selenium-find_element相关内容(2)
find_element跟find_element_by_xxx的区别
1.查看文件D:\soft\python36\Lib\site-packages\selenium\webdriver\remote\webdriver.py 可发现find_element_by_xxx的方法都是返回的find_element方法
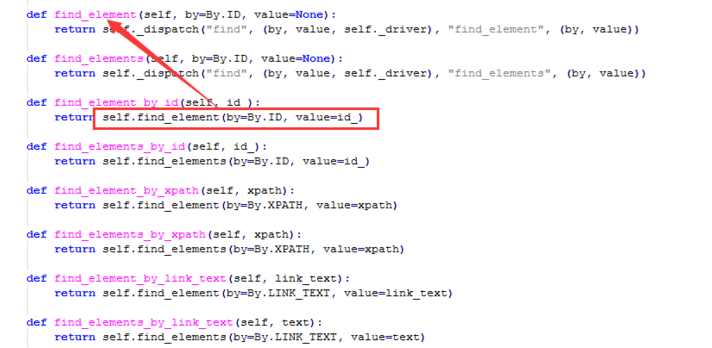
2. 查看文件D:\soft\python36\Lib\site-packages\selenium\webdriver\common\by.py 可发现
class By(object):
"""
Set of supported locator strategies.
""" ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
明白以上后举个例子,以下红色字体实现点击百度一下的三种方法是等效的:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
time.sleep(2)
driver.find_element(By.CSS_SELECTOR,".btn_wr>input").click()
# driver.find_element("css selector",".btn_wr>input").click()
# driver.find_element_by_css_selector(".btn_wr>input").click()
time.sleep(2)
driver.quit()

find_element 与 find_elements的区别
find_element得到的是一个元素
find_elements得到的是一个列表
selenium-find_element相关内容(2)的更多相关文章
- linux用户权限相关内容查看
linux用户权限相关内容查看 1 用户信息 创建用户一个名为 webuser 的账号,并填写相应的信息: root@iZ94fabhqhuZ:~# adduser webuser Adding ...
- SharePoint安全 - 在Goolge和Bing中查找SharePoint相关内容
博客地址 http://blog.csdn.net/foxdave 本篇提供两个查询串字典,分别对应Google和Bing的搜索,用来查询SharePoint网站的相关内容 Google ShareP ...
- 韩顺平细说Servlet视频系列之tom相关内容
韩顺平细说Servlet视频系列之tom相关内容 tomcat部署项目操作(注意:6.0版本以后的支持该操作,5.x版本需要另外配置?待验证!) 项目发布到tomcat的webapps文件下,然后启动 ...
- jQuery实现页内查找相关内容
当需要在页面中查找某个关键字时,一是可以通过浏览器的查找功能实现,二是可以通过前端脚本准确查找定位,本文介绍通过jQuery实现的页面内容查找定位的功能,并可扩展显示查找后的相关信息. 本文以查找车站 ...
- Struts2(四)——页面相关内容
上篇博客总结了数据流转各个方面的内容,这篇重点说一下框架对于界面上知识. 一,说到页面,记得在总体介绍中,说到Struts2比Struts1的一方面优势就是它支持更多的视图技术(Freemarker, ...
- 学习笔记之html5相关内容
写一下昨天学习的html5的相关内容,首先谈下初次接触html5的感受.以前总是听说html5是如何的强大,如何的将要改变世界.总是充满了神秘感.首先来谈一下我接触的第一个属性是 input的里面的 ...
- 基于KNN的相关内容推荐
如果做网站的内容运营,相关内容推荐可以帮助用户更快地寻找和发现感兴趣的信息,从而提升网站内容浏览的流畅性,进而提升网站的价值转化.相关内容 推荐最常见的两块就是“关联推荐”和“相关内容推荐”,关联推荐 ...
- 第一天上午——HTML网页基础知识以及相关内容
今天上午学习了HTML基础知识以及相关内容,还有DW的基本使用方法. HTML(HyperText Markup Language):超文本标记语言,超文本:网页中除了包含文本文字之外,还包含了图片, ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- 在地图中调用显示FeatureLayer并进行render、popupTemplate、添加图例等相关内容的设置
ArcGIS Server发布完FeatureLayer后,就可以在自己的代码中调用并在地图上显示出来了. 一.代码框架 调用FeatureLayer,要在require开头引入"esri/ ...
随机推荐
- [Pandas] 05 - Parallel processing
相关资源 [Python] 09 - Multi-processing [Pandas] 01 - A guy based on NumPy [AI] 深度数学 - Bayes 这章非常有意思,但一定 ...
- 【笔试题】Java笔试题知识点
Java高概率笔试题知识点 Java语法基础部分 [解析]java命令程序执行字节码文件是,不能跟文件的后缀名! 1.包的名字都应该是由小写单词组成,它们全都是小写字母,即便中间的单词亦是如此 2.类 ...
- 从壹开始学习 NetCore 新篇章 ║ Blog.Core 开发社之招募计划书
宫 哈喽大家好,国庆马上就要来了,在新的第四季度来临之际,祝大家年末能顺顺利利,解决所有的难题.大家可能从我的标题里也能看的出来,老张又要耍花样,搞事情了,近来随着 netcore 3.0 的正式推出 ...
- python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜
本次主要爬取Top100电影榜单的电影名.主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢 首先打开要爬取的网址https://maoyan.com/board/4, ...
- 基于Docker搭建大数据集群(五)Mlsql部署
主要内容 mlsql部署 前提 zookeeper正常使用 spark正常使用 hadoop正常使用 安装包 微云下载 | tar包目录下 mlsql-cluster-2.4_2.11-1.4.0.t ...
- Hadoop点滴-外围概念
有句话说的好“大数据胜于好算法” 硬盘存储容量在不断提升的同时,访问速度(硬盘数据读取速度)却没有同步增长:1990年,访问全盘需要5分钟,20年后,需要2.5小时 不同的业务大数据,存储在一套HDF ...
- springboot 项目打包部署后设置上传文件访问的绝对路径
1.设置绝对路径 application.properties的配置 #静态资源对外暴露的访问路径 file.staticAccessPath=/upload/** #文件上传目录(注意Linux和W ...
- 利用Travis CI+GitHub实现持续集成和自动部署
前言 如果你手动部署过项目,一定会深感持续集成的必要性,因为手动部署实在又繁琐又耗时,虽然部署流程基本固定,依然容易出错. 如果你很熟悉持续集成,一定会同意这样的观点:"使用它已经成为一种标 ...
- 一条SQL查询语句是如何执行的?
本篇文章将通过一条 SQL 的执行过程来介绍 MySQL 的基础架构. 首先有一个 user_info 表,表里有一个 id 字段,执行下面这条查询语句: select * from user_inf ...
- Creating a Store Locator with PHP, MySQL & Google Maps(保存地图坐标 经纬度方法 google mysql)
Google Geo APIs Team August 2009 This tutorial is intended for developers who are familiar with PHP/ ...