Google BERT摘要
1.BERT模型
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1.1 模型结构
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
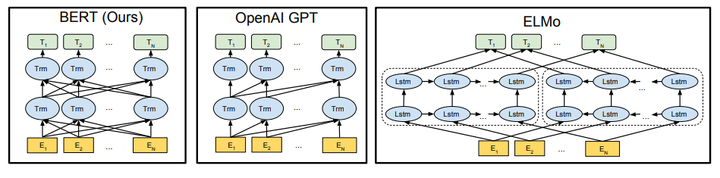
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
1.2 Embedding
这里的Embedding由三种Embedding求和而成:
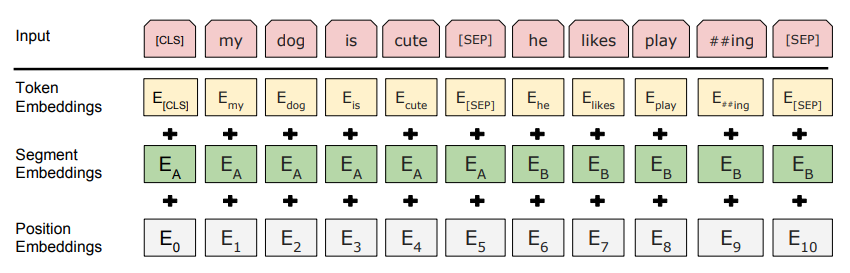
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
总结:
1. BERT的特征提取,是在捕捉词的(前后)位置关系。bidirectional决定了能获得前后的关系,position embedding决定了能学到更长的顺序关系。
2.训练,分为pre-train和fine-tune。pre-train中用到了MLM, Masked LM.
3. trick: MLM. 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
4. 缺点: (1)[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
(2)每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
https://zhuanlan.zhihu.com/p/46652512
https://arxiv.org/pdf/1810.04805.pdf
Google BERT摘要的更多相关文章
- Google BERT应用之《红楼梦》对话人物提取
Google BERT应用之<红楼梦>对话人物提取 https://www.jiqizhixin.com/articles/2019-01-24-19
- Google BERT
概述 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不 ...
- HTML5扩展之微数据与丰富网页摘要
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- HTML5扩展之微数据与丰富网页摘要itemscope, itemtype, itemprop
HTML5扩展之微数据与丰富网页摘要 by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpr ...
- HTML5扩展之微数据与丰富网页摘要——张鑫旭
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- Google论文BigTable拜读
这周少打点dota2,争取把这篇论文读懂并呈现出来,和大家一起分享. 先把论文搞懂,然后再看下和论文搭界的知识,比如hbase,Chubby和Paxos算法. Bigtable: A Distribu ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
随机推荐
- pg_flame postgresql EXPLAIN ANALYZE 火焰图工具
pg_flame 是golang 编写的一个将pg的EXPLAIN ANALYZE 转换为火焰图,使用简单 以下是一个简单的demo 环境准备 docker-compose 文件 version: ...
- 格式化输出(%用法和fomat用法)
一:%用法 1.整数输出 %o —— oct 八进制%d —— dec 十进制%x —— hex 十六进制 2.浮点数输出 %f ——保留小数点后面六位有效数字 %.3f,保留3位小数位%e ——保留 ...
- gitlab 从古老的 bitnami 版本 迁移到官方最新版本
这是我之前发布在 yuque 的文章.是我刚来新公司的时候帮公司搬迁 git 记录下来的,现在看来去掉敏感部分直接发布也没啥问题啦,就搬家过来,我自己也方便查 XD . 8.1.6 -> 10. ...
- SDL
SDL介绍 SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成.SDL提供了数种控制图像.声音.输出入的函数,让开发者只要用相同或是相似的代 ...
- 出现 java.lang.OutOfMemoryError: PermGen space 错误的原因及解决方法
一.原因及解决方法[1] 1.原因:堆内存的永久保存去区内存分配不足(缺省默认为64M),导致内存溢出错误. 2.解决方法:重新分配内存大小,-Xms1024M -Xmx2048M -XX:PermS ...
- Writeup:第五届上海市大学生网络安全大赛-Web
目录 Writeup:第五届上海市大学生网络安全大赛-Web 一.Decade 无参数函数RCE(./..) 二.Easysql 三.Babyt5 二次编码绕过strpos Description: ...
- [Beta阶段]第十一次Scrum Meeting
Scrum Meeting博客目录 [Beta阶段]第十一次Scrum Meeting 基本信息 名称 时间 地点 时长 第十一次Scrum Meeting 19/05/20 大运村寝室6楼 15mi ...
- Kibana自动关联ES索引
原因: Kibana中关联ES索引需要手动操作,如果ES中索引较多(如每天生成),则工作量会比较大. 方法: 考虑使用Linux的cron定时器自动关联ES索引,原理是调用Kibana API接口自动 ...
- Why you need to understand garbage collection
Why you need to understand garbage collection I’ve been interviewing lots of C# developers recently, ...
- Windows通过URL启动本机App
Windows通过URL启动本机App http://xxx.itdhz.com/?file=001-Windows/100-Windows通过URL启动本机App