Netty源码分析--内存模型(下)(十二)
这一节我们一起看下分配过程
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
PooledByteBuf<T> buf = newByteBuf(maxCapacity); // 初始化一块容量为 2^31 - 1的ByteBuf
allocate(cache, buf, reqCapacity); // reqCapacity = 1024 进入分配逻辑
return buf;
}
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity); // 对请求的大小进行校准,一会具体看
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize 判断校准之后的请求大小 是否小于 8k
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity); // 判断请求大小是否小于512B
if (tiny) { // < 512
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) { // 从缓存中进行分配,如果是第一次这里肯定是没有对应大小缓存的,除非之前有过释放,然后内存空间被缓存起来了。
// was able to allocate out of the cache so move on
return;
}
tableIdx = tinyIdx(normCapacity); // tiny数组中获取对应的下标
table = tinySubpagePools; // tiny subPage数组
} else { // 512 <= normCapacity < 8K
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) { // 一样从缓存中进行分配,这个上一节详细的介绍过
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity); // 获取small subPage数组下标
table = smallSubpagePools; // subPage 数组
}
final PoolSubpage<T> head = table[tableIdx];// 取得对应下标的subPage
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) { // 锁定防止其他操作修改head结点
final PoolSubpage<T> s = head.next;
if (s != head) {// 如果双向链表已经初始化,那么从subpage中进行分配
assert s.doNotDestroy && s.elemSize == normCapacity; // 断言确保 当前的这个subPage中的elemSize大小必须和校对后的请求大小一样
long handle = s.allocate(); // 从subPage中进行分配
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity); // 双向循环链表还没初始化,使用normal分配
}
incTinySmallAllocation(tiny);
return;
}
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
int normalizeCapacity(int reqCapacity) {
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
if (reqCapacity >= chunkSize) {
return directMemoryCacheAlignment == 0 ? reqCapacity : alignCapacity(reqCapacity);
}
if (!isTiny(reqCapacity)) { // 如果是 >=512 的内存申请,那么就规范到2的次方大小 ,比如 1000 就会 变成 1024,自己可以把这段位操作,自己main方法试一下。
// Doubled
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
assert directMemoryCacheAlignment == 0 || (normalizedCapacity & directMemoryCacheAlignmentMask) == 0;
return normalizedCapacity;
}
if (directMemoryCacheAlignment > 0) {
return alignCapacity(reqCapacity);
}
// Quantum-spaced
if ((reqCapacity & 15) == 0) { // 如果 < 512 判断如果是16的倍数,那么直接返回
return reqCapacity;
}
return (reqCapacity & ~15) + 16; // 如果不是则对齐成16的倍数
}
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
} // 先尝试从chunk链表中进行分配, 这里有一个需要注意的地方
// 分配顺序 先分配 q50 也就是 50% ~ 100% 的,然后是 q25 也就是 25% ~ 75% 的, 然后是 q000 0%~50% 、 qInit 0%~25% 、 q75 75% ~ 100%
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize); // 新建一个Chunk
long handle = c.allocate(normCapacity); // 内存分配
assert handle > 0;
c.initBuf(buf, handle, reqCapacity);
qInit.add(c); // 添加到初始化的chunk链表
}
上面的分配顺序,大家想一下为什么不是从q000开始分配呢?我找了一段分析的很好的。
在分析PoolChunkList的时候,我们知道一个chunk随着内存的不停释放,它本身会不停的往其所在的chunk list的prev list移动,直到其完全释放后被回收。 如果这里是从q000开始尝试分配,虽然分配的速度可能更快了(因为分配成功的几率更大),但一个chunk在使用率为25%以内时有更大几率再分配,也就是一个chunk被回收的几率大大降低了。这样就带来了一个问题,我们的应用在实际运行过程中会存在一个访问高峰期,这个时候内存的占用量会是平时的几倍,因此会多分配几倍的chunk出来,而等高峰期过去以后,由于chunk被回收的几率降低,内存回收的进度就会很慢(因为没被完全释放,所以无法回收),内存就存在很大的浪费。
为什么是从q050开始尝试分配呢,q050是内存占用50%~100%的chunk,猜测是希望能够提高整个应用的内存使用率,因为这样大部分情况下会使用q050的内存,这样在内存使用不是很多的情况下一些利用率低(<50%)的chunk慢慢就会淘汰出去,最终被回收。然而为什么不是从qinit中开始呢,这里的chunk利用率低,但又不会被回收,岂不是浪费?q075,q100由于使用率高,分配成功的几率也会更小,因此放到最后。
上面也有提到新建一个chunk,这里我想特殊说明两个byte数组,数组的大小是4096
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
循环之后的数组是怎么样子的呢?

MemoryMap存放分配信息,depthMap存放节点的高度信息 ;初始状态时,memoryMap和depthMap相等,depthMap的值初始化后不再改变,memoryMap的值则随着节点分配而改变。
下标代表了平衡二叉树的节点序号,值代表该节点的高度值。
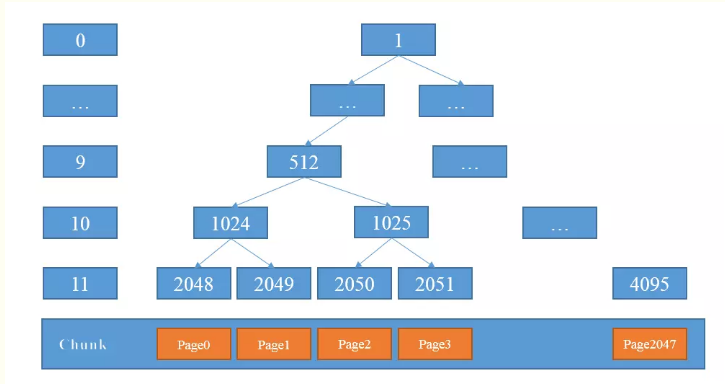
比如MemoryMap[1024] = 10, MemoryMap[2048] = 11. 好了,这个说完了,我们继续看:
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize >= 8K
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity); // < 8K
}
}
private long allocateSubpage(int normCapacity) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity); // 根据请求内存大小,获取下标,然后获取对应的subPage
synchronized (head) {
int d = maxOrder; // 最大层数 11
int id = allocateNode(d); // 分配节点,修改涉及节点层数, 具体看下面的分析
if (id < 0) { // 无可分配节点
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;// 16M(初始化值,后面会逐渐减少) - 8K
int subpageIdx = subpageIdx(id); // 2048 对应的偏移量是 0 , 2049 对应的偏移量是 1 。。。4095 对应偏移量是 2047
PoolSubpage<T> subpage = subpages[subpageIdx]; // 取对应下标的 subpage
if (subpage == null) {
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity); // 创建PoolSubpage
subpages[subpageIdx] = subpage;
// 新建或初始化subpage并加入到chunk的subpages数组,同时将subpage加入到arena的subpage双向链表中,最后完成分配请求的内存。
// 代码中,subpage != null的情况产生的原因是:subpage初始化后分配了内存,但一段时间后该subpage分配的内存释放并从arena的双向链表中删除,
// 此时subpage不为null,当再次请求分配时,只需要调用init()将其加入到areana的双向链表中即可。
} else {
subpage.init(head, normCapacity);
}
return subpage.allocate(); // 最后结果是一个long整数,其中低32位表示二叉树中的分配的节点,高32位表示subPage中分配的具体位置
}
}
修改节点对应的层数,底下这个方法涉及了很多的位运算,这里大家要仔细琢磨。
private int allocateNode(int d) { // d = 11
int id = 1;
int initial = - (1 << d); // -2048
byte val = value(id); // memoryMap[id] , 一般1对应的层数是 0 ,当第一个节点被分配完成后,这个节点的值会变成12
if (val > d) { // unusable // 如果分配完成,那么无法进行分配,那么就是 12 > 11 ,直接返回 -1
return -1;
}
while (val < d || (id & initial) == 0) { // id & initial == 1 << d for all ids at depth d, for < d it is 0
id <<= 1; // 左移1位
val = value(id); // 取到节点对应的层数
if (val > d) { // 如果当前的值大于层数,也就是说左子节点用完了
id ^= 1; // 当前节点值 +1 ,取右节点
val = value(id); // 取右子节点
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
setValue(id, unusable); // mark as unusable //将该节点的值设置为12,不可用
updateParentsAlloc(id); // 将该节点对应的所有父节点,层数全部 + 1
return id;
}
private void updateParentsAlloc(int id) {
while (id > 1) {
int parentId = id >>> 1; // 取父级节点
byte val1 = value(id); //
byte val2 = value(id ^ 1); // 如果 id = 2048 那么 id ^ 1 = 2049 , 如果 id = 2049 这里 id ^ 1 = 2048 这里一定要注意!!!
byte val = val1 < val2 ? val1 : val2;
setValue(parentId, val); // 修改父级对应层数
id = parentId;
}
}
上面这个方法很有意思,大家要仔细体会,我举个例子
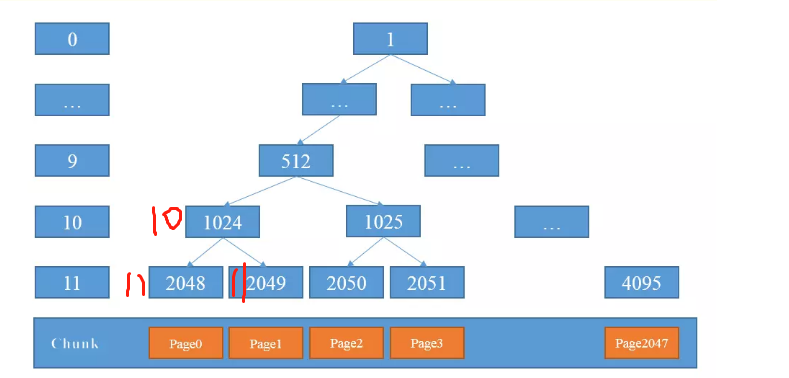
最开始是这样的,我们开始第一次分配,那么就是2048号节点,分配完成后会变成
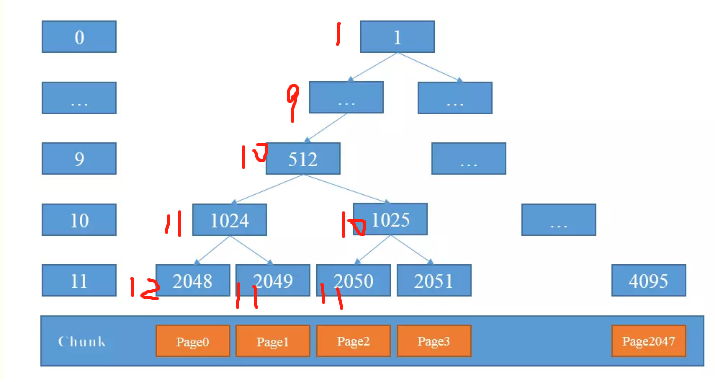
这时候由于2048变成了12,不可用状态,那么取右节点进行分配
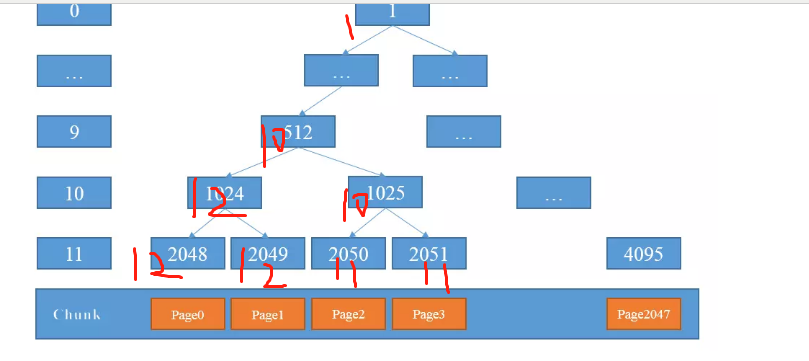
下一次再进行分配的时候, 发现 1024 是 12 ,那么取右子节点, 是 1025 = 10 ,因为 10 < 11 所以再次进入循环,找到2050节点,对应层数是 11 < 12 ,则分配 2050节点分配后变成
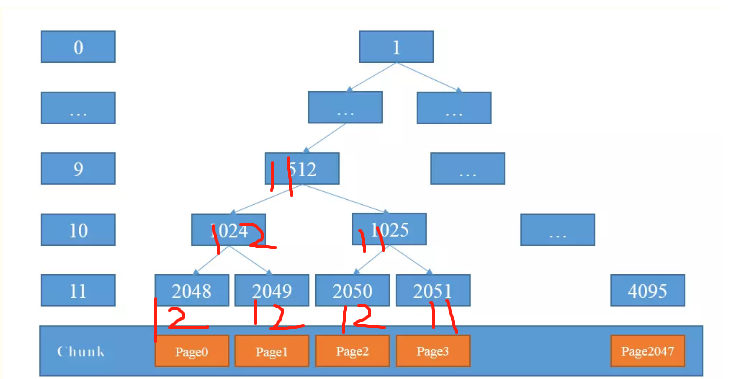
然后依次类推。
private long allocateRun(int normCapacity) {
int d = maxOrder - (log2(normCapacity) - pageShifts); // 计算满足需求的节点的高度 比如 16K , 那么 就是 d= 11 - (14 - 13) = 10
int id = allocateNode(d); // 从第十层找空闲节点, 原理跟上面相同,就不说了
if (id < 0) {
return id;
}
freeBytes -= runLength(id); // 分配后剩余的字节数
return id;
}
说到这里,内存模型的重点部分算是说完了。如果整个Netty系列有任何不对的地方,欢迎大家指出,我会虚心改正。
后面呢,我将打算将Spring的源码的关键部分进行分析,期间也会穿插着对Redis的底层数据结构等重要内容进行分析。有需要的童鞋们,记得关注我,随时可以获取最新的消息。
谢谢。
Netty源码分析--内存模型(下)(十二)的更多相关文章
- Netty源码分析--内存模型(上)(十一)
前两节我们分别看了FastThreadLocal和ThreadLocal的源码分析,并且在第八节的时候讲到了处理一个客户端的接入请求,一个客户端是接入进来的,是怎么注册到多路复用器上的.那么这一节我们 ...
- Netty源码分析--Reactor模型(二)
这一节和我一起开始正式的去研究Netty源码.在研究之前,我想先介绍一下Reactor模型. 我先分享两篇文献,大家可以自行下载学习. 链接:https://pan.baidu.com/s/1Uty ...
- element-ui MessageBox组件源码分析整理笔记(十二)
MessageBox组件源码,有添加部分注释 main.vue <template> <transition name="msgbox-fade"> < ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- netty源码分析(十八)Netty底层架构系统总结与应用实践
一个EventLoopGroup当中会包含一个或多个EventLoop. 一个EventLoop在它的整个生命周期当中都只会与唯一一个Thread进行绑定. 所有由EventLoop所处理的各种I/O ...
- Netty源码分析(前言, 概述及目录)
Netty源码分析(完整版) 前言 前段时间公司准备改造redis的客户端, 原生的客户端是阻塞式链接, 并且链接池初始化的链接数并不高, 高并发场景会有获取不到连接的尴尬, 所以考虑了用netty长 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析-- 处理客户端接入请求(八)
这一节我们来一起看下,一个客户端接入进来是什么情况.首先我们根据之前的分析,先启动服务端,然后打一个断点. 这个断点打在哪里呢?就是NioEventLoop上的select方法上. 然后我们启动一个客 ...
随机推荐
- Scratch3 二次开发系列
Scratch3.0来啦!!! Scratch做为图像化编程的首选语言,拖过积木块搭建实现动画游戏的制作.Scratch3添加了音乐.画笔.视频侦测.文字朗读.翻译等选择性下载扩展积木,可实现积 ...
- Bzoj 2058: [Usaco2010 Nov]Cow Photographs 题解
2058: [Usaco2010 Nov]Cow Photographs Time Limit: 3 Sec Memory Limit: 64 MBSubmit: 190 Solved: 104[ ...
- Dom4J的基本使用
初始化数据 <?xml version="1.0" encoding="UTF-8"?> <RESULT> <VALUE> ...
- request 中url拼接排序参数与签名算法
一.参数要求: { appId:应用在后台创建应用时分配的应用编号,与应用密钥一一对应 sign:按照当前请求参数名的字母序进行升序排列(排序时区分大小写,除sign外,其它值不为空的参数都参与签名) ...
- py+selenium一个可被调用的登录测试脚本【待优化】
大部分系统现在都有登录页面,本文主要尝试写一个登录的测试脚本,及另一个脚本调用它登录测试已登录的页面模块. 目标: 登录脚本:从excel里获取登录的测试数据(包括异常测试)→执行登录脚本→输出是否通 ...
- Sublime Text 3 实现C语言代码的编译和运行
Sublime Text 3 是一款优秀的代码编辑软件.界面简洁,轻巧快速,很受大家的欢迎. 最近开始用他来编辑数据结构的C语言代码,这就需要在新建编译系统.具体方法如下: 首先: 接下来是关键的一步 ...
- ybc云计算思维
YBC的云计算思维 计算机基础 一 计算机由5大单元组成 输入单元(鼠标 键盘) 存储单元(硬盘 内存) 逻辑单元(CPU) 控制单元(主板) 输出单元(显示器 音响 打印机) CPU CPU主要 ...
- 题解 P2949 【[USACO09OPEN]工作调度Work Scheduling】
P2949 [USACO09OPEN]工作调度Work Scheduling 题目标签是单调队列+dp,萌新太弱不会 明显的一道贪心题,考虑排序先做截止时间早的,但我们发现后面可能会出现价值更高却没有 ...
- [leetcode] 22. Generate Parentheses(medium)
原题 思路: 利用DFS,搜索每一种情况,同时先加"("后加")",保证()匹配正确. 最近开始学习前端,尝试用js来写. const generate = f ...
- tomcat启动成功但是没有监听8080端口
查看tomcat日志 cd tomcat/logs tailf -1000 catlina.out 错误如下: /home/work/jdk/jdk-10.0.1/jre/bin/java: No s ...