Google BERT
概述
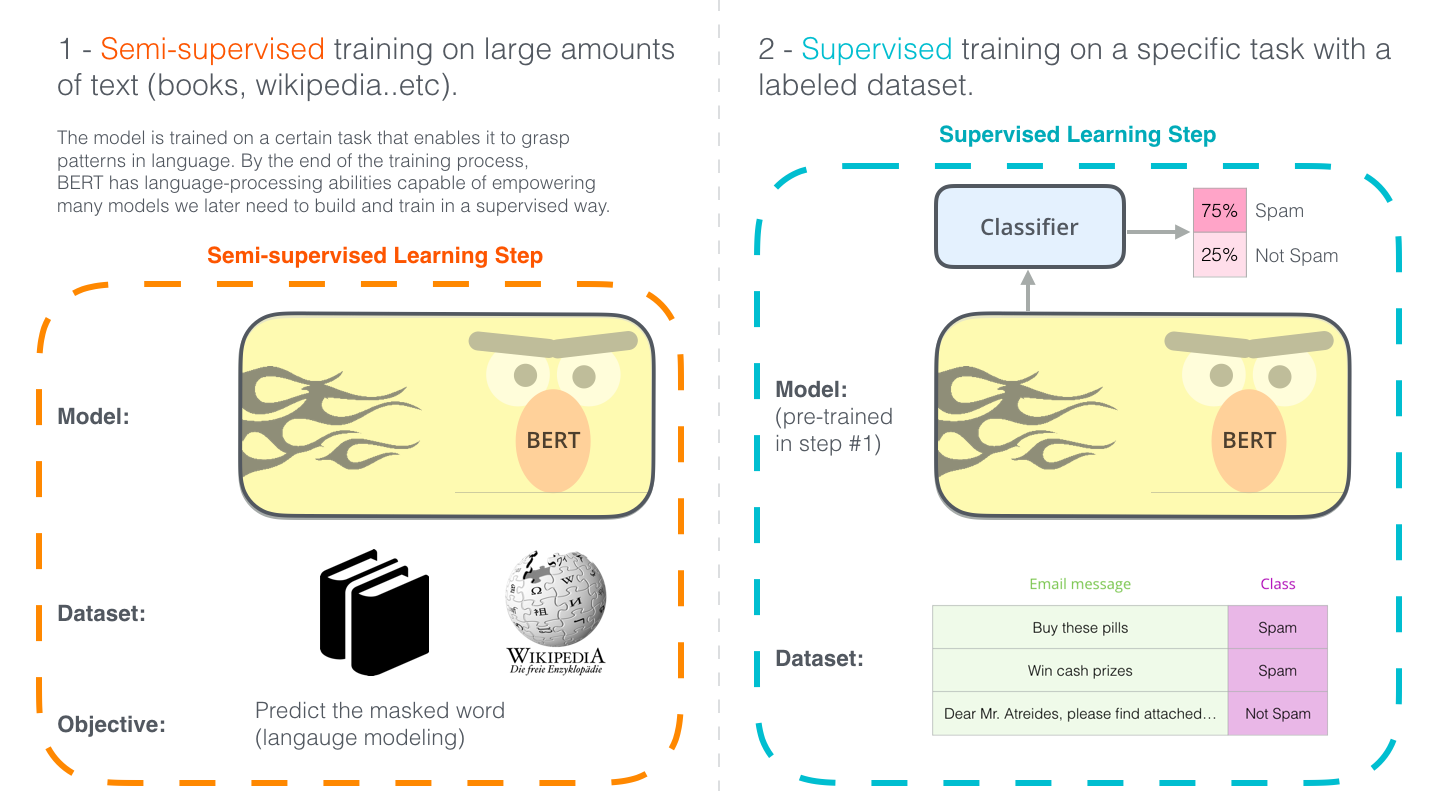
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT的应用步骤
模型结构
- BERT BASE:和OPENAI Transformer大小差不多
- 12个encoder layers(Transformer Blocks)
- 768个隐藏单元的前向网络
- 12个attention heads
- BERT LARGE:State of Art
- 24个encoder layers(Transformer Blocks)
- 1024个隐藏单元的前向网络
- 16个attention heads
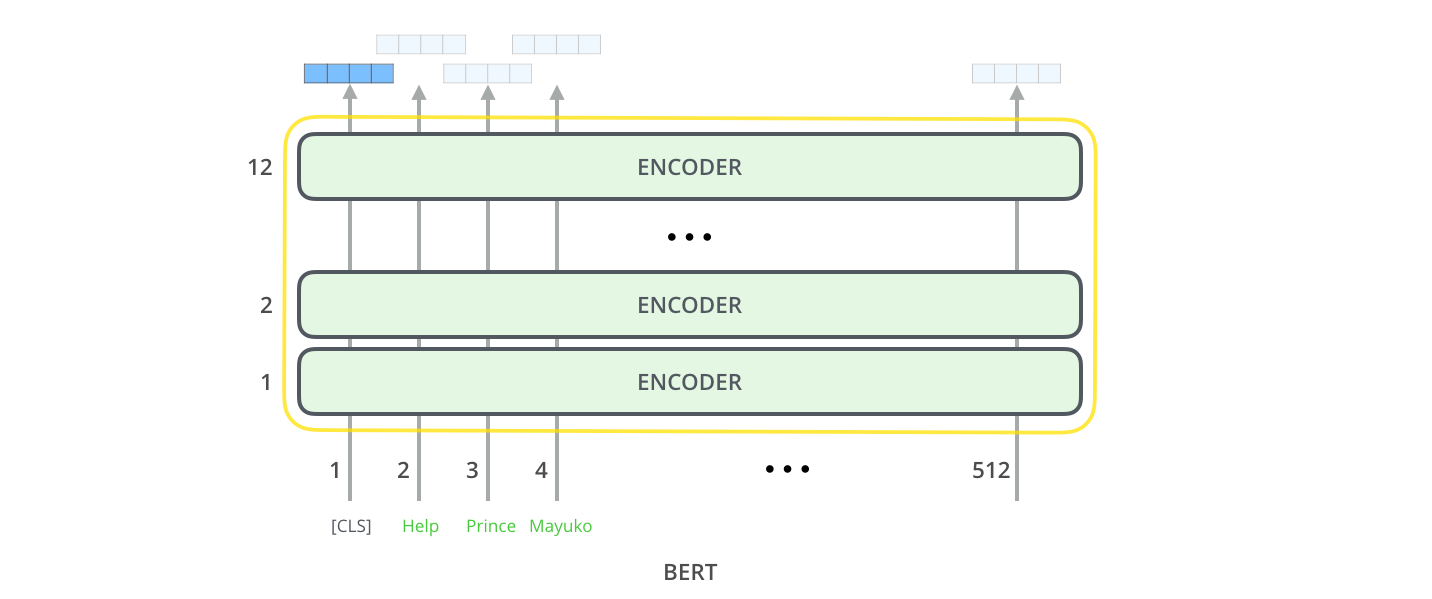
模型输入输出
Inputs
这里的Embedding由三种Embedding求和而成
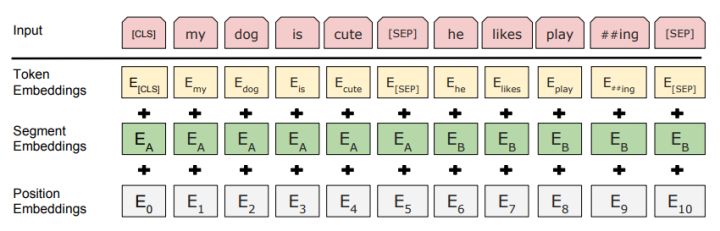
其中:
- Token Embeddings:是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings:和之前文章中的Transformer不一样,不是三角函数而是学习出来的
模型的每一层运行self-attention,然后将结果交给前向网络,再传输给下一个编码器
Outputs
每个位置输出一个\(hidden\_size\)大小的向量,对于分类任务,我们只关注第一个位置的输出([CLS]的位置)
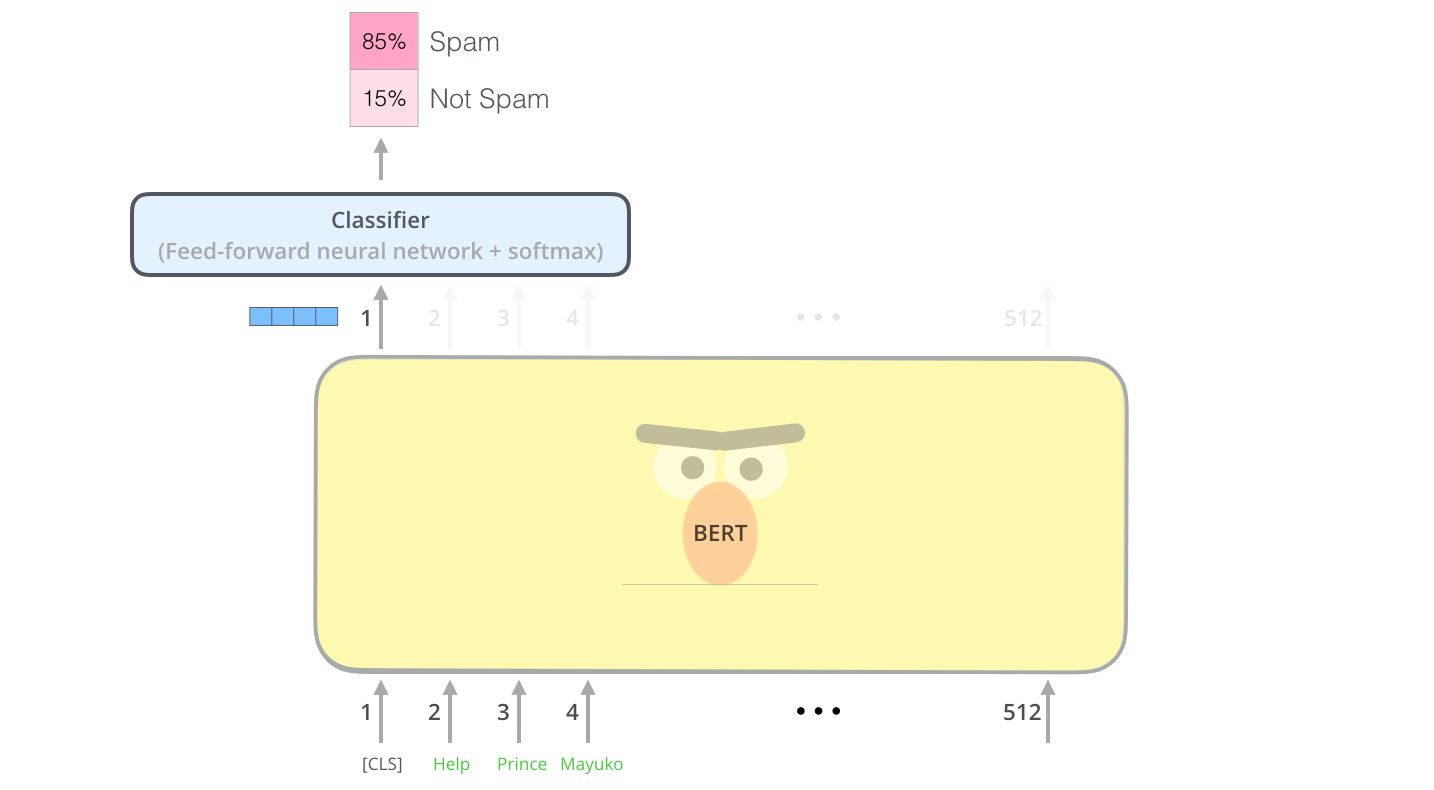
其他方法
ElMo
在对于预训练的词向量,每个词的词向量是固定的。但是ElMo的基本思想是,对于不同的上下文,同一个词有不同的含义。因此ElMo是感知语境的词向量。
ElMo使用一个双向LSTM基于特定的任务来得到上述词嵌入。通常的做法是,在大量的数据集上训练ElMo LSTM,然后将它作为其它模型的一个组件。
ElMo是通过预测序列的下一个词进行训练的,这个任务被称为语言建模(Language Modeling),这能充分利用大量的无标注数据。而且,ElMo训练了一个双向的LSTM,因此它的语言模型不仅能感知下一个词,也能感知上一个词。最终的上下文感知词嵌入是通过将隐藏状态加权求和而来的。如下图所示:

ULM-FiT
介绍了在各种任务上进行fine-tune的语言模型和流程,不仅仅是词向量和上下文感知的嵌入。
OpenAI Transformer
OpenAI Transformer只考虑了Transformer的decoder部分,叠加了12层的decoder层。
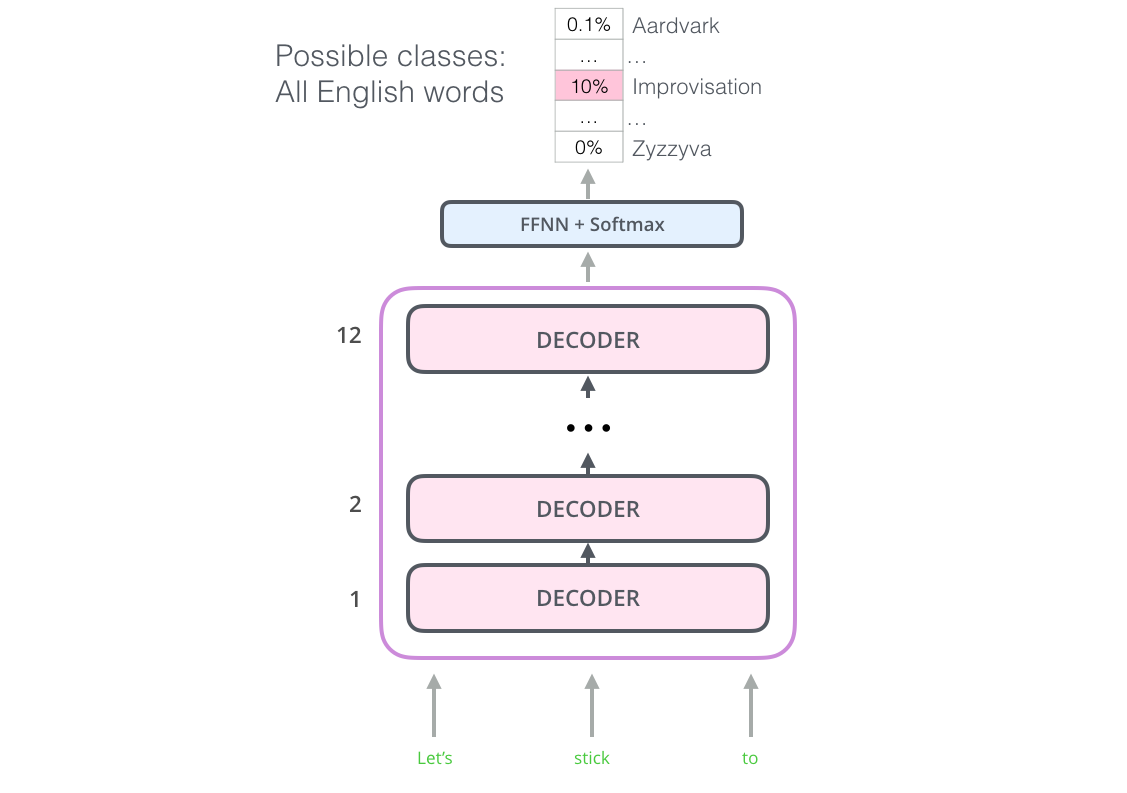
在预训练之后,OpenAI Transformer就能够用于夏有任务的迁移学习,对于不同任务的不同输入,OpenAI模型拥有不同的输入,下图是不同的任务:
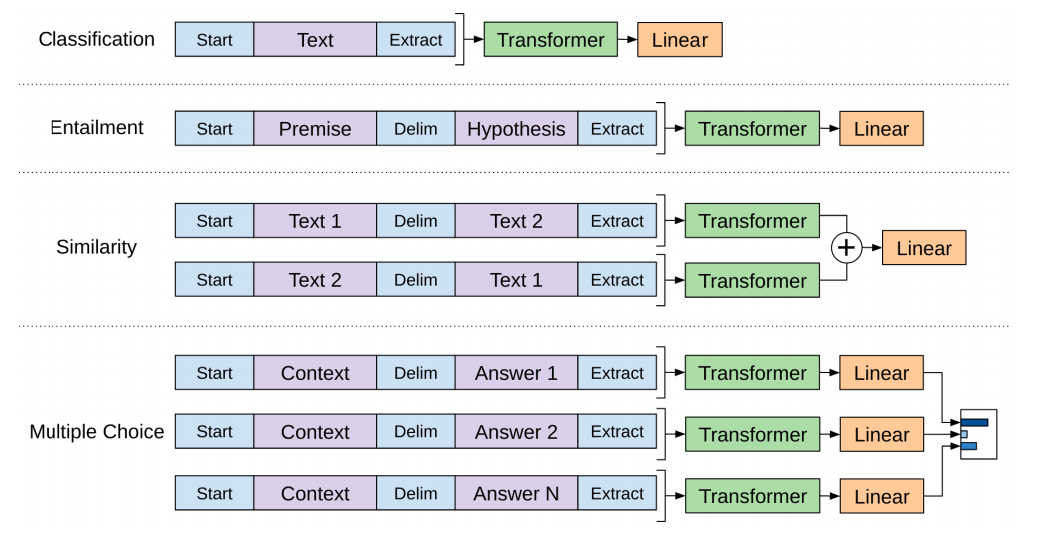
几种模型的比较
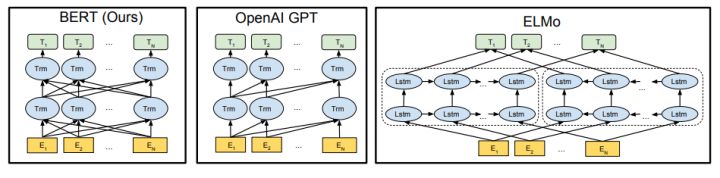
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ElMo,虽然都是“双向”,但目标函数其实是不同的。ElMo是分别以\(P(w_i| w_1,\cdots w_{i-1})\)和\(P(w_i|w_{i+1}, \cdots w_n)\)作为目标函数,独立训练处两个representation然后拼接,而BERT则是以\(P(w_i|w_1, \cdots ,w_{i-1}, w_{i+1},\cdots,w_n)\)作为目标函数训练语言模型
BERT: From Decoders to Encoders
OpenAI虽然基于Transformer给出了一个可以fine-tune的预训练模型,但是因为没有使用LSTM,丢失了部分信息(比如双向信息)。而ElMO利用双向LSTM,但是很复杂。因此BERT的想法就是,既基于Transformer模型,又能在语言模型中捕捉到前向和后向的信息。
Task 1: Masked Language Model
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即bidirectional。关于为什么要如此的bidirectional,作者在reddit上做了解释,意思就是如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。直觉上来讲我们其实想要一个deeply bidirectional的模型,但是普通的LM又无法做到。
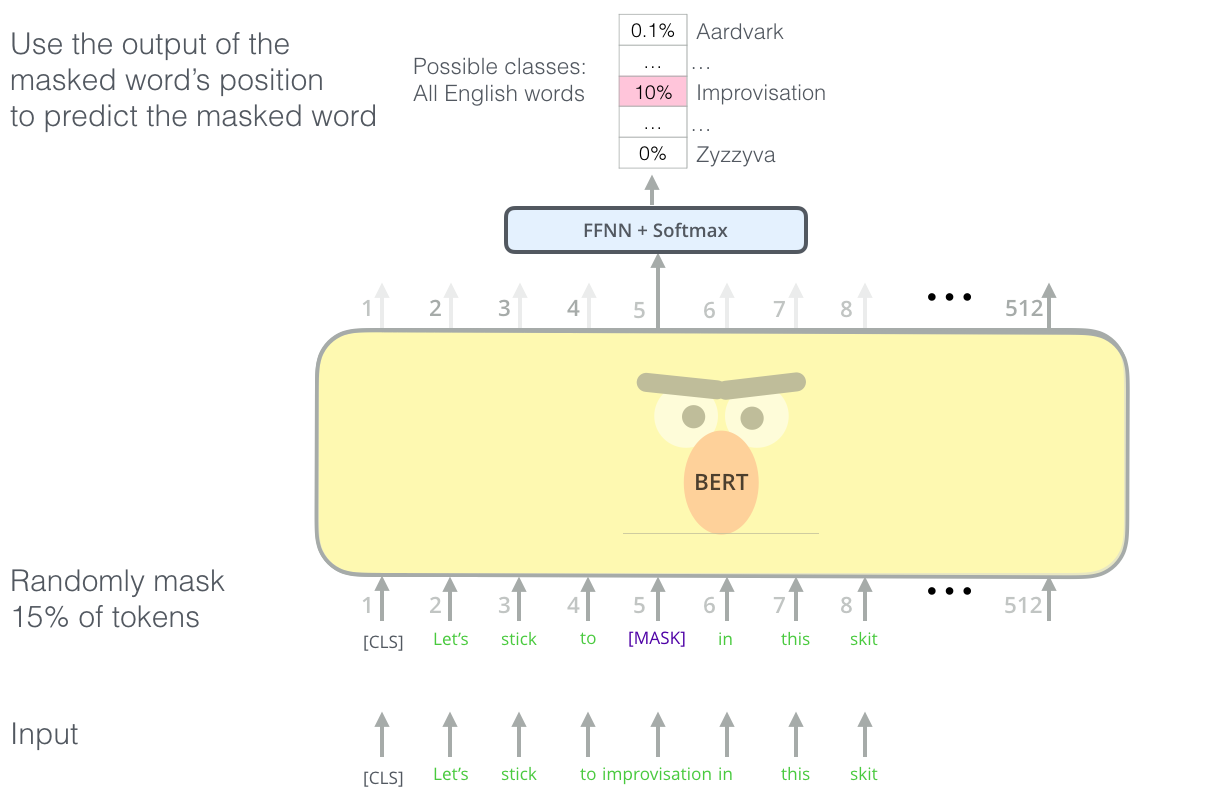
在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token
Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。具体为什么这么分配,作者没有说。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
Task 2: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。

注意,作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
Task specific-Models
对于不同的任务,BERT模型结构的使用有不同的方式,如下图所示:
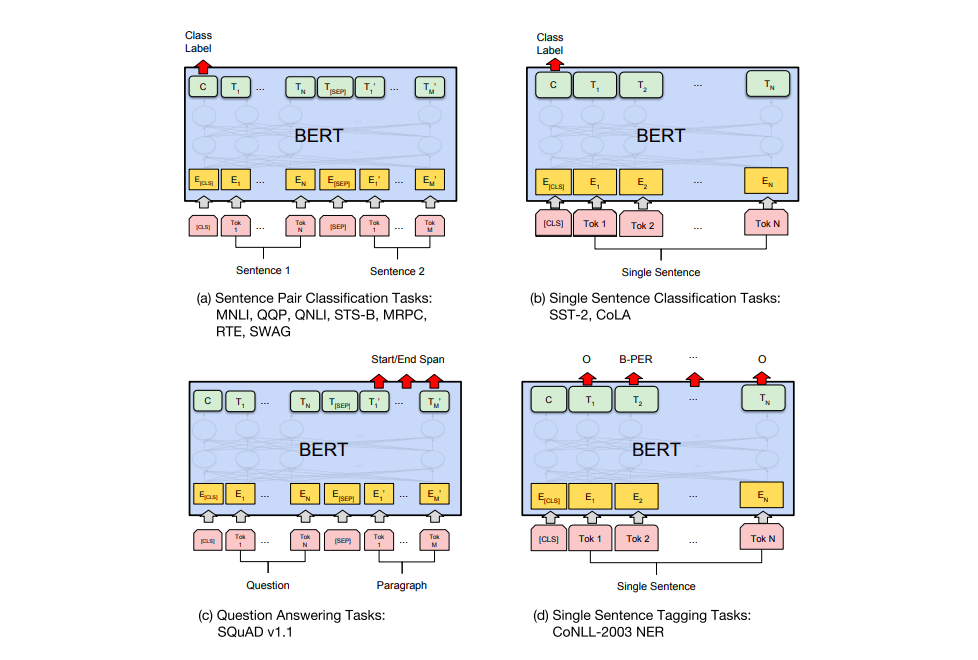
BERT for feature extraction
fine-tuning不是利用BERT的唯一方式。和ElMo一样,也可以使用BERT创建上下文感知的词向量,然后将这些向量feed到现有模型中使用。

究竟该用哪个向量作为上下文感知的嵌入,这应该取决于具体的任务。比如说高层特征和低层特征的区别。
Google BERT的更多相关文章
- Google BERT应用之《红楼梦》对话人物提取
Google BERT应用之<红楼梦>对话人物提取 https://www.jiqizhixin.com/articles/2019-01-24-19
- Google BERT摘要
1.BERT模型 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为dec ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- BERT模型的OneFlow实现
BERT模型的OneFlow实现 模型概述 BERT(Bidirectional Encoder Representations from Transformers)是NLP领域的一种预训练模型.本案 ...
- 用NVIDIA-NGC对BERT进行训练和微调
用NVIDIA-NGC对BERT进行训练和微调 Training and Fine-tuning BERT Using NVIDIA NGC 想象一下一个比人类更能理解语言的人工智能程序.想象一下为定 ...
- NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型 从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型.结合迁移学习,实现所要完成的NLP任务.谷歌在github上已经开放 ...
随机推荐
- pcl-设置多线段宽度和颜色
显示点云有使用vtk的,有使用 ros 中riz ?库的,使用pcl显示点云数据比较方便,但是对于一些模型形状只能固定特定的效果,比如说直线段,只能绘制点到点两点之间的线段.但是项目需要绘制点1到点2 ...
- CODE FESTIVAL 2017 qual C 题解
传送门 \(A\) 咕咕 const int N=15; char s[N];int n; int main(){ scanf("%s",s+1),n=strlen(s+1); f ...
- (15)打鸡儿教你Vue.js
组件化vue.js 组件单向绑定 组件双向绑定 组件单次绑定 创建组件构造器 注册组件 使用组件 Vue.extend() Vue.component() 使用组件 <div id=" ...
- C/C++输入
fgets(str,n,stdin) 从键盘输入一行,替代gets().读取到n-1字节时或换行符时终止,如果是文件的话,读到文件结尾也会停止 getline(cin,str) str的类型必须是st ...
- [FUZZ]文件上传fuzz字典生成脚本—使用方法
文件上传fuzz字典生成脚本-使用方法 原作者:c0ny1 项目地址:https://github.com/c0ny1/upload-fuzz-dic-builder 项目预览效果图: 帮助手册: 脚 ...
- 三大框架 之 Spring(IOC控制反转、DI依赖注入)
目录 常用词汇 left join与left outer join的区别 Struts2的标签库导入 Spring Spring概述 什么是Spring spring特点 下载 IOC 什么IOC 传 ...
- 2019软工实践_Alpha(3/6)
队名:955 组长博客:https://www.cnblogs.com/cclong/p/11872693.html 作业博客:https://edu.cnblogs.com/campus/fzu/S ...
- Diffie-Hellman算法简介
一.DH算法是一种密钥交换协议,它可以让双方在不泄漏密钥的情况下协商出一个密钥来. DH算法基于数学原理,比如小明和小红想要协商一个密钥,可以这么做: . 小明先选一个素数和一个底数,例如,素数p=, ...
- 网络通信技术中的中继器repeater
1. repeater的作用 对信号进行再生和还原 2. repeater的优点 延长通讯距离 提高可靠性 增加节点的最大数目 各个网段可以使用不同的通讯速率 3. repeater的缺点 增加了延时 ...
- [转]地理投影,常用坐标系详解、WGS84、WGS84 Web墨卡托、WGS84 UTM、北京54坐标系、西安80坐标系、CGCS2000坐标系
转自:http://www.rivermap.cn/docs/show-1829.html 常用坐标系详解 (一)WGS84坐标系 WGS-84坐标系(World Geodetic System一19 ...