概率分布的python实现
接上篇概率分布,这篇文章讲概率分布在python的实现。
文中的公式使用LaTex语法,即在\begin{equation}至\end{equation}的内容可以在https://www.codecogs.com/latex/eqneditor.php?lang=zh-cn页面转换出
正确的格式
二项分布(Binomial Distribution)
包含n个相同的试验
每次试验只有两个可能的结果:“成功”或“失败”。
出现成功的概率p对每一次试验是相同的,失败的概率q也是如此,且p+q=1。
试验是互相独立的。
试验成功或失败可以计数,即试验结果对应于一个离散型随机变量。
以X表示n次重复独立试验中事件A(成功)出现的次数,则
\begin{equation}
P{X=x}=C_{n}^{x} p^{x} q^{n-x}, \quad x=0,1,2, \cdots, n
\end{equation}
在python中,可以使用scipy.stats模块中的binom.rvs()方法生成符合二项分布的离散随机变量。该方法的参数n表示n次重复独立试验,p表示事件A出现的次数。size表示做多少次二项分布试验。
同时,本文中使用seaborn的distplot方法绘制随机变量分布的直方图。在大数据量的试验下,通过随机变量出现的频率除以试验的次数,可以得到特定离散随机变量出现的概率。
from scipy.stats import binom
import seaborn as sns
data_binom = binom.rvs(n=10,p=0.5,size=10000)
ax = sns.distplot(data_binom,
kde=False,
color='green',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Binomial Distribution', ylabel='Frequency')
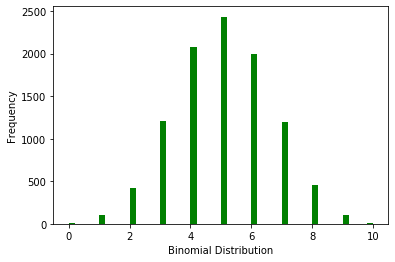
# 可以打印随机变量的值,按照定义,其值为出现A事件的次数,范围肯定在[0,1]
print(data_binom)
[2 3 6 ... 5 4 3]
以抛硬币试验解析上图,得出连续抛10次硬币,5次为正面的概率最高,概率趋近于2500/10000=25%。
贝努里分布(Bernoulli Distribution)
贝努里分布为特殊的二项分布,即每次执行一次试验(n=1),然后获取单次试验的随机变量的值,为0或1。所以贝努里分布也被称为0-1分布。其分布函数为:
\begin{equation}
P{X=x}=p^{x} q^{1-x}, \quad x=0,1
\end{equation}
在python中,可以使用scipy.stats模块中的bernoulli.rvs()方法生成符合二项分布的离散随机变量。其它参数同二项分布。
from scipy.stats import bernoulli
data_bern = bernoulli.rvs(size=10000,p=0.5)
ax= sns.distplot(data_bern,
kde=False,
color="green",
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Bernoulli Distribution', ylabel='Frequency')

以抛硬币试验解析上图,得出正面和反面出现的概率,趋近于5000/10000=50%。
几何分布(Geometric distribution)
几何分布是指在n次贝努里试验中,经过k次获得1次成功的概率。
几何分布的特点:
(1)进行一系列相互独立的试验;
(2)每一次试验既有成功的可能,也有失败的可能,且单次试验的成功概率相同;
(3)主要是为了取得第一次成功需要进行多少次试验。
其分布函数为:
\begin{equation}
P{X=k}=p (1-p)^{k-1}, \quad k \geqslant 1
\end{equation}
在python中,可以使用scipy.stats模块中的geom.rvs()方法得出几何分布的离散随机变量。
from scipy.stats import geom
data_geom = geom.rvs(size=10000,p=0.5)
ax= sns.distplot(data_geom,
kde=False,
color="green",
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Geometric Distribution', ylabel='Frequency')
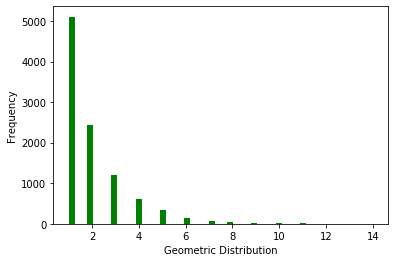
泊松分布(Poisson distribution)
泊松分布是用来描述在一指定时间范围内或在指定的面积或体积之内某一事件出现的次数的分布,例如某企业每月发生事故的次数。
泊松分布的公式为:
\begin{equation}
P(X)=\frac{\lambda^{x} \mathrm{e}^{-\lambda}}{x !}, \quad x=0,1,2, \cdots
\end{equation}
式中,\(\lambda\)为给定的时间间隔内事件的平均数。
在python中,可以使用scipy.stats模块中的poisson.rvs()方法得出泊松分布的连续随机变量。其中参数mu即为公式中的\(\lambda\),其它参数同上文方法。
from scipy.stats import poisson
data_poisson = poisson.rvs(mu=3, size=10000)
ax = sns.distplot(data_poisson,
bins=30,
kde=False,
color="green",
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Poisson Distribution', ylabel='Frequency')
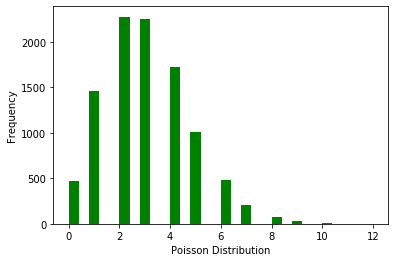
正态分布(Normal Distribution)
在连续型随机变量中,最重要的一种随机变量是具有钟形概率分布的随机变量。人们称它为正态随机变量,相应的概率分布称为正态分布。
如果随机变量X的概率密度为:
\begin{equation}
f(x)=\frac{1}{\sigma \sqrt{2 \pi}} \mathrm{e}^{-\frac{1}{2 \sigma{2}}(x-\mu){2}}, \quad-\infty<x<+\infty
\end{equation}
则称X服从正态分布,记作\(X \sim N\left(\mu, \sigma^{2}\right)\),其中,\(-\infty< \mu <+\infty\),\(\sigma > 0\), \(\mu\)为随机变量X的均值,\(\sigma\)为随机变量X的标准差,它们是正态分布的两个参数。
在python中,可以使用scipy.stats模块中的norm.rvs()方法产生符合二项分布的连续随机变量。其中参数loc代表随机变量的均值,size变量代表随机变量的标准差。
from scipy.stats import norm
# 生成标准正态分布,N(0,1)
data_normal = norm.rvs(size=10000,loc=0,scale=1)
ax = sns.distplot(data_normal,
bins=100,
kde=True,
color="green",
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Normal Distribution', ylabel='Frequency')
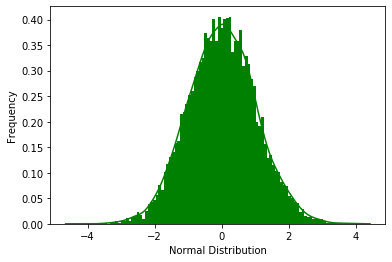
总结
本文通过scipy.stats包中的随机分布函数rvs方法(Random variates),执行10000次随机变量的计算,通过随机变量值个数直方图的绘制得出特定分布的图形。
另外,也可以通过随机分布函数的pmf方法直接获得指定参数下的概率值,然后画出参数与概率的对应关系,但在本文中不做展开。
欢迎扫描二维码关注公众号

概率分布的python实现的更多相关文章
- 数据科学中的常见的6种概率分布(Python实现)
作者:Pier Paolo Ippolito@南安普敦大学 编译:机器学习算法与Python实战(微信公众号:tjxj666) 原文:https://towardsdatascience.com/pr ...
- 关于使用scipy.stats.lognorm来模拟对数正态分布的误区
lognorm方法的参数容易把人搞蒙.例如lognorm.rvs(s, loc=0, scale=1, size=1)中的参数s,loc,scale, 要记住:loc和scale并不是我们通常理解的对 ...
- 如何在Python中实现这五类强大的概率分布
R编程语言已经成为统计分析中的事实标准.但在这篇文章中,我将告诉你在Python中实现统计学概念会是如此容易.我要使用Python实现一些离散和连续的概率分布.虽然我不会讨论这些分布的数学细节,但我会 ...
- 概率分布之间的距离度量以及python实现(四)
1.f 散度(f-divergence) KL-divergence 的坏处在于它是无界的.事实上KL-divergence 属于更广泛的 f-divergence 中的一种. 如果P和Q被定义成空间 ...
- 概率分布之间的距离度量以及python实现(三)
概率分布之间的距离,顾名思义,度量两组样本分布之间的距离 . 1.卡方检验 统计学上的χ2统计量,由于它最初是由英国统计学家Karl Pearson在1900年首次提出的,因此也称之为Pearson ...
- 概率分布之间的距离度量以及python实现
1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式.(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧 ...
- 数理统计(二)——Python中的概率分布API
数理统计(二)——Python中的概率分布API iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 数理统计中进行假设检验需要查一些分布的上分位数表.在scip ...
- Python中的随机采样和概率分布(二)
在上一篇博文<Python中的随机采样和概率分布(一)>(链接:https://www.cnblogs.com/orion-orion/p/15647408.html)中,我们介绍了Pyt ...
- Python中的随机采样和概率分布(一)
Python(包括其包Numpy)中包含了了许多概率算法,包括基础的随机采样以及许多经典的概率分布生成.我们这个系列介绍几个在机器学习中常用的概率函数.先来看最基础的功能--随机采样. 1. rand ...
随机推荐
- mysql获取刚插入(添加)记录的自动编号id
我们在写数据库程序的时候,经常会需要获取某个表中的最大序号数, 一般情况下获取刚插入的数据的id,使用select max(id) from table 是可以的.但在多线程情况下,就不行了. 下面介 ...
- VS运行遇到的那些坑
今天运行VS项目好好的,就是安装了VS2019后,就出现了无法连接到IIS服务器,这个问题,然后各种办法都试了无效. 解决方法: 1.删除根目录的.vs文件,然后重新生成. 2.修改调试这里的IP改为 ...
- 机器学习 AI 谷歌ML Kit 与苹果Core ML
概述 移动端所说的AI,通常是指"机器学习". 定义:机器学习其实就是研究计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身.从实践的意义 ...
- Python中使用字典的几个小技巧
1 解包 所谓解包,就是将字典通过 ** 操作符转为 Key=Value 的形式,这种形式可以直接传给函数作为关键字参数. 说说适用的几种情况. 1.1 搜索拼接条件 当应用中使用类似 SQLAlch ...
- Git学习笔记----基础运用
安装Git Windows: 进入官网下载或百度网盘下载 Git(V2.23_x64) 提取码:uf2x Ubuntu: sudo apt-get -install git 安装完成之后打开git命令 ...
- 【翻译】Prometheus 2.12.0 新特性
Prometheus 2.12.0 现在(2019.08.17)已经发布,在上个月的 2.11.0 之后又进行了一些修正和改进. 在当前的 6 周发布周期中,每一个 Prometheus 版本都有比较 ...
- 手写SpringMVC 框架
手写SpringMVC框架 细嗅蔷薇 心有猛虎 背景:Spring 想必大家都听说过,可能现在更多流行的是Spring Boot 和Spring Cloud 框架:但是SpringMVC 作为一款实现 ...
- Java基本数据类型的传值
传递值: 说明:标题其实说法是错误的.Java中只有值传递,没有引用传递. ... ... //定义了一个改变参数值的函数 public static void changeValue(int x) ...
- python学习之【第十五篇】:Python中的常用模块之time模块
1.前言 在Python中,对时间的表示或操作通常要使用到time模块.本篇博文就来记录一下time模块中常用的几种时间表示转换方法. 2. 三种时间表示形式 2.1 时间戳 从1970年1月1日零点 ...
- Linux 项目 shell 自动获取报告本机IP (1) | 通过shell 自动获取报告本机IP
由于电脑设置静态IP经常出现链接不上网络,动态IP又非常不方便,故有了这个想法并实现 原理: Linux,包含PC机器,树莓派等,通过shell 自动获取报告本机IP | 通过 Mutt+Msmtp ...