Zookeeper请求处理原理分析
Zookeeper是可以存储数据的,所以我们可以把它理解一个数据库,实际上它的底层原理本身也和数据库是类似的。
一、数据库的原理
我们知道,数据库是用来存储数据的,只是数据可以存储在内存中或磁盘中。而Zookeeper实际是结合了这两种的,Zookeeper中的数据即会存储在磁盘中以达到持久化的目的,也会同步到内存中以到达快速访问的目的。
事实上,用过Zookeeper的同学应该知道,Zookeeper中有两种类型的节点:持久化节点和临时节点。
持久化节点:会持久化在磁盘中,除非主动删除,将一直存在。
临时节点:不会持久化在磁盘中,只会存储在内存中,创建这个临时节点的Session一旦过期,此临时节点也将自动被删除。
二、数据库处理数据的原理
作为一个数据库,肯定是要接收客户端创建、修改、删除、查询节点等请求的。
在Zookeeper中对于请求分为两类:
事务性请求
非事务性请求
1、事务性请求
Zookeeper通常都是以集群模式运行的,也就是Zookeeper集群中各个节点的数据需要保持一致的。但是和Mysql集群不一样的是:
Mysql集群中,从服务器是异步从主服务器同步数据的,这中间的间隔时间可以比较长。
Zookeeper集群中,当某一个集群节点接收到一个写请求操作时,该节点需要将这个写请求操作发送给其他节点,以使其他节点同步执行这个写请求操作,从而达到各个节点上的数据保持一致,也就是数据一致性。我们通常说Zookeeper保证CAP理论中的CP就只这个意思。
Zookeeper集群底层是怎么保证数据一致性的,其实是用的两阶段提交+过半机制来保证的。
事务性请求包括:更新操作、新增操作、删除操作,结合上面的分析,因为这些操作是会影响数据的,所以要保证这些操作在整个集群内的事务性,所以这些操作就是事务性请求。
2、非事务性请求
那么非事务性请求就好理解的,像查询操作、exist操作这些不影响数据的操场,就不需要集群来保持事务性,所以这些操场就是非事务性请求。
Zookeeper在处理事务性请求时,比处理非事务性请求要复杂很多
三、数据在磁盘中的表示
假设我们现在在Zookeeper中有一个数据节点,节点名为/datanode,内容为125,该节点是持久化节点,所以该节点信息会保存在文件中。
可能大家都会认为是类似下面这样方式保存在磁盘文件中的,方法一:

但是除开这种表示方法,还有另外一种表示方法,快照+事务日志,比如方法二:
当前快照:

当前事务日志:

乍一看方法二比方法一要更复杂,并且占用的磁盘更多。但是我们上文提到过,Zookeeper集群中的节点在处理事务性请求时,需要将事务操作同步给其他节点,所以这里的事务操作是一定要进行持久化的,以便在同步给其他节点时出现异常进行补偿。所以就出现了事务日志。实际上事务日志还运行数据进行回滚,这个在两阶段提交中也是非常重要的。
那么快照又有什么用呢?事务日志一定要有,但是随着时间的推移,日志肯定会越来越多,所以肯定不能持久化历史上所有的日志,所以Zookeeper会定时的进行快照,并删除之前的日志。
那么如果按方法二这么存储数据,在对数据进行查询时就不太方便了。上文说到,Zookeeper为了提高数据的查询速度,会在内存中也存储一份数据,那么内存中的这份数据又该怎么存呢?
四、数据在内存中的表示
Zookeeper中的数据在内存中的表示其实和上文的方法一很类似,只是Zookeeper中的数据是具有文件目录特点的,说白了就是Zookeeper中的数据节点的名字一定要以“/”开头,这样就导致Zookeeper中的数据类似一颗树:

一颗具有父子层级的多叉树,在Zookeeper源码中叫DataTree。
五、请求处理逻辑
请看下图:
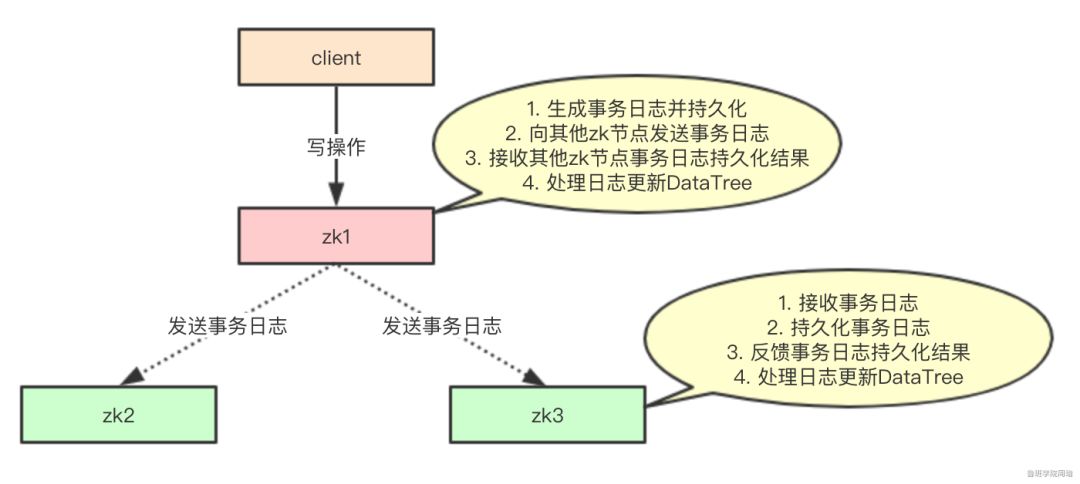
请注意,对于上图,Zookeeper真正的底层实现,zk1是Leader,zk2和zk3是Learner,是根据领导者选举选出来的。
非事务性请求直接读取DataTree上的内容,DataTree是在内存中的,所以会非常快。
六、总结
这篇文章介绍了Zookeeper在处理请求时的几个核心概念:
1、事务性请求
2、事务日志
3、快照
4、DataTree
5、两阶段提交
今天分享一套系统的zookeeper学习视频,java系统学习必备,值得大家参考学习,希望能对你有帮助!
Zookeeper请求处理原理分析的更多相关文章
- zookeeper安装使用及工作原理分析
1. Zookeeper概念简介 Zookeeper是一个分布式协调服务:就是为用户的分布式应用程序提供协调服务,它是集群的管理者,监视着集群中各个节点的状态,根据节点提交的反馈进行下一步合理操作. ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper工作原理、安装配置、工具命令简介
1.Zookeeper简介 Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理等等. 2.zo ...
- [转载] zookeeper工作原理、安装配置、工具命令简介
转载自http://www.cnblogs.com/kunpengit/p/4045334.html 1 Zookeeper简介Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到 ...
- 学习Zookeeper之第3章Zookeeper内部原理
第 3 章 Zookeeper 内部原理 3.1 选举机制 3.2 节点类型 3.3 stat 结构体 3.4 监听器原理 1)监听原理详解 2)常见的监听 3.5 写数据流程 第 3 章 Z ...
- Tomcat源码分析——请求原理分析(下)
前言 本文继续讲解TOMCAT的请求原理分析,建议朋友们阅读本文时首先阅读过<TOMCAT源码分析——请求原理分析(上)>和<TOMCAT源码分析——请求原理分析(中)>.在& ...
- Tomcat源码分析——请求原理分析(中)
前言 在<TOMCAT源码分析——请求原理分析(上)>一文中已经介绍了关于Tomcat7.0处理请求前作的初始化和准备工作,请读者在阅读本文前确保掌握<TOMCAT源码分析——请求原 ...
随机推荐
- JavaScript 之 String 对象
String 对象 之前学习的是 基本数据类型 String 类型,现在讨论的是 String对象(包装类型). String的特点:字符串的不可变性. var str = 'abc'; str = ...
- 面试题:java内存中的堆区和数据结构中的堆有什么区别
java内存中的堆是一个 链表, 数据结构中的堆:就是一个栈
- .NET编译问题汇总
1.Your project.json doesn't list 'win' as a targeted runtime. You should add '"win": { }' ...
- jemeter学习-badboy录制与代理服务器录制
一 基本元素的介绍 1. 添加测试计划 2.添加线程组 线程数---并发数,模拟多少个用户并发 Ramp-up periods ----我们要在多少秒之内进行多少用户的并发 循环次数---可以选择一次 ...
- Python之路(第四十三篇)线程的生命周期、全局解释器锁
一.线程的生命周期(新建.就绪.运行.阻塞和死亡) 当线程被创建并启动以后,它既不是一启动就进入执行状态的,也不是一直处于执行状态的,在线程的生命周期中,它要经过新建(new).就绪(Ready).运 ...
- ThreadLocal概述、以及存在的坑
ThreadLocal: 线程的一个本地化对象.当多线程中的对象使用ThreadLocal维护变量是,ThreadLocal为每个使用该变量的线程分配一个独立的变量副本. threadlocal通常定 ...
- java 8大happen-before原则
1.单线程happen-before原则:在同一个线程中,书写在前面的操作happen-before后面的操作. 2.锁的happen-before原则:同一个锁的unlock操作happen-bef ...
- Golang: 解析JSON数据之三
前面我们介绍了 Marshal 和 Unmarshal 方法,今天再解一下另外两个 API:Encoder 和 Decoder. Encoder Encoder 主要负责将结构对象编码成 JSON 数 ...
- CC2530 light_switch分析
一些关键字: CCM - Counter with CBC-MAC (mode ofoperation) HAL - HardwareAbstraction Layer (硬件抽象层) ...
- 网络服务-SAMBA
1. Samba 概述 SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和打印机的一种通信协议,它为局域网内不同操作系统的计算机之间提供文件及打印机等资源的共享 ...