MySQL 语句执行过程详解
MySQL 原理篇
当客户端向 MySQL 发送一个请求的时候,MySQL 的执行过程如下图所示:
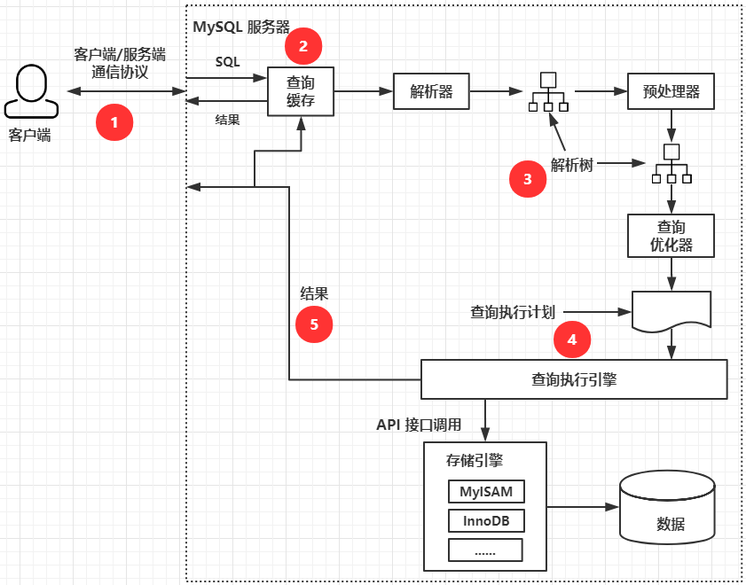
MySQL 客户端/服务端通信
通信机制
MySQL 客户端与服务端的通信方式是 “ 半双工 ”。
- 全双工:双向通信,发送同时也可以接收
- 半双工:双向通信,同时只能接收或者是发送,无法同时做操作
- 单工:只能单一方向传送
一旦一端开始发送消息,另一端要接收完整个消息才能响应它,所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置 max_allowed_packet 参数。
但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
与之相反的是,服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。
因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用 SELECT * 以及加上 LIMIT 限制的原因之一。
连接状态
对于一个 MySQL 的连接,或者说一个线程,时刻都有一个状态来标识这个连接正在做什么。
可以通过如下命令来查看连接的状态:
show full processlist
show processlist
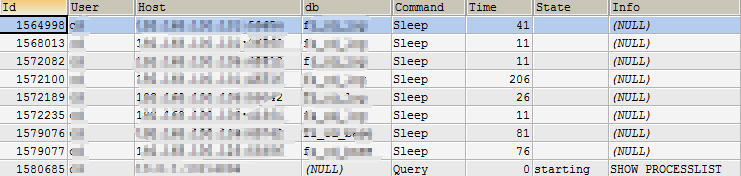
详细的状态集描述参考官网:https://dev.mysql.com/doc/refman/5.7/en/general-thread-states.html
这里简单介绍几个常用的连接状态:
- Sleep:线程正在等待客户端发送数据
- Query:连接线程正在执行查询
- Locked:线程正在等待表锁的释放
- Sorting result:线程正在对结果进行排序
- Sending data:向请求端返回数据
对于出现问题的连接可以通过 kill {id} 的方式进行杀掉。
查询缓存
工作原理:
- 缓存 SELECT 操作的结果集和 SQL 语句。
- 新的 SELECT 语句,先去查询缓存,判断是否存在可用的记录集,需要注意的是在判断的时候,要求 SQL 语句完全一样(SQL 两端允许存在空格)才会匹配到缓存数据。
缓存参数
MySQL 的缓存参数在配置文件中设置,可以通过如下命令来查看缓存的参数:
show variables like 'query_cache%'

- query_cache_type
- 0:不启用查询缓存,默认值
- 1:启用查询缓存,只要符合查询缓存的要求,客户端的查询语句和记录集都可以缓存起来,供其他客户端使用,SQL 语句中加上 SQL_NO_CACHE 将不缓存
- 2:启用查询缓存,只要查询语句中添加了参数:SQL_CACHE,且符合查询缓存的要求,客户端的查询语句和记录集,则可以缓存起来,供其他客户端使用
- query_cache_size
- 总的缓存池的大小,允许设置 query_cache_size 的值最小为40K,默认1M,推荐设置为64M/128M
- 当总的缓存池大小超过设置的值时,会按照时间顺序,让最老的缓存失效
- query_cache_limit
- 指定单个查询能够使用的缓冲区大小,默认设置为1M
缓存执行情况
可以通过如下命令来查看缓存情况:
show status like 'Qcache%'

- Qcache_free_blocks
- Query Cache 中目前还有多少剩余的 blocks。如果该值显示较大,则说明 Query Cache 中的内存碎片较多了,可能需要寻找合适的机会进行整理
- Qcache_free_memory
- Query Cache 中目前剩余的内存大小。通过这个参数我们可以较为准确的观察出当前系统中的Query Cache 内存大小是否足够,是需要增加还是过多了
- Qcache_hits
- 缓存命中次数。通过这个参数我们可以查看到 Query Cache 的基本效果
- Qcache_inserts
- 插入缓存的记录数,通过 Qcache_hits 和 Qcache_inserts 两个参数我们就可以算出 Query Cache 的命中率,Query Cache 命中率 = Qcache_hits / ( Qcache_hits + Qcache_inserts )
- Qcache_lowmem_prunes
- 多少条 Query 因为内存不足而被清除出 Query Cache。通过 Qcache_lowmem_prunes 和 Qcache_free_memory 相互结合,能够更清楚的了解到我们系统中 Query Cache 的内存大小是否真的足够,是否经常出现因为内存不足而有 Query 被清除
- Qcache_not_cached
- 因为 query_cache_type 的设置或者不能被 cache 的 Query 的数量
- Qcache_queries_in_cache
- 当前 Query Cache 中 cache 的 Query 数量
- Qcache_total_blocks
- 当前 Query Cache 中的 block 数量
不会缓存的情况
- 当查询语句中设置了 SQL_NO_CACHE,则不会被缓存。
- 当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数 NOW() ,CURRENT_DATE() 等类似的函数,或者用户自定义的函数,存储函数,用户变量等都不会被缓存。
- 当查询的结果大于 query_cache_limit 设置的值时,结果不会被缓存。
- 对于 InnoDB 引擎来说,当一个语句在事务中修改了某个表,那么在这个事务提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务,会大大降低缓存命中率。
- 查询的表是系统表。
- 查询语句不涉及到表。
缓存有哪些坑?
- 在查询之前必须先检查是否命中缓存,浪费计算资源。
- 如果这个查询可以被缓存,那么执行完成后,MySQL 发现查询缓存中没有这个查询,则会将结果存入查询缓存,这会带来额外的系统消耗。
- 针对表进行写入或更新数据时,将对应表的所有缓存都设置失效。
- 如果查询缓存很大或者碎片很多时,这个操作可能带来很大的系统消耗。
适用场景
以读为主的业务,数据生成 之后就不常改变的业务,比如门户类、新闻类、报表类、论坛类。
查询优化处理
查询优化处理的三个阶段
- 解析 SQL
- 通过 lex 语法分析,yacc 语法分析将 SQL 语句解析成解析树。
- lex、yacc 语法参考:https://www.ibm.com/developerworks/cn/linux/sdk/lex/
- 预处理阶段
- 根据 MySQL 的语法的规则进一步检查解析树的合法性,如:检查数据的表和列是否存在,解析名字和别名的设置。还会进行权限的验证
- 查询优化器
- 优化器的主要作用就是找到最优的执行计划
查询优化器如何找到最优执行计划
这里介绍几种优化方式,更多的可以参考《高性能MySQL_第3版(中文)》
- 使用等价变化规则
- 5 = 5 and a > 5 改写成 a > 5
- a < b and a = 5 改写成 b > 5 and a = 5
- 基于联合索引,调整条件位置等
- 优化 count、min、max 等函数
- InnoDB 引擎 min 函数只需找索引最左边
- InnoDB 引擎 max 函数只需找索引最右边
- MyISAM 引擎 count(*),不需要计算,直接返回
- 覆盖索引扫描
- 子查询优化
select * from (select * from user where id = 1) as t;,会被优化成一级查询
- 提前终止查询
- 用了 limit 关键字或者使用不存在的条件,获取到 limit 所需要的数据后,就不再遍历接下来的数据
- IN 的优化
- MySQL 对于 IN 的查询,会先进性排序,再采用二分查找的方式查找数据
- 比如表中的数据是 1,2,3,4,5,where 条件是 id IN(2,1,3),在进行 IN 操作的时候,会先对 IN 中的数据排序,变成 1,2,3,然后取出一条数据1先和2比较,1<2,则往2的左边查找,进而找到1,接下来就是再获取一条数据重复上面的查找步骤。
- 其他关系型数据库不会采用二分查找的方式,而是和 or 的方式一样,where id=1 or id=2 or id=3,从表中获取一条数据和 where 条件中的 or 的数据一个一个比对。
MySQL 的查询优化器是基于成本计算的原则,它会尝试各种执行计划,数据抽样的方式进行试验(随机的读取一个 4K 的数据块进行分析)。
执行计划
这块内容比较多,后面会单独提供一篇文章描述
查询执行引擎
调用插件式的存储引擎的原子 API 进行执行计划的执行。
返回客户端
- 有需要做缓存的,执行缓存操作
- 增量的返回执行结果,开始生成第一条结果时,MySQL 就开始往请求方逐步返回数据,这样做的好处是 MySQL 服务器无须保存过多的数据,浪费内存,用户体验好,马上就拿到了数据
参考
MySQL 语句执行过程详解的更多相关文章
- [转]MySQL查询语句执行过程详解
Mysql查询语句执行原理 数据库查询语句如何执行?语法分析:首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树.语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是 ...
- SQL语句执行过程详解
一.SQL语句执行原理: 第一步:客户端把语句发给服务器端执行 当我们在客户端执行select语句时, 客户端会把这条SQL语句发送给服务器端,让服务器端的进程来处理这语句.也就是说,Oracle客户 ...
- mysql中SQL执行过程详解与用于预处理语句的SQL语法
mysql中SQL执行过程详解 客户端发送一条查询给服务器: 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器段进行SQL解析.预处理,在优化器生成对应的 ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- ping命令执行过程详解
[TOC] ping命令执行过程详解 机器A ping 机器B 同一网段 ping通知系统建立一个固定格式的ICMP请求数据包 ICMP协议打包这个数据包和机器B的IP地址转交给IP协议层(一组后台运 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- mysql系列九、mysql语句执行过程及运行原理(分组查询和关联查询原理)
一.背景介绍 了解一个sql语句的执行过程,了解一部分都做了什么,更有利于对sql进行优化,因为你知道它的每一个连接.where.分组.子查询是怎么运行的,都干了什么,才会知道怎么写是不合理的. 大致 ...
随机推荐
- web前端之浏览器: 知识汇总
一.URL到页面 准备阶段: 输入URL,Enter进入查找 浏览器在本地查找host文件,匹配对应的IP: 找到返回浏览器并缓存 没有,则进入路由查找: 找到返回浏览器并缓存 再没有,再进入公网DN ...
- Egret资源跨域问题
在服务器上配置了允许跨域还不够,还需要在引擎配置允许跨域,不然texture无法在webgl上下文中渲染 会报一个类似于The cross-origin image at 的错误, 只需要在egret ...
- MySQL8安装及使用当中的一些注意事项
前言 这两天构建新项目,在本地安装的mysql8(本地环境windows),期间忘了密码,又卸载重装了一番,然后捣鼓了一顿授权给别人访问,最后磕磕绊绊的搞好了,下面是在这过程中遇到的问题及解决办法小结 ...
- LeetCode初级算法--数组02:旋转数组
LeetCode初级算法--数组02:旋转数组 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/ ...
- 从源码角度看JedisPoolConfig参数配置
做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 你好,JedisPoolConfig Java中使用Jedis作为连接Redis的工具.在使用Jedis的也可以配置Jed ...
- AlexNet网络
AlexNet 中包含了比较新的技术点,首次在CNN中成功应用了 ReLu .Dropout和LRN等Trick. 1.成功使用了Relu作为CNN的激活函数,并验证其效果在较深的网络中超过了Sigm ...
- [Quarks PwDump]Hash dump神器
好不好用就不用说了哈 记录下使用方式 也支持导出本地哈希.域控哈希等.配合hashcat神器 奇效. 它目前可以导出 : – Local accounts NT/LM hashes +history ...
- spring源码系列7:Spring中的InstantiationAwareBeanPostProcessor和BeanPostProcessor的区别
概念 Bean创建过程中的"实例化"与"初始化"名词 实例化(Instantiation): 要生成对象, 对象还未生成. 初始化(Initialization ...
- [CODEVS1537] 血色先锋队 - BFS
题目描述 Description 巫妖王的天灾军团终于卷土重来,血色十字军组织了一支先锋军前往诺森德大陆对抗天灾军团,以及一切沾有亡灵气息的生物.孤立于联盟和部落的血色先锋军很快就遭到了天灾军团的重重 ...
- libevent::事件::定时器
#include <cstdio> #include <errno.h> #include <sys/types.h> #include <event.h&g ...