HDFS 概述
定义
HDFS(Hadoop Distributed File System)是分布式文件管理系统中的一种,用来管理多台机器上的文件,通过目录树来定位文件。
由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
适合一次写入,多次读取,且不支持文件的修改。适合用来做数据分析,不适合用来做网盘应用。
优缺点
优点:
1.高容错性
数据自动保存多个副本。通过增加副本的形式,提高容错性
某一个副本丢失以后,可以自动恢复
2.适合处理大数据。
3.可运行在廉价机器上,通过多副本机制,提高可靠性。
缺点:
1.无法低延时访问数据,如毫秒级的存储数据。
2.无法高效的对大量小文件进行存储。
大量小文件会占用 NameNode 大量的内存来存储文件目录信息和块信息
小文件的寻址时间会超过读取时间
3.无法并发写入和文件随机修改。
HDFS上一个文件只能有一个线程写,不允许多个线程同时写
HDFS上的文件仅支持数据append(追加),不支持文件的随机修改
HDFS 组成
HDFS 为 主(Master) / 从(Slave) 架构:一个 NameNode,多个 DataNode(通常是群集中每个节点一个) NameNode:管理文件系统命名空间(打开、关闭、重命名文件和目录,还确定了文件块在那个 DataNode 上的路径),管理客户端对文件的访问,配置副本策略(复制因子,可为某个文件单独设置),记录对文件系统命名空间或其属性的任何更改 DataNode:存储文件块(负责提供来自文件系统客户端的读写请求,还根据 NameNode 的指令执行块创建、删除和复制),上传至 HDFS 的文件在内部被分成一个或多个块,这些块存储在一组 DataNode 中
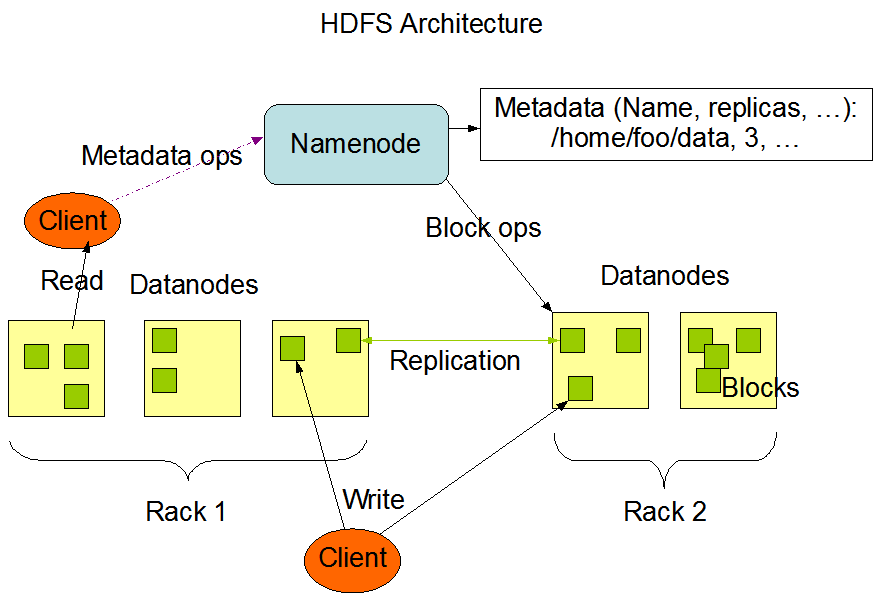
Client:
HDFS 客户端
1.文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
2.与NameNode交互,获取文件的位置信息
3.与DataNode交互,读取或者写入数据
4.Client提供一些命令来管理HDFS,比如NameNode格式化
5.Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作 Secondary NameNode:
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
1.辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
2.在紧急情兄下,可辅助恢复NameNode
HDFS 文件块大小设置
HDFS 中的文件在物理磁盘上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来设置
默认大小在Hadoop2.x版本中是128M,1.x中是64M,本地模式中是32M 寻址(查找Block位置)时间为传输时间的 1% 时,则为最佳状态。
目前磁盘的传输速率普遍为 100MB/s 假设 HDFS 寻址时间为 0.01 秒,那最佳块大小为:0.01 / 1% * 100M = 100M,实际有些偏差,所以 100M/s 的磁盘最佳为 128M 块的大小不能设置太小,也不能设置太大
1.块设置太小,会增加寻址时间,程序一直在找块的开始位置
2.块设置太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数居时,会非常慢 HDFS 块的大小设置主要取决于磁盘传输速率
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://blog.csdn.net/pear_zi/article/details/8082752
https://www.cnblogs.com/Dhouse/p/6901028.html
HDFS 概述的更多相关文章
- HDFS概述
HDFS概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS产出背景及定义 1>.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配 ...
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- HDFS概述和Shell操作
大数据技术之Hadoop(HDFS) 第一章 HDFS概述 HDFS组成架构 HDFS文件块大小 第二章 HDFS的Shell操作(开发重点) 1.基本语法 bin/hadoop fs 具体命令 ...
- HDFS概述(6)————用户手册
目的 本文档是使用Hadoop分布式文件系统(HDFS)作为Hadoop集群或独立通用分布式文件系统的一部分的用户的起点.虽然HDFS旨在在许多环境中"正常工作",但HDFS的工作 ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- HDFS概述(4)————HDFS权限
概述 Hadoop分布式文件系统(HDFS)的权限模型与POSIX模型的文件和目录权限模型一致.每个文件和目录与所有者和组相关联.该文件或目录将权限划分为所有者的权限,作为该组成员的其他用户的权限.以 ...
- HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群. 当前HDFS背景 HDFS主要有两层: 1.Namespace (1)包含目录,文件和块. (2)它支持所有命名空间相关的文 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- Hadoop之HDFS概述
一.HDFS产生背景及定义 1.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文 ...
随机推荐
- 蒟阵P3390 【模板】矩阵快速幂
代码如下: #include<iostream> #include<cstdio> #include<cstdlib> #include<cmath> ...
- 学习Android过程中遇到的未解决问题(个人笔记,细节补充,随时更新)
201811/13 使用HttpURLConnection对象调用方法又出现IO异常,我又百度个博客搜寻答案,未果.下午试试真机,完美.自己建了服务器tomcat,编写android访问自己tomca ...
- Sudoku POJ - 2676(DLX)
Sudoku Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 25356 Accepted: 11849 Specia ...
- 【XSY2753】Lcm 分治 FWT FFT 容斥
题目描述 给你\(n,k\),要你选一些互不相同的正整数,满足这些数的\(lcm\)为\(n\),且这些数的和为\(k\)的倍数. 求选择的方案数.对\(232792561\)取模. \(n\leq ...
- Mysql 语句优化
通过 show status 命令了解各个 sql 语句的执行频率格式:Mysql> show [session | global] status;注:session 表示当前连接global ...
- 关于360插件化Replugin Activity动态修改父类的字节码操作
近期在接入360插件化方案Replugin时,发现出现崩溃情况. 大概崩溃内容如下: aused by: java.lang.ClassNotFoundException: Didn't find c ...
- zabbix3.4.6之源码安装
LAMP部署环境搭建: Linux+apache(httpd)+mysql(mariadb)+php: 版本要求:apache-1.3.12,mysql-5.0.3,php-5.4.0<http ...
- 【BZOJ4832】抵制克苏恩(矩阵快速幂,动态规划)
[BZOJ4832]抵制克苏恩(矩阵快速幂,动态规划) 题面 BZOJ 题解 一模一样 #include<iostream> #include<cstdio> using na ...
- Codeforces 1076D Edge Deletion(最短路树)
题目链接:Edge Deletion 题意:给定一张n个顶点,m条边的带权无向图,已知从顶点1到各个顶点的最短路径为di,现要求保留最多k条边,使得从顶点1到各个顶点的最短距离为di的顶点最多.输出m ...
- 20165223 week2测试补交与总结
测试题二 题目: 在Ubuntu或Windows命令行中 建如下目录结构 Hello.java的内容见附件package isxxxx; (xxxx替换为你的四位学号) 编译运行Hello.java ...