Elasticsearch教程(五) elasticsearch Mapping的创建
一、Mapping介绍
在Elasticsearch中,Mapping是什么?
mapping在Elasticsearch中的作用就是约束。
1.数据类型声明
它类似于静态语言中的数据类型声明,比如声明一个字段为String, 以后这个变量都只能存储String类型的数据。同样的, 一个number类型的mapping字段只能存储number类型的数据。
2.Mapping它定义了 Type 的属性。
"_ttl": {"enabled": false}
表示 ttl关闭,其实ttl默认就是关闭。
3.指定分词器。
"id": {
"index": "not_analyzed",
"type": "string"
}
指定字段 id不分词,并且类型为 string。
二、创建Mapping
1.下面介绍一下HTTP的创建方式。我一般用Java 创建方式。
PUT http://123.123.123.123:9200/index/type/
{
"settings": {
//设置10个分片,理解为类似数据库中的表分区中一个个分区的概念,不知道是否妥当
"number_of_shards": 10
},
"mappings": {
"trades": {
"_id": {
"path": "id"
},
"properties": {
"id": {
"type": "integer",
//id:自增数字
//要求:查询
"store" : true
},
"name": { //名称
"type": "string"
},
"brand": { //品牌: PG,P&G,宝洁集团,宝洁股份,联想集团,联想电脑等
"type": "string"
},
"orderNo": { //订单号 :如ATTS000928732
"type": "string",
"index": "not_analyzed"
},
"description": {
//描述: 2015款玫瑰香型强生婴儿沐浴露,550ml,包邮
"type": "string",
"sort": true
},
"date": {
"type": "date"
},
"city": {
"type": "string"
},
"qty": {// index分词无效
"type": "float"
},
"price": {
//价格: float index无效
"type": "float"
}
}
}
}
}
2.Java方式创建。
构建Mapping
package com.sojson.core.elasticsearch.mapping;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
import java.io.IOException;
import org.elasticsearch.common.xcontent.XContentBuilder;
public class ZhidaoMapping {
public static XContentBuilder getMapping(){
XContentBuilder mapping = null;
try {
mapping = jsonBuilder()
.startObject()
//开启倒计时功能
.startObject("_ttl")
.field("enabled",false)
.endObject()
.startObject("properties")
.startObject("title")
.field("type","string")
.endObject()
.startObject("question")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("answer")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("category")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("author")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("date")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("answer_author")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("answer_date")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("description")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("keywords")
.field("type","string")
.field("index","not_analyzed")
.endObject()
.startObject("read_count")
.field("type","integer")
.field("index","not_analyzed")
.endObject()
//关联数据
.startObject("list").field("type","object").endObject()
.endObject()
.endObject();
} catch (IOException e) {
e.printStackTrace();
}
return mapping;
}
}
创建Mapping
public static void createBangMapping(){
PutMappingRequest mapping = Requests.putMappingRequest(INDEX).type(TYPE).source(ZhidaoMapping.getMapping());
ESTools.client.admin().indices().putMapping(mapping).actionGet();
}
创建的时候,需要 index已经创建才行,要不然会报错。
//构建一个Index(索引)CreateIndexRequest request = new CreateIndexRequest(INDEX);
ESTools.client.admin().indices().create(request);
创建完毕在Head插件里查看或者Get请求。
http://123.123.123.123:9200/index/type/_mapping
得到的结果:
{
"zhidao_index": {
"mappings": {
"zhidao_type": {
"_ttl": {
"enabled": false
},
"properties": {
"answer": {
"type": "string",
"index": "not_analyzed"
},
"answerAuthor": {
"type": "string"
},
"answerDate": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"//这里出现了复合类型
},
"answer_author": {
"type": "string",
"index": "not_analyzed"
},
"answer_date": {
"type": "string",
"index": "not_analyzed"
},
"author": {
"type": "string",
"index": "not_analyzed"
},
"category": {
"type": "string",
"index": "not_analyzed"
},
"date": {
"type": "string",
"index": "not_analyzed"
},
"description": {
"type": "string",
"index": "not_analyzed"
},
"id": {
"type": "string",
"index": "not_analyzed"
},
"keywords": {
"type": "string",
"index": "not_analyzed"
},
"list": {
"type": "object"
},
"question": {
"type": "string",
"index": "not_analyzed"
},
"readCount": {
"type": "long"
},
"read_count": {
"type": "integer"
},
"title": {
"type": "string"
}
}
}
}
}
}
Head插件查看
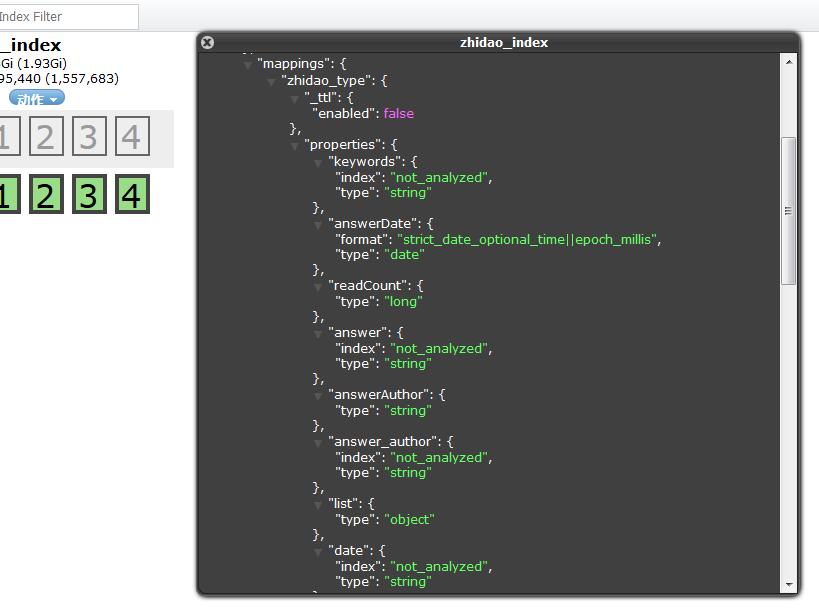
其实Mapping,你接触Elasticsearch久一点也就那么回事。我们虽然知道Elasticsearch有根据数据识别创建Mapping,但是最好是创建,并且指定分词与否。这样高效一点。
Elasticsearch教程(五) elasticsearch Mapping的创建的更多相关文章
- (转)ElasticSearch教程——汇总篇
https://blog.csdn.net/gwd1154978352/article/details/82781731 环境搭建篇 ElasticSearch教程——安装 ElasticSearch ...
- ElasticSearch(五):Mapping和常见字段类型
ElasticSearch(五):Mapping和常见字段类型 学习课程链接<Elasticsearch核心技术与实战> 什么是Mapping Mapping类似数据库中的schema的定 ...
- Elasticsearch入门教程(五):Elasticsearch查询(一)
原文:Elasticsearch入门教程(五):Elasticsearch查询(一) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:h ...
- Elasticsearch教程(六) elasticsearch Client创建
Elasticsearch 创建Client有几种方式. 首先在 Elasticsearch 的配置文件 elasticsearch.yml中.定义cluster.name.如下: cluster ...
- ElasticSearch实战系列五: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合
Title:ElasticSearch实战系列四: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合 前言 在上上一篇中介绍了ElasticSearch实战系列三: Elas ...
- Elasticsearch 教程--入门
1.1 初识 Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说 Lucene 是当今最先进,最高效的全功能开源搜索引擎框架. 但是 L ...
- Elasticsearch系列(五)----JAVA客户端之TransportClient操作详解
Elasticsearch JAVA操作有三种客户端: 1.TransportClient 2.JestClient 3.RestClient 还有种是2.3中有的NodeClient,在5.5.1中 ...
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- Elasticsearch教程(二)java集成Elasticsearch
1.添加maven <!--tika抽取文件内容 --> <dependency> <groupId>org.apache.tika</groupId> ...
随机推荐
- Nodejs express框架 浅析
http://www.expressjs.com.cn/ 1. 中间件 ①挂载中间件的函数:app.use var http = require('http'); var express = requ ...
- checkbox选中 解决兼容问题
jquery 1.9 checkbox 是否选中 if($("#chk_selectedall").prop('checked')) checkbox 选中 $("#ch ...
- 忘记MySQL数据库密码的解决办法
在windows下: 打开命令行窗口,停止MySQL服务: Net stop MySQL 启动mysql,一般到mysql的安装路径,找到 mysqld-nt.exe (或mysqld.exe) 执行 ...
- 以最简单的方式了解--Github
大概是从寒假的时候开始正式的赚取github,从github上面学习一些开源的文档,我记得我注册github账号到现在已经9个月了,但只有最近的2个月才发现github这个新世界,写这篇文章是为了刚入 ...
- POJ 2135 Farm Tour (费用流)
[题目链接] http://poj.org/problem?id=2135 [题目大意] 有一张无向图,求从1到n然后又回来的最短路 同一条路只能走一次 [题解] 题目等价于求从1到n的两条路,使得两 ...
- DB2如何调整表空间大小
DB2如何调整表空间大小 刚刚接到客户那边打的电话,程序一直报错,所有的业务都做不了,拷贝了一份应用服务器(weblogic)的日志,日志里显示: WARN : 2009-06-18 16:24:32 ...
- 【状态压缩DP】【BZOJ1087】【SCOI2005】互不侵犯king
1087: [SCOI2005]互不侵犯King Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3135 Solved: 1825[Submit][ ...
- Systemd入门教程:实战篇(转)
作者: 阮一峰 日期: 2016年3月 8日 上一篇文章,我介绍了 Systemd 的主要命令,今天介绍如何使用它完成一些基本的任务. 一.开机启动 对于那些支持 Systemd 的软件,安装的时候, ...
- 给 DiscuzX3 缩略图添加水印
Discuz X3 默认开启缩略图的时候水印只添加到原图上面,而缩略图上面无法进行水印图的添加,需要改下程序,方可给缩略图添加水印,需要修改2个地方: 1.打开 source\function\fun ...
- 【SQL】用Sql Server自动生产html格式的数据字典
原文:[SQL]用Sql Server自动生产html格式的数据字典 本文软件环境:Sql Server 2008. 1.打开sql server管理器,给选定的表添加描述信息,给指定的字段添加描述信 ...