Google BERT摘要
1.BERT模型
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1.1 模型结构
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
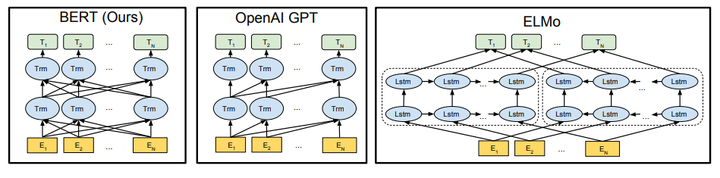
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
1.2 Embedding
这里的Embedding由三种Embedding求和而成:
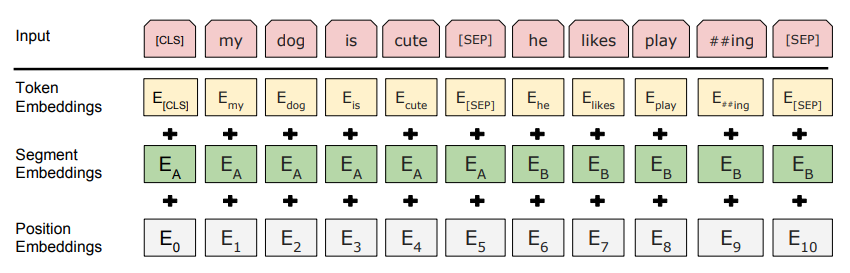
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
总结:
1. BERT的特征提取,是在捕捉词的(前后)位置关系。bidirectional决定了能获得前后的关系,position embedding决定了能学到更长的顺序关系。
2.训练,分为pre-train和fine-tune。pre-train中用到了MLM, Masked LM.
3. trick: MLM. 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
4. 缺点: (1)[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
(2)每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
https://zhuanlan.zhihu.com/p/46652512
https://arxiv.org/pdf/1810.04805.pdf
Google BERT摘要的更多相关文章
- Google BERT应用之《红楼梦》对话人物提取
Google BERT应用之<红楼梦>对话人物提取 https://www.jiqizhixin.com/articles/2019-01-24-19
- Google BERT
概述 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不 ...
- HTML5扩展之微数据与丰富网页摘要
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- HTML5扩展之微数据与丰富网页摘要itemscope, itemtype, itemprop
HTML5扩展之微数据与丰富网页摘要 by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpr ...
- HTML5扩展之微数据与丰富网页摘要——张鑫旭
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- Google论文BigTable拜读
这周少打点dota2,争取把这篇论文读懂并呈现出来,和大家一起分享. 先把论文搞懂,然后再看下和论文搭界的知识,比如hbase,Chubby和Paxos算法. Bigtable: A Distribu ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
随机推荐
- v-for给img的src动态赋值问题
做一个轮播图,给img赋值src <el-carousel-item v-for="(item, index) in carouselImgs" :key="ind ...
- Keil的RTX特性
Keil RTX是为ARM和Cortex-M设备设计的免版税,确定性的实时操作系统.它允许您创建同时执行多个功能的程序,并帮助创建更好的结构和更容易维护的应用程序. 特征 具有源代码的免版权,确定性R ...
- PHP函数file_get_contents()使用 https 协议时报错:SSL operation failed
场景: file_get_contents() 函数是用于将文件的内容读入到一个字符串中,是读取文件内容常用的函数之一. 但是有时在服务器上使用file_get_contents() 函数请求http ...
- cortex 水平扩展试用
cortex 支持多实例运行,可以灵活实际大规模的部署,以下demo,运行了三个cortex 实例,没有配置副本数(主要是ha ) 同时对于三个cortex 使用haproxy 做为push 以及查询 ...
- GIT与项目
创建GitHub账号 本地Git仓库和GitHub仓库之间的传输是通过SSH加密的 step1:创建项目的SSH Key ssh-keygen -t rsa -C "your email@e ...
- ACM之Java输入输出
本文转自:ACM之Java输入输出 一.Java之ACM注意点 1. 类名称必须采用public class Main方式命名 2. 在有些OJ系统上,即便是输出的末尾多了一个“ ”,程序可能会输出错 ...
- CTSC 2017 游戏[概率dp 线段树]
小 R 和室友小 B 在寝室里玩游戏.他们一共玩了 $n$ 局游戏,每局游戏的结果要么是小 R 获胜,要么是小 B 获胜. 第 $1$ 局游戏小 R 获胜的概率是 $p_1$,小 B 获胜的概率是 $ ...
- 第03组 Alpha冲刺(3/4)
队名:不等式方程组 组长博客 作业博客 团队项目进度 组员一:张逸杰(组长) 过去两天完成的任务: 文字/口头描述: 制定了初步的项目计划,并开始学习一些推荐.搜索类算法 GitHub签入纪录: 暂无 ...
- MSSQL复制表数据及表结构
目标表存在: insert into 目标表 select * from 原表 目标表不存在: select * into 目标表 from 原表 复制表结构 select * into 目标表 fr ...
- @RequestBody的使用
一.说明 首先@RequestBody需要接的参数是一个string化的json,这里直接使用JSON.stringify(json)这个方法来转化 其次@RequestBody,从名称上来看也就是说 ...