卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容。
程序的开头是导入TensorFlow:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
接下来载入MNIST数据集,并建立占位符。占位符x的含义为训练图像,y_为对应训练图像的标签。
# 读入数据
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# x为训练图像的占位符,y_为训练图像标签的占位符
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
运行后会在当前目录下得到一个名为MINST_data的数据集。如下图所示
由于使用的是卷积神经网络对图像进行分类,所以不能再使用784维的向量表示输入的x,而是将其还原为28*28的图片形式。[-1,28,28,1]中的-1表示形状第一维的大小是根据x自动确定的。
# 将单张图片从784维向量重新还原为28*28的矩阵图片
x_image = tf.reshape(x, [-1, 28, 28, 1])
x_image就是输入的训练图像,接下来,我们对训练图像进行卷积计算,第一层卷积的代码如下:
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial) def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial) def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 第一层卷积层
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
首先定义了四个函数,函数weight_variable可以返回一个给定形状的变量,并自动以截断正态分布初始化,bias_variable同样返回一个给定形状的变量,初始化所有值是0.1,可分别用这两个函数创建卷积的核(kernel)与偏置(bias)。h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)是真正进行卷积运算,卷积计算后选用ReLU作为激活函数。h_pool1 = max_pool_2x2(h_conv1)是调用函数max_pool_2x2进行一次池化操作。卷积、激活函数、池化,可以说是一个卷积层的“标配”,通常一个卷积层都会包含这三个步骤,有时也会去掉最后的池化操作。
对第一次卷积操作后产生的h_pool1再做一次卷积计算,使用的代码与上面类似。
# 第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
两层卷积层之后是全连接层:
# 全连接层,输出为1024维的向量
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 使用Dropout,keep_prob是一个占位符,训练时为0.5,测试时为1
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
在全连接层中加入了Dropout,它是防止神经网络过拟合的一种手段。在每一步训练时,以一定概率“去掉”网络中的某些连接,但这种去除不是永久性的,只是在当前步骤中去除,并且每一步去除的连接都是随机选择的。在这个程序中,选择的Dropout概率是0.5,也就是说训练时每一个连接都有50%的概率被去除。在测试时保留所有连接。
最后,再加入一层全连接,把上一步得到的h_fc1_drop转换为10个类别的打分。
# 把1024维的向量转换为10维,对应10个类别
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
y_conv相当于Softmax模型中的Logit,当然可以使用Softmax函数将其转换为10个类别的概率,再定义交叉熵损失。但其实TensorFlow提供了一个更直接的tf.nn.softmax_cross_entropy_with_logits函数,它可以直接对Logit定义交叉熵损失,写法为:
# 不采用先softmax再计算交叉熵的方法
# 而是采用tf.nn.softmax_cross_entropy_with_logits直接计算
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# 同样定义train_step
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
定义测试的准确率
# 定义测试的准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
在控制台显示在验证集上训练时模型的准确度,方便监控训练的进度,也可以据此来调整模型的参数。
# 创建Session,对变量初始化
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer()) # 训练20000步
for i in range(20000):
batch = mnist.train.next_batch(50)
# 每100步报告一次在验证集上的准确率
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0
})
print("step %d,training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
训练结束后,打印在全体测试集上的准确率:
# 训练结束后报告在测试集上的准确率
print("test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
}))
最后得到的结果在控制台显示为
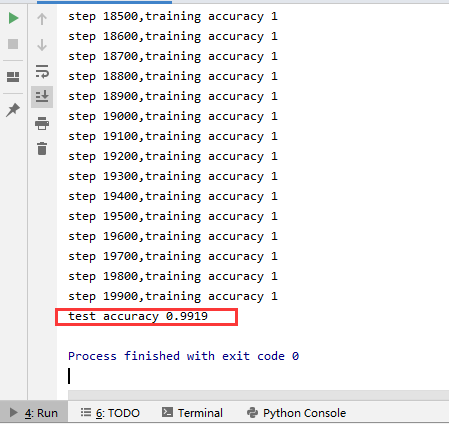
可以最终测试得到的准确率结果应该在99%左右。与Softmax回归模型相比,使用两层卷积的神经网络模型借助了卷积的威力,准确率有非常大的提升。
卷积神经网络CNN识别MNIST数据集的更多相关文章
- 如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP, ...
- 81、Tensorflow实现LeNet-5模型,多层卷积层,识别mnist数据集
''' Created on 2017年4月22日 @author: weizhen ''' import os import tensorflow as tf import numpy as np ...
- 卷积神经网络应用于MNIST数据集分类
先贴代码 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = inpu ...
- 基于MNIST数据的卷积神经网络CNN
基于tensorflow使用CNN识别MNIST 参数数量:第一个卷积层5x5x1x32=800个参数,第二个卷积层5x5x32x64=51200个参数,第三个全连接层7x7x64x1024=3211 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- Python实现bp神经网络识别MNIST数据集
title: "Python实现bp神经网络识别MNIST数据集" date: 2018-06-18T14:01:49+08:00 tags: [""] cat ...
- 写给程序员的机器学习入门 (八) - 卷积神经网络 (CNN) - 图片分类和验证码识别
这一篇将会介绍卷积神经网络 (CNN),CNN 模型非常适合用来进行图片相关的学习,例如图片分类和验证码识别,也可以配合其他模型实现 OCR. 使用 Python 处理图片 在具体介绍 CNN 之前, ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(二)
用Tensorflow实现卷积神经网络(CNN) 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10737065. ...
- RNN入门(一)识别MNIST数据集
RNN介绍 在读本文之前,读者应该对全连接神经网络(Fully Connected Neural Network, FCNN)和卷积神经网络( Convolutional Neural Netwo ...
随机推荐
- 天梯杯 L2-010. 排座位
L2-010. 排座位 时间限制 150 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位. ...
- hdu1255 覆盖的面积(线段树面积交)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1255 面积交与面积并相似相比回了面积并,面积交一定会有思路,当然就是cover标记大于等于两次时. 但 ...
- Increasing heap size while building the android source code on Ubuntu 15.10
http://stackoverflow.com/questions/34940793/increasing-heap-size-while-building-the-android-source-c ...
- Elasticsearch(5) --- Query查询和Filter查询
Elasticsearch(5) --- Query查询和Filter查询 这篇博客主要分为 :Query查询和Filter查询.有关复合查询.聚合查询也会单独写篇博客. 一.概念 1.概念 一个查询 ...
- python控制台简单实现五子棋
#棋盘#落子#规则import randomclass chess: def __init__(self): print('#---------------棋盘----------------#') ...
- Java web的基本概念
概念一直是学习计算机软件开发中经常遇到的问题,也是软件行业最喜欢创造的东西.很多时候,学习计算机软件开发遇到困难都是因为对某些概念的不理解,而不是因为技术本身有多么复杂.Java Web作为Java ...
- Go语言获取系统性能数据gopsutil库
psutil是一个跨平台进程和系统监控的Python库,而gopsutil是其Go语言版本的实现.本文介绍了它的基本使用. Go语言部署简单.性能好的特点非常适合做一些诸如采集系统信息和监控的服务,本 ...
- InnoDB在MySQL默认隔离级别下解决幻读
1.结论 在RR的隔离级别下,Innodb使用MVVC和next-key locks解决幻读,MVVC解决的是普通读(快照读)的幻读,next-key locks解决的是当前读情况下的幻读. 2.幻读 ...
- linux 操作系统级别监控 nmon命令
nmon是IBM公司开发的Linux性能监控工具,可以实时展示系统性能情况,也可以将监控数据写入文件中,并使用nmon分析器做数据展示 实时监控 命令 ./nmon c 代表CPU m 代表Memor ...
- linux 堆栈查看
top -c 查看进程ID pstree PID 查看线程树 pstack PID 查看堆栈