shell 队列实现线程并发控制
需求:并发检测1000台web服务器状态(或者并发为1000台web服务器分发文件等)如何用shell实现?
方案一:(这应该是大多数人都第一时间想到的方法吧)
思路:一个for循环1000次,顺序执行1000次任务。
#!/bin/bash
#
start_time=`date +%s` #定义脚本运行的开始时间
for ((i=;i<=;i++))
do
sleep #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i;
done
stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $stop_time - $start_time`"
运行结果:
[root@iZ94yyzmpgvZ ~]# ./test.sh
success1
success2
success3
success4
success5
success6
success7
........此处省略
success999
success1000
TIME:
代码解析以及问题:
一个for循环1000次相当于需要处理1000个任务,循环体用sleep 1代表运行一条命令需要的时间,用success$i来标示每条任务.
这样写的问题是,1000条命令都是顺序执行的,完全是阻塞时的运行,假如每条命令的运行时间是1秒的话,那么1000条命令的运行时间是1000秒,效率相当低,而我的要求是并发检测1000台web的存活,如果采用这种顺序的方式,那么假如我有1000台web,这时候第900台机器挂掉了,检测到这台机器状态所需要的时间就是900s,吃屎都吃不上热乎的。
所以,问题的关键集中在一点:如何并发
方案二:
思路:一个for循环1000次,循环体里面的每个任务都放入后台运行(在命令后面加&符号代表后台运行)。
实现:
#!/bin/bash
#
start=`date +%s` #定义脚本运行的开始时间
for ((i=;i<=;i++))
do
{
sleep #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i;
}& #用{}把循环体括起来,后加一个&符号,代表每次循环都把命令放入后台运行
#一旦放入后台,就意味着{}里面的命令交给操作系统的一个线程处理了
#循环了1000次,就有1000个&把任务放入后台,操作系统会并发1000个线程来处理
#这些任务
done
wait #wait命令的意思是,等待(wait命令)上面的命令(放入后台的)都执行完毕了再
#往下执行。
#在这里写wait是因为,一条命令一旦被放入后台后,这条任务就交给了操作系统
#shell脚本会继续往下运行(也就是说:shell脚本里面一旦碰到&符号就只管把它
#前面的命令放入后台就算完成任务了,具体执行交给操作系统去做,脚本会继续
#往下执行),所以要在这个位置加上wait命令,等待操作系统执行完所有后台命令
end=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $end - $start`"
运行结果:
[root@iZ94yyzmpgvZ /]# ./test1.sh
......
[] Done { sleep ; echo 'success'$i; }
[] Done { sleep ; echo 'success'$i; }
success992
[] Done { sleep ; echo 'success'$i; }
[] Done { sleep ; echo 'success'$i; }
success993
[] Done { sleep ; echo 'success'$i; }
success994
success995
[] Done { sleep ; echo 'success'$i; }
success996
[] Done { sleep ; echo 'success'$i; }
[] Done { sleep ; echo 'success'$i; }
success997
success998
[] Done { sleep ; echo 'success'$i; }
success999
[] Done { sleep ; echo 'success'$i; }
[]- Done { sleep ; echo 'success'$i; }
success1000
[]+ Done { sleep ; echo 'success'$i; }
TIME:
代码解析以及问题:
shell中实现并发,就是把循环体的命令用&符号放入后台运行,1000个任务就会并发1000个线程,运行时间2s,比起方案一的1000s,已经非常快了。
可以看到输出结果success4 ...success3完全都是无序的,因为大家都是后台运行的,这时候就是cpu随机运行了,所以并没有什么顺序
这样写确实可以实现并发,然后,大家可以想象一下,1000个任务就要并发1000个线程,这样对操作系统造成的压力非常大,它会随着并发任务数的增多,操作系统处理速度会变慢甚至出现其他不稳定因素,就好比你在对nginx调优后,你认为你的nginx理论上最大可以支持1w并发了,实际上呢,你的系统会随着高并发压力会不断攀升,处理速度会越来越慢(你以为你扛着500斤的东西你还能跑的跟原来一样快吗)
方案三:
思路:基于方案二,使用linux管道文件特性制作队列,控制线程数目
知识储备:
一、管道文件
1、无名管道(ps aux | grep nginx)
2、有名管道(mkfifo /tmp/fd1)
有名管道特性:
1)、cat /tmp/fd1(如果管道内容为空,则阻塞)
实验:
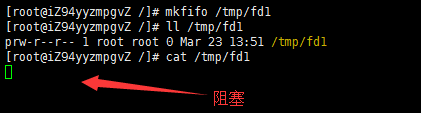
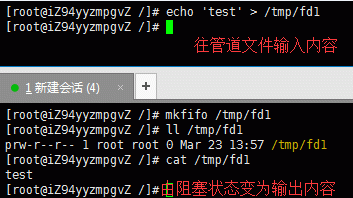
2)、echo "test" > /tmp/fd1(如果没有读管道的操作,则阻塞)
总结:利用有名管道的上述特性就可以实现一个队列控制了
你可以这样想:
一个女士公共厕所总共就10个蹲位,这个蹲位就是队列长度,女厕 所门口放着10把药匙,要想上厕所必须拿一把药匙,上完厕所后归还药匙,下一个人就可以拿药匙进去上厕所了,这样同时来了1千位美女上厕所,那前十个人抢到药匙进去上厕所了,后面的990人需要等一个人出来归还药匙才可以拿到药匙进去上厕所,这样10把药匙就实现了控制1000人上厕所的任务(os中称之为信号量)
二、文件描述符
1、管道具有存一个读一个,读完一个就少一个,没有则阻塞,放回的可以重复取,这正是队列
特性,但是问题是当往管道文件里面放入一段内容,没人取则会阻塞,这样你永远也没办法
往管道里面同时放入10段内容(想当与10把药匙),解决这个问题的关键就是文件描述符了。
2、mkfifo /tmp/fd1
创建有名管道文件exec 3<>/tmp/fd1,创建文件描述符3关联管道文件,这时候3这个文件描述符就拥有了管道的所有特性,还具有一个管道不具有的特性:无限存不阻塞,无限取不阻塞,而不用关心管道内是否为空,也不用关心是否有内容写入引用文件描述符: &3可以执行n次echo >&3 往管道里放入n把钥匙
exec命令用法:http://blog.sina.com.cn/s/blog_7099ca0b0100nby8.html
实现:
#!/bin/bash
#
start_time=`date +%s` #定义脚本运行的开始时间
[ -e /tmp/fd1 ] || mkfifo /tmp/fd1 #创建有名管道
exec <>/tmp/fd1 #创建文件描述符,以可读(<)可写(>)的方式关联管道文件,这时候文件描述符3就有了有名管道文件的所有特性
rm -rf /tmp/fd1 #关联后的文件描述符拥有管道文件的所有特性,所以这时候管道文件可以删除,我们留下文件描述符来用就可以了
for ((i=;i<=;i++))
do
echo >& #&3代表引用文件描述符3,这条命令代表往管道里面放入了一个"令牌"
done for ((i=;i<=;i++))
do
read -u3 #代表从管道中读取一个令牌
{
sleep #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i
echo >& #代表我这一次命令执行到最后,把令牌放回管道
}&
done
wait stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $stop_time - $start_time`"
exec <&- #关闭文件描述符的读
exec >&- #关闭文件描述符的写
运行结果:
[root@iZ94yyzmpgvZ /]# ./test2.sh
success4
success6
success7
success8
success9
success5
......
success935
success941
success942
......
success992
[] Done { sleep ; echo 'success'$i; echo >&; }
success993
[] Done { sleep ; echo 'success'$i; echo >&; }
success994
[] Done { sleep ; echo 'success'$i; echo >&; }
success998
success999
success1000
success997
success995
success996
[] Done { sleep ; echo 'success'$i; echo >&; }
TIME:
代码解析以及问题:
两个for循环,第一个for循环10次,相当于在女士公共厕所门口放了10把钥匙,第二个for循环1000次,相当于1000个人来上厕所,read -u3 相当于取走一把药匙,{} 里面最后一行代码 echo >&3 相当于上完厕所送还药匙。
这样就实现了10把药匙控制1000个任务的运行,运行时间为101s,肯定不如方案二快,但是比方案一已经快很多了,这就是队列控制同一时间只有最多10个线程的并发,既提高了效率,又实现了并发控制。
注意:创建一个文件描述符exec 3<>/tmp/fd1 不能有空格,代表文件描述符3有可读(<)可写(>)权限,注意,打开的时候可以写在一起,关闭的时候必须分开关,exec 3<&- 关闭读,exec 3>&- 关闭写
想一下:
1、假如一台优化后的nginx单机可以接受最大的并发是1w,那么同时来了2w人,那nginx是怎么做的
2、或者,一家餐厅有10个服务员,餐厅的资金的支持它最多可以再招收90个服务员(apache可设置默认开始10个进程,最大可开启100个进程),也就是说这家餐厅最多可以有100个服务员。那现在同时有1000个人来吃饭,这时候会出现的现象是:前10个人会立马有人招待吃饭,然后餐厅每招收一个新服务员就有一个人可以坐下来吃饭,好,假设现在总共有100个服务员在提供服务了,那么还剩下900人如何处理,很简单,吃完一个出去一个,出去一个就进来一个吃饭。这样就实现了100个服务员去为1000个人提供服务。
实际上就是用一个100人的队列去控制1000个任务的运行,同一时间最多并发100个线程,这样既节省了系统资源又提高了效率
原文:http://egon09.blog.51cto.com/9161406/1754317
shell 队列实现线程并发控制的更多相关文章
- shell队列实现线程并发控制(转)
需求:并发检测1000台web服务器状态(或者并发为1000台web服务器分发文件等)如何用shell实现? 方案一:(这应该是大多数人都第一时间想到的方法吧) 思路:一个for循环1000次,顺序执 ...
- 拆开Ceph看队列和线程
作者:吴香伟 发表于 2017/01/08 版权声明:可以任意转载,转载时务必以超链接形式标明文章原始出处和作者信息以及版权声明 我上小学时家离学校很远,家在某某山脚,学校在镇里.每周回家一趟,周五放 ...
- 自定义ThreadPoolExecutor带Queue缓冲队列的线程池 + JMeter模拟并发下单请求
.原文:https://blog.csdn.net/u011677147/article/details/80271174 拓展: https://github.com/jwpttcg66/GameT ...
- python队列、线程、进程、协程
目录: 一.queue 二.线程 基本使用 线程锁 自定义线程池 生产者消费者模型(队列) 三.进程 基本使用 进程锁 进程数据共享 默认数据不共享 queues array Manager.dict ...
- 6、TensorFlow基础(四)队列和线程
队列和线程 和 TensorFlow 中的其他组件一样,队列(queue)本身也是图中的一个节点,是一种有状态的节点,其他节点,如入队节点(enqueue)和出队节点(dequeue),可以修改它的内 ...
- python队列、线程、进程、协程(转)
原文地址: http://www.cnblogs.com/wangqiaomei/p/5682669.html 一.queue 二.线程 #基本使用 #线程锁 #自定义线程池 #生产者消费者模型(队列 ...
- 【Java并发】并发队列与线程池
并发队列 阻塞队列与非阻塞队 ConcurrentLinkedQueue BlockingQueue ArrayBlockingQueue LinkedBlockingQueue PriorityBl ...
- 多线程多进程学习threading,queue线程安全队列,线程间数据状态读取。threading.local() threading.RLock()
http://www.cnblogs.com/alex3714/articles/5230609.html python的多线程是通过上下文切换实现的,只能利用一核CPU,不适合CPU密集操作型任务, ...
- 我们一起来学Shell - shell的并发及并发控制
文章目录 bash的并发 未使用并发的脚本 简单修改 使用wait命令 控制并发进程的数量 文件描述符 查看当前进程打开的文件 自定义当前进程用描述符号操作文件 管道 我们一起来学Shell - 初识 ...
随机推荐
- forEach标签
1.forEach标签的简单使用: (1)未设置步长属性时,默认步长为1: <c:forEach "> <c:out value="${number}" ...
- 虚拟现实中自由步行(free-space walking)
之前我们讲到了虚拟现实中漫游方式的分类.虚拟现实中的漫游(travel/navigate)方式,即是应用提供给用户的,在虚拟环境中移动的方式.虚拟现实的漫游方式中,有一种被称为“完全动作线索”1,即用 ...
- 织梦DEDE分类信息实现联动筛选(支持多条件多级选项)解决方案
发布时间:2017-03-25 来源:未知 浏览:404 关键词: 很多织梦建站的站长在做产品列表页的时候,产品分类多而且都是关联的,用户不能快速的找到自己需要的东西,很多情况下都需要用到筛选功能,织 ...
- 解决mac OSX下安装git出现的"git命令需要使用开发者工具。您要现在安装该工具吗"(19款Mac)
1.本地安装Git ,这里不做说明 2.命令行执行 sudo mv /usr/bin/git /usr/bin/git-system 3.如果提示 权限不足,操作不被允许,关闭Rootless,重启按 ...
- Mac OS Catalina 如何删除自带的应用
在新推送的系统升级过后,(博主系统是Mac OS Mojave 10.14)我们会发现,之前我们删除的令人讨厌的Mac自带应用又回来了,如果我们还按照之前百度的方式删除的话,参考: https://w ...
- 快学Scala 第十六课 (shell调用,正则表达式,正则表达式组,stripMargin妙用)
shell调用:(管道符前加#号,执行shell用!) import sys.process._ "ls -al" #| "grep x" ! 正则表达式:(r ...
- PHP 通过 ReflectionMethod 反射类方法获取注释返回 false 的问题解决
php 通过反射 ReflectionMethod 类来获取类方法的相关信息,其中就包含方法的注释内容. 问题描述 在公司测试环境运行以下代码,如果是 cli 命令行模式运行,正常输出代码注释.如果是 ...
- postman常用断言
1.Code is 200 断言状态码是200 2.contains string 断言respoonse body中包含string 3.json value check (检查JSON值)
- JavaScript实现百度搜索页面
JavaScript实现百度搜索页面 HTML <!DOCTYPE html> <html> <head> <meta charset="UTF-8 ...
- Hash Table Implementation in C++
对于字符串,所用的hash函数为: size_t _Hash_bytes(const void* ptr, size_t len, size_t seed) { static const size_t ...