机器学习:评价分类结果(F1 Score)
一、基础
- 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣?
- 根据具体使用场景而定:
- 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票;此情况下,模型精准率越高越优。
- 例2:病人诊断,就诊人员是否患病?业务要求更全面的找出所有患病的病人,而且尽量不漏掉一个患者;甚至说即使将正常人员判断为病人也没关系,只要不将病人判断成健康人员就好。此情况,模型召回率越高越优。
- 疑问2::有些情况下,即需要考虑精准率又需要考虑召回率,二者所占权重一样,怎么中欧那个判断?
- 方法:采用新的评价标准,F1 Score;
二、F1 Score
- F1 Score:兼顾降准了和召回率,当急需要考虑精准率又需要考虑召回率,可查看模型的 F1 Score,根据 F1 Score 的大小判断模型的优劣;
- F1 = 2 * Precision * recall / (precision + recall),是二者的调和平均值;
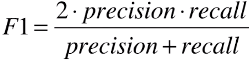
- F1 是 precision 和 recall 的调和平均值;
- 调和平均值:如果 1/a = (1/b + 1/c) / 2,则称 a 是 b 和 c 的调和平均值;
- 调和平均值特点:|b - c| 越大,a 越小;当 b - c = 0 时,a = b = c,a 达到最大值;
- 具体到精准率和召回率,只有当二者大小均衡时,F1 指标才高,
三、F1 Score 的使用
- F1 Score 指标在 scikit-learn 中封装在了 sklearn.metrics 模块下的 f1_score() 方法中
from sklearn.metrics import f1_score f1_score(y_test, y_log_predict)
# 0.8674698795180723 import numpy as np
from sklearn import datasets digits = datasets.load_digits()
X = digits.data
y = digits.target.copy() y[digits.target==9] = 1
y[digits.target!=9] = 0 from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
y_log_predict = log_reg.predict(X_test) from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
# 精准率:0.9473684210526315 from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
# 召回率:0.8 from sklearn.metrics import f1_score
f1_score(y_test, y_log_predict)
# F1 Score 指标:0.8674698795180723- 使用scikit-learn 中 sklearn.metrics 模块下的 confusion_matrix()、precision_score()、recall_score()、f1_score() 方法时,所需要的参数都是 y_test、y_predict;
机器学习:评价分类结果(F1 Score)的更多相关文章
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 机器学习:评价分类结果(Precision - Recall 的平衡、P - R 曲线)
一.Precision - Recall 的平衡 1)基础理论 调整阈值的大小,可以调节精准率和召回率的比重: 阈值:threshold,分类边界值,score > threshold 时分类为 ...
- hihocoder 1522 : F1 Score
题目链接 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和他的小伙伴们一起写了很多代码.时间一久有些代码究竟是不是自己写的,小Hi也分辨不出来了. 于是他实现 ...
- 机器学习评价方法 - Recall & Precision
刚开始看这方面论文的时候对于各种评价方法特别困惑,还总是记混,不完全统计下,备忘. 关于召回率和精确率,假设二分类问题,正样本为x,负样本为o: 准确率存在的问题是当正负样本数量不均衡的时候: 精心设 ...
- F1 score,micro F1score,macro F1score 的定义
F1 score,micro F1score,macro F1score 的定义 2018年09月28日 19:30:08 wanglei_1996 阅读数 976 本篇博客可能会继续更新 最近在 ...
- 【笔记】F1 score
F1 score 关于精准率和召回率 精准率和召回率可以很好的评价对于数据极度偏斜的二分类问题的算法,有个问题,毕竟是两个指标,有的时候这两个指标也会产生差异,对于不同的算法,精准率可能高一些,召回率 ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- How to compute f1 score for each epoch in Keras
https://medium.com/@thongonary/how-to-compute-f1-score-for-each-epoch-in-keras-a1acd17715a2 https:// ...
随机推荐
- Kubernetes busybox nslookup问题
使用最新版本的busybox会出现nslookup提示无法解析的问题: Server: 10.96.0.10 Address: 10.96.0.10:53 ** server can't find k ...
- mongodb count 导致不正确的数量(mongodb count 一个坑)
在mongodb 集群中,if 存在orphaned documents 和chunk migration, count查询可能会导致一个不正确的查询结果,例如我就是踩的这个坑,先不说话,看结果: ...
- 【转】Android ImageView的scaleType属性与adjustViewBounds属性
ImageView的scaleType的属性有好几种,分别是matrix(默认).center.centerCrop.centerInside.fitCenter.fitEnd.fitStart.fi ...
- Codeforces Round #280 (Div. 2) D. Vanya and Computer Game 数学
D. Vanya and Computer Game time limit per test 2 seconds memory limit per test 256 megabytes input s ...
- Codeforces Round #273 (Div. 2) D. Red-Green Towers 背包dp
D. Red-Green Towers time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- Compaction介绍
Compaction介绍 Compaction是buffer->flush->merge的Log-Structured Merge-Tree模型的关键操作,主要起到如下几个作用: 1)合并 ...
- PyCharm 的初始设置2 - 打开、新建项目
03. 新建/打开一个 Python 项目 3.1 项目简介 开发 项目 就是开发一个 专门解决一个复杂业务功能的软件 通常每 一个项目 就具有一个 独立专属的目录,用于保存 所有和项目相关的文件 – ...
- 2017-02-23 .NET Core Tools转向使用MSBuild项目格式
微软之前为了让.NET Core和ASP.NET Core能够支持Windows Visual Studio之外的开发平台,创建了基于project.json格式的项目系统.不过可惜,这种格式与之前的 ...
- iTerm2 + Oh My Zsh
iTerm2 http://iterm2.com/downloads.html https://iterm2.com/downloads/stable/iTerm2-2_1_4.zip Oh My Z ...
- hzau 1206 MathematicalGame
1206: MathematicalGame Time Limit: 2 Sec Memory Limit: 1280 MBSubmit: 124 Solved: 15[Submit][Statu ...