Python用python-docx读写word文档
python-docx库可用于创建和编辑Microsoft Word(.docx)文件。
官方文档:https://python-docx.readthedocs.io/en/latest/index.html
备注:
doc是微软的专有的文件格式,docx是Microsoft Office2007之后版本使用,其基于Office Open XML标准的压缩文件格式,比
doc文件所占用空间更小。docx格式的文件本质上是一个ZIP文件,所以其实也可以把.docx文件直接改成.zip,解压后,里面的
word/document.xml包含了Word文档的大部分内容,图片文件则保存在word/media里面。
python-docx不支持.doc文件,间接解决方法是在代码里面先把.doc转为.docx。
一、安装包
pip3 install python-docx
二、创建word文档
下面是在官文示例基础上对个别地方稍微修改,并加上函数的使用说明
from docx import Document
from docx.shared import Inches document = Document() #添加标题,并设置级别,范围:0 至 9,默认为1
document.add_heading('Document Title', 0) #添加段落,文本可以包含制表符(\t)、换行符(\n)或回车符(\r)等
p = document.add_paragraph('A plain paragraph having some ')
#在段落后面追加文本,并可设置样式
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote') #添加项目列表(前面一个小圆点)
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph('second item in unordered list', style='List Bullet') #添加项目列表(前面数字)
document.add_paragraph('first item in ordered list', style='List Number')
document.add_paragraph('second item in ordered list', style='List Number') #添加图片
document.add_picture('monty-truth.png', width=Inches(1.25)) records = (
(3, '', 'Spam'),
(7, '', 'Eggs'),
(4, '', 'Spam, spam, eggs, and spam')
) #添加表格:一行三列
# 表格样式参数可选:
# Normal Table
# Table Grid
# Light Shading、 Light Shading Accent 1 至 Light Shading Accent 6
# Light List、Light List Accent 1 至 Light List Accent 6
# Light Grid、Light Grid Accent 1 至 Light Grid Accent 6
# 太多了其它省略...
table = document.add_table(rows=1, cols=3, style='Light Shading Accent 2')
#获取第一行的单元格列表
hdr_cells = table.rows[0].cells
#下面三行设置上面第一行的三个单元格的文本值
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
#表格添加行,并返回行所在的单元格列表
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc document.add_page_break() #保存.docx文档
document.save('demo.docx')
创建的demo.docx内容如下:
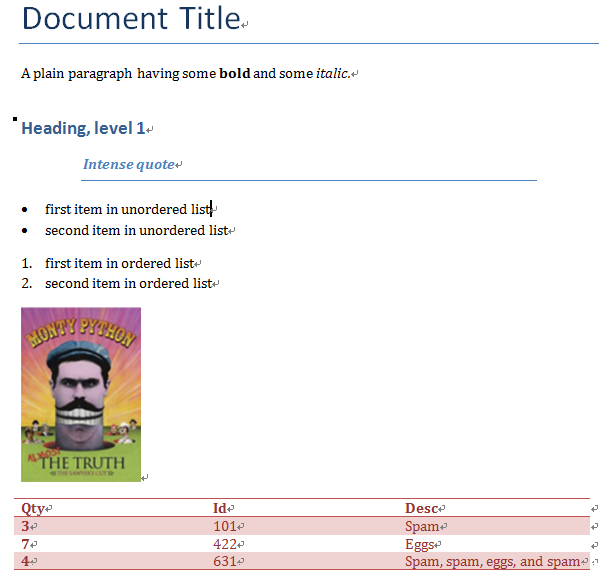
三、读取word文档
from docx import Document
doc = Document('demo.docx')
#每一段的内容
for para in doc.paragraphs:
print(para.text)
#每一段的编号、内容
for i in range(len(doc.paragraphs)):
print(str(i), doc.paragraphs[i].text)
#表格
tbs = doc.tables
for tb in tbs:
#行
for row in tb.rows:
#列
for cell in row.cells:
print(cell.text)
#也可以用下面方法
'''text = ''
for p in cell.paragraphs:
text += p.text
print(text)'''
运行结果:
Document Title
A plain paragraph having some bold and some italic.
Heading, level 1
Intense quote
first item in unordered list
second item in unordered list
first item in ordered list
second item in ordered list 0 Document Title
1 A plain paragraph having some bold and some italic.
2 Heading, level 1
3 Intense quote
4 first item in unordered list
5 second item in unordered list
6 first item in ordered list
7 second item in ordered list
8
9 Qty
Id
Desc
3
101
Spam
7
422
Eggs
4
631
Spam, spam, eggs, and spam
[Finished in 0.2s]
Python用python-docx读写word文档的更多相关文章
- C#开源组件DocX处理Word文档基本操作(二)
上一篇 C#开源组件DocX处理Word文档基本操作(一) 介绍了DocX的段落.表格及图片的处理,本篇介绍页眉页脚的处理. 示例代码所用DocX版本为:1.3.0.0.关于版本的区别,请参见上篇,而 ...
- python 使用win32com实现对word文档批量替换页眉页脚
最近由于工作需要,需要将70个word文件的页眉页脚全部进行修改,在想到这个无聊/重复/没有任何技术含量的工作时,我的内心是相当奔溃的.就在我接近奔溃的时候我突然想到完全可以用python脚本来实现这 ...
- $用python-docx模块读写word文档
工作中会遇到需要读取一个有几百页的word文档并从中整理出一些信息的需求,比如产品的API文档一般是word格式的.几百页的文档,如果手工一个个去处理,几乎是不可能的事情.这时就要找一个库写脚本去实现 ...
- 利用Python-docx 读写 Word 文档中的正文、表格、段落、字体等
前言: 前两篇博客介绍了 Python 的 docx 模块对 Word 文档的写操作,这篇博客将介绍如何用 docx 模块读取已有 Word 文档中的信息. 本篇博客主要内容有: 1.获取文档的章节信 ...
- C#使用Docx操作word文档
C#使用Docx编写word表格 最近接手了一个小Demo,要求使用Docx,将Xml文件中的数据转换为word文档,组织数据形成表格. 写了已经一周,网络上的知识太零碎,就想自己先统计整理出来,方便 ...
- Docx 生成word文档二
/// <summary> /// 生产word 文档 /// </summary> public class GenerateWord { /// <summary&g ...
- Docx 生成word文档
1.生成word代码 /// <summary> /// 生成word文档 /// </summary> /// <param name="tempPath&q ...
- C#开源组件DocX处理Word文档基本操作(一)
C#中处理Word文档,是大部分程序猿绕不过的一道门.小公司或一般人员会选择使用开源组件.目前网络上出现的帖子,大部分是NPOI与DocX,其它的也有.不啰嗦了,将要使用DocX的基本方法贴出来,供参 ...
- BCB 读写Word文档
void __fastcall TForm1::btn1Click(TObject *Sender) { Variant WordApp,WordDocs,WordDoc; Variant word_ ...
随机推荐
- Selenium(十五):unittest单元测试框架(一) 初识unittest
1. 认识unittest 什么是单元测试?单元测试负责对最小的软件设计单元(模块)进行验证,它使用软件设计文档中对模块的描述作为指南,对重要的程序分支进行测试以发现模块中的错误.在python语言下 ...
- TypeScript 学习笔记(四)
函数: 1.函数是一组一起执行一个任务的语句 2.我们可以把一段可复用的代码放到一起组成函数,从而提高效率 3.函数声明(通过关键字 function 来声明)告诉编译器函数的名称.返回类型和参数 4 ...
- 国内Maven仓库--阿里云Aliyun仓库地址及设置
aliyun Maven:http://maven.aliyun.com/nexus/#view-repositories 需要使用的话,要在maven的settings.xml 文 ...
- python字典中列表追加数据
dict = {} for i in range(1, 6): if i not in dict: dict[i] = [] for j in range(101, 106): dict[i].app ...
- 解决Flask和Django的错误“TypeError: 'bool' object is not callable”
跟着欢迎进入Flask大型教程项目!的教程学习Flask,到了重构用户模型的时候,运行脚本后报错: TypeError: 'bool' object is not callable 这是用户模型: c ...
- MySQL 锁的监控及处理
故障模拟 # 添加两项配置 vi /etc/my.cnf [mysqld] autocommit=0 innodb_lock_wait_timeout = 3600 systemctl restart ...
- HDL的三种描述方式
结构化描述 结构化描述方式是最原始的描述方式,是抽象级别最低的描述方式,但同时也是最接近于实际的硬件结构的描述方式.结构化的描述方式,思路就像在面包板上搭建数字电路一样,唯一的不同点就是我们通过HDL ...
- linux,xshell命令
一. linux 1.Linux发行版 <1> 常见的发行版本如下: Ubuntu Redhat Fedora openSUSE Linux Mint Debian Manjaro M ...
- 通过ES6 Module看import和require区别
前言 说到import和require,大家平时开发中一定不少见,尤其是需要前端工程化的项目现在都已经离不开node了,在node环境下这两者都是大量存在的,大体上来说他们都是为了实现JS代码的模块化 ...
- selenium三大切换的骚操作之显性等待
一.handle窗口切换 当点击某个元素后,会重新生成一个新的页签,但此时我们的操作仍然在原先的窗口当中,如果要在新的窗口继续操作元素,那么就要用到handle窗口切换的方法. 常用方法: windo ...