个数
给定 '1'(陆地)和 '0'(水)的二维网格图,计算岛屿的数量.一个岛被水包围,并且通过水平或垂直连接相邻的陆地而形成.你可以假设网格的四个边均被水包围.示例 1:11110110101100000 ...
- Ajax记录
Ajax简介 在传统的Web应用中,每次请求服务器都会生成新的页面,用户在提交请求后,总是要等待服务器的相应.如果前一个请求没有得到相应,则后一个请求就不能发送.由于这是一种独占式的请求,因此如果服务 ...
- Android使用Gson(相当于C#的Newtonsoft.Json)非常好用
C#转Java有一段时间了,之前做ASP.NET WebAPI微软竟将第三方类库Newtonsoft.Json作为VS新建MVC和WebAPI项目默认必备的Json工具Nuget包,可想而知这个包有多 ...
- 文档兼容性定义,使ie按指定的版本解析
作为开发人员,特别是作为Web的前端开发人员 ,最悲催的莫过于要不断的,不断的去调试各种浏览器的显示效果,而这其中最让人头痛的莫过于MS下的IE系列浏览器,在IE系列中的调试我们将会发现没有一个是好伺 ...
- Jvisualvm--JAVA性能分析工具
JDK自带的JAVA性能分析工具.它已经在你的JDK bin目录里了,只要你使用的是JDK1.6 Update7之后的版本.点击一下jvisualvm.exe图标它就可以运行了. 这里是VisualV ...
- ubuntu15.04安装 RVM
首先,请参考这篇文章 https://ruby-china.org/wiki/rvm-guide RVM 官方网站 https://rvm.io/ 1 由于现在很多网站都转向https链接,所以,根据 ...