045 RDD与DataFrame互相转换
一:RDD与DataFrame互相转换
1.总纲

二:DataFrame转换为RDD
1.rdd
使用schema可以获取DataFrame的schema
使用rdd可以获取DataFrame的数据
三:RDD转换为DataFrame
1.第一种方式
使用反射,
RDD的数据类型必须是case class。
import sqlContext.implicits._ //如果不写,下面的转换不成功
//transform
val path="/spark/logs/input"
val rdd=sc.textFile(path)
val apacheAccessDataFrame=rdd
.filter(line=>ApacheAccessLog.isValidateLogLine(line))
.map(line => {
ApacheAccessLog.parseLogLine(line)
}).toDF() //rdd转换为DataFrame
其中,ApacheAccessLog.parseLogLine(line)是case class类型。
2:第二种方式
package com.scala.it
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object CreateDataFrameDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("hive-join-mysql")
// 使用kryo序列化机制
conf.registerKryoClasses(Array(classOf[Row], classOf[Tuple3[Int, String, Double]]))
val sc = SparkContext.getOrCreate(conf) val sqlContext = new SQLContext(sc) // ===================================
// RDD中Row中的各个列的类型必须是一致的(不能有歧义)
val rdd: RDD[Row] = sc.parallelize(Array(
(1, "Tom", 1234.1),
(2, "Lili", 12532.2),
(3, "Gerry", 123.0)
)).map {
case (id, name, salary) => {
Row(id, name, salary)
}
}
val schema: StructType = StructType(Array(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("salary", DoubleType)
)) val df = sqlContext.createDataFrame(rdd, schema)
df.show()
}
}
3.解释上面的程序
产生RDD有两种方式,读取数据源,或者序列化
这里使用序列化产生RDD。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
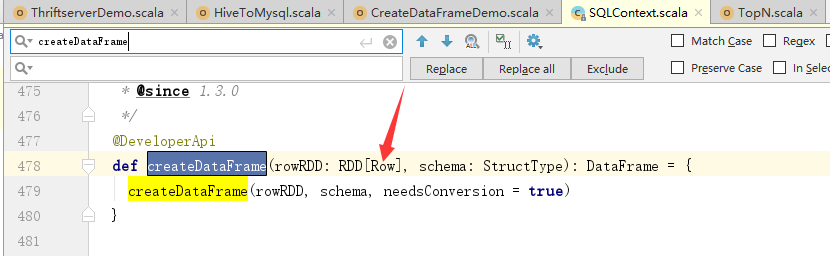
关于rdd中为什么要使用Row:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
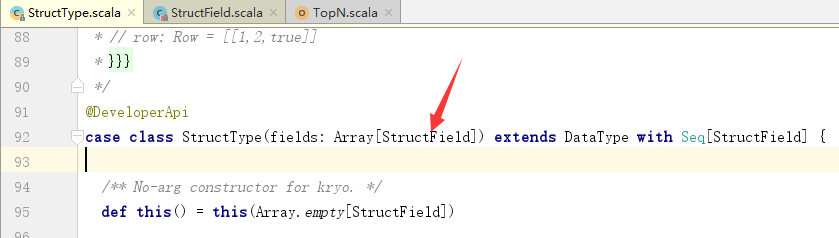
关于StructType:
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
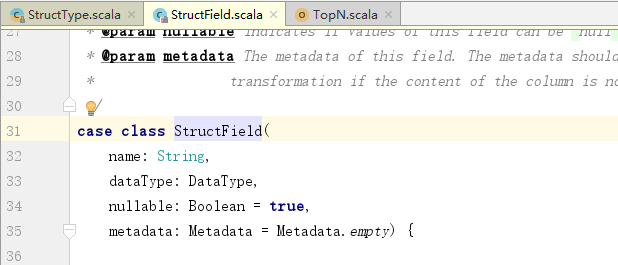
关于StructField:
其中,后两个是默认参数,可以不给。
045 RDD与DataFrame互相转换的更多相关文章
- RDD与DataFrame的转换
RDD与DataFrame转换1. 通过反射的方式来推断RDD元素中的元数据.因为RDD本身一条数据本身是没有元数据的,例如Person,而Person有name,id等,而record是不知道这些的 ...
- 转】RDD与DataFrame的转换
原博文出自于: http://www.cnblogs.com/namhwik/p/5967910.html RDD与DataFrame转换1. 通过反射的方式来推断RDD元素中的元数据.因为RDD本身 ...
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
- 36、将RDD转换为DataFrame
一.概述 为什么要将RDD转换为DataFrame? 因为这样的话,我们就可以直接针对HDFS等任何可以构建为RDD的数据,使用Spark SQL进行SQL查询了.这个功能是无比强大的. 想象一下,针 ...
- spark-DataFrame之RDD和DataFrame之间的转换
package cn.spark.study.core.mycode_dataFrame; import java.io.Serializable;import java.util.List; imp ...
- RDD、DataFrame、Dataset三者三者之间转换
转化: RDD.DataFrame.Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换 DataFrame/Dataset转RDD: 这个转换很简单 val rdd1=testDF. ...
- RDD、DataFrame和DataSet的区别
原文链接:http://www.jianshu.com/p/c0181667daa0 RDD.DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同. RDD ...
- 谈谈RDD、DataFrame、Dataset的区别和各自的优势
在spark中,RDD.DataFrame.Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1.RDD.DataFrame.Dataset全都是spar ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
随机推荐
- js对数组中的数字排序
1 前言 如果数组里面都是数字,如果用原生的sort,默认是按字符串排序的,不符合我们的要求 2 代码 方法1:添加Array的原生方法 Array.prototype.sort2 =function ...
- html跳转指定位置-利用锚点
比如我现在 a.html 的时候,我想跳转到 b.html ,并且是 b.html 的某一个位置,用 <a href=>, a.html里: <a href="b.html ...
- 使用SimHash进行海量文本去重[转]
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- Windows下安装Confluence并破解汉化
注:本文来源于<Windows下安装Confluence并破解汉化> 一.事前准备 1:JDK下载并安装:jdk-6u45-windows-i586.exe 2:MySQL JDBC连接驱 ...
- Confluence 6 配置服务器基础地址
服务器基础地址(Server Base URL)是用户访问 Confluence 的 URL 地址.这个基础的 URL 地址必须与你在浏览器中访问 Confluence 中的地址. Confluenc ...
- Confluence 6 嵌入的 H2 数据库
为了让你的 Confluence 在安装成功后就可以使用而不需要使用任何外部的数据库,Confluence 使用一个嵌入的 H2 数据库. 当你选择对 Confluence 进行评估和测试的时候,H2 ...
- Confluence 6 workbox 包含从 Jira 来的通知
如果你的 Confluence 站点链接了一个 Jira 应用,你可以包含从 Jira 应用来的通知,例如 Jira 软化或 Jira 服务器桌面. 希望包含有从 Jira 应用来的通知: 你的 Ji ...
- 探索一个NSObject对象占用多少内存?
1 下面写代码测试探索NSObject的本质 Objective-C代码,底层实现其实都是C\C++代码 #import <Foundation/Foundation.h> int mai ...
- Python查找最新测试报告到邮件功能
#coding=utf-8 import smtplib from email.mime.text import MIMEText import unittest import HTMLTestRun ...
- django模板 内建标签
autoescape 控制当前自动转义的行为,有on和off两个选项 {% autoescape on %} {{ body }} {% endautoescape %} block 定义一个子模板可 ...