Hadoop的简单使用
Hadoop的简单使用
- 使用Hadoop提供的命令行,向文件系统中创建一个文件。
./hadoop fs -put temp.txt hdfs://localhost:8888/
说明:
- ./hadoop 是bin目录下
- fs 表明对文件系统进行操作
- -put 就是传输
- temp.txt 是我要传输的文件
- hdfs://localhost:8888 是hdfs的入口
检测是否成功上传:
然后点击browse the filesystem
可以看到:

一个简单的MapReduce任务
任务说明: 使用Hadoop自动的一个案例,来统计多个文件的的各个单词出现的次数。
步骤如下:
- 通过ssh上传一些文件。为了方便,我们最好上传文本文件。从 apache的extra目录下把文件上传到ubuntu下

- 将这些文件上传到hadoop的文件系统
2.1先创建一个目录
./hadoop fs -mkdir /task1 【如果要看 hadoop有哪些指令,可以 ./hadoop 如果要看 还可以通过 ./hadoop fs 来看分项的命令】
- 将 /home/hsp/test 的所有文件上传到 /task1目录下
./hadoop fs -put /home/hsp/test/*.* /task1
- 执行一个MapReduce任务,这个是已经写好的,自带的,后面详解,现在体验
./bin/hadoop jar hadoop-examples-1.0.3.jar wordcount /task1 /result1
说明:这个指令一定要在 hadoop的bin目录下执行,因为 hadoop-examples-1.0.3.jar 是在hadoop/bin 目录下的.
结果:

- 验证是否正确
http://localhost:50030 , [这个就是MapReduce的管理界面]可以看到MapReduce 任务的完成情况

点击job_201506...可以看到详细情况,如下:
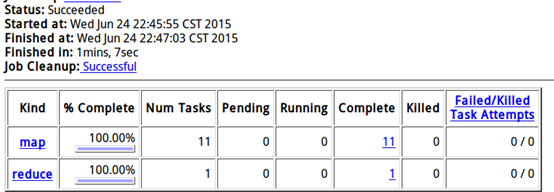
说明: 这个任务被Map了11个,有一个reduce操作。
http://localhost:50070 ,点击 part-r-00000 ,就可以看到结果
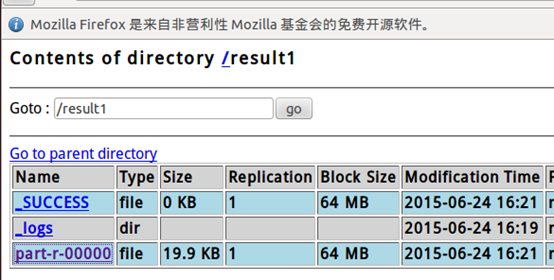
both 是5次,我们在ubuntu 直接统计一下
grep both /home/hsp/test/*.* 可以看到一个5个
grep both /home/hsp/test/*.*|wc 也可以直接得到结果.
Hadoop的简单使用的更多相关文章
- 结合Hadoop,简单理解SSH
在启动dfs和yarn时,需要多次输入密码,不但启动本机进程还有辅服务器启动那些节点也需要相应密码,主与辅服务器之间是通过SSH连接的,并发送操作指令 一.ssh密码远程登录 1.使用ssh连接另一台 ...
- Linux下Hadoop的简单安装
Hadoop 的安装极为简单,一共只有三步: 安装JDK 安装Hadoop 配置Hadoop 1,安装JDK 下载JDK,ftp传到linux或者linux中下载 切换 ...
- Hadoop RPC简单例子
jdk中已经提供了一个RPC框架-RMI,但是该PRC框架过于重量级并且可控之处比较少,所以Hadoop RPC实现了自定义的PRC框架. 同其他RPC框架一样,Hadoop RPC分为四个部分: ( ...
- Hadoop之简单文件读写
文件简单写操作: import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream ...
- Hadoop RPC简单实例
1.导入Hadoop-Common-2.6.0.jar导入工程,里面的IPC实现RPC需要的文件. 2.服务器端 (1)服务接口 package com.neu.rpc.server; /** * ...
- (7)基于hadoop的简单网盘应用实现3
一.login.jsp登陆界面实现 解压bootmetro-master.zip,然后将\bootmetro-master\src\下的assets目录复制到project里. bootmetro下载 ...
- hadoop mapreduce 简单例子
本例子统计 用空格分开的单词出现数量( 这个Main.mian 启动方式是hadoop 2.0 的写法.1.0 不一样 ) 目录结构: 使用的 maven : 下面是maven 依赖. <de ...
- Hadoop的简单序列化框架
Hadoop提供了一个加单的序列化框架API,用于集成各种序列化实现.该框架由Serialization实现. 其中Serialization是一个接口,使用抽象工厂的设计模式,提供了一系列和序列化相 ...
- Hadoop的简单了解与安装
hadoop 一, Hadoop 分布式 简介Hadoop 是分布式的系统架构,是 Apache 基金会顶级金牌项目 分布式是什么?学会用大数据的思想来看待和解决问题 思 想很重要 1-1 . ...
随机推荐
- POJ 1470 Closest Common Ancestors (LCA, dfs+ST在线算法)
Closest Common Ancestors Time Limit: 2000MS Memory Limit: 10000K Total Submissions: 13370 Accept ...
- tracef 安装 跟踪 函数调用图
http://www.prevanders.net/dwarf.html redhat 5.4 tar -zxvf libdwarf-20140519.tar.gz [root@localhost d ...
- Linux- systemd
systemd被设计用来改进sysvinit的缺点,它和ubuntu的upstart是竞争对手,预计会取代它们.systemd的很多概念来源于苹果的launchd.创始人Lennart是redhat员 ...
- Pig系统分析(5)-从Logical Plan到Physical Plan
Physical Plan生成过程 优化后的逻辑运行计划被LogToPhyTranslationVisitor处理,生成物理运行计划. 这是一个经典的Vistor设计模式应用场景. 当中,LogToP ...
- AndroidMainifest标签使用说明1——<action>
1.<action> 格式: <action android:name="string" /> 父标签: <intent-filter> 描写叙 ...
- python笔记26-命令行传参sys.argv实际运用
前言 平常我们在用别人写好的python包的时候,在cmd输入xx -h就能查看到帮助信息,输入xx -p 8080就能把参数传入程序里,看起来非常酷. 本篇就来讲下如何在python代码里加入命令行 ...
- Python垃圾回收机制及gc模块详解:内存泄露的例子
标记清理是用来解决循环引用的.分代回收针对所有的新创建即进入0代的对象和进入1.2代的对象..这样就解释了python“引用计数为主.标记清理+分代回收为辅”的垃圾回收原理,因为循环引用毕竟是少数情况 ...
- SQL Server中的database checkpoint
基于性能方面的考虑, 数据库引擎会在内存(buffer cache)中执行数据库数据页(pages)的修改, 不会再每次做完修改之后都把修改了的page写回到磁盘上. 更准确的说, 数据库引擎定期在每 ...
- 通过小实例谈谈javascript的间隔调用和延时调用
用 setInterval方法可以以指定的间隔实现循环调用函数,直到clearInterval方法取消循环 用clearInterval方法取消循环时,必须将setInterval方法的调用赋值给一个 ...
- Andorid之ActivityManager
在Android中ActivityManager主要用于和系统中运行的Activities进行交互.在本篇文章中,我们将对ActivityManager中的API进行研究使用. 在ActivityMa ...