An overview of gradient descent optimization algorithms (更新到Adam)
Momentum:解快了收敛速度,同时也减弱了SGD的波动
NAG: 减速了Momentum更新参数太快
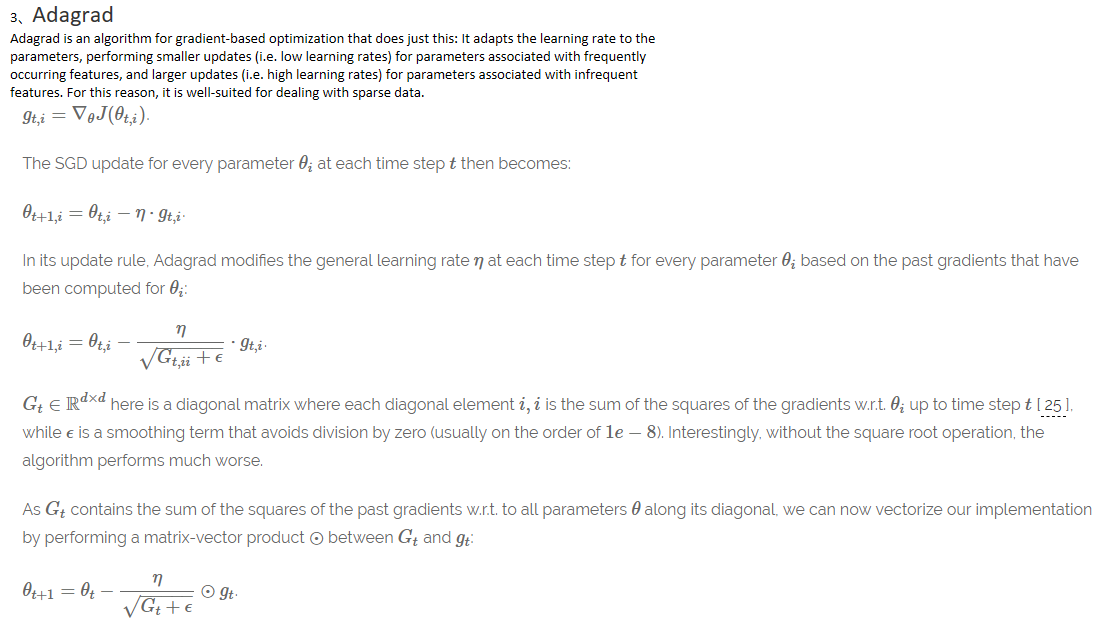
Adagrad: 出现频率较低参数采用较大的更新,对于出现频率较高的参数采用较小的,不共用一个学习率
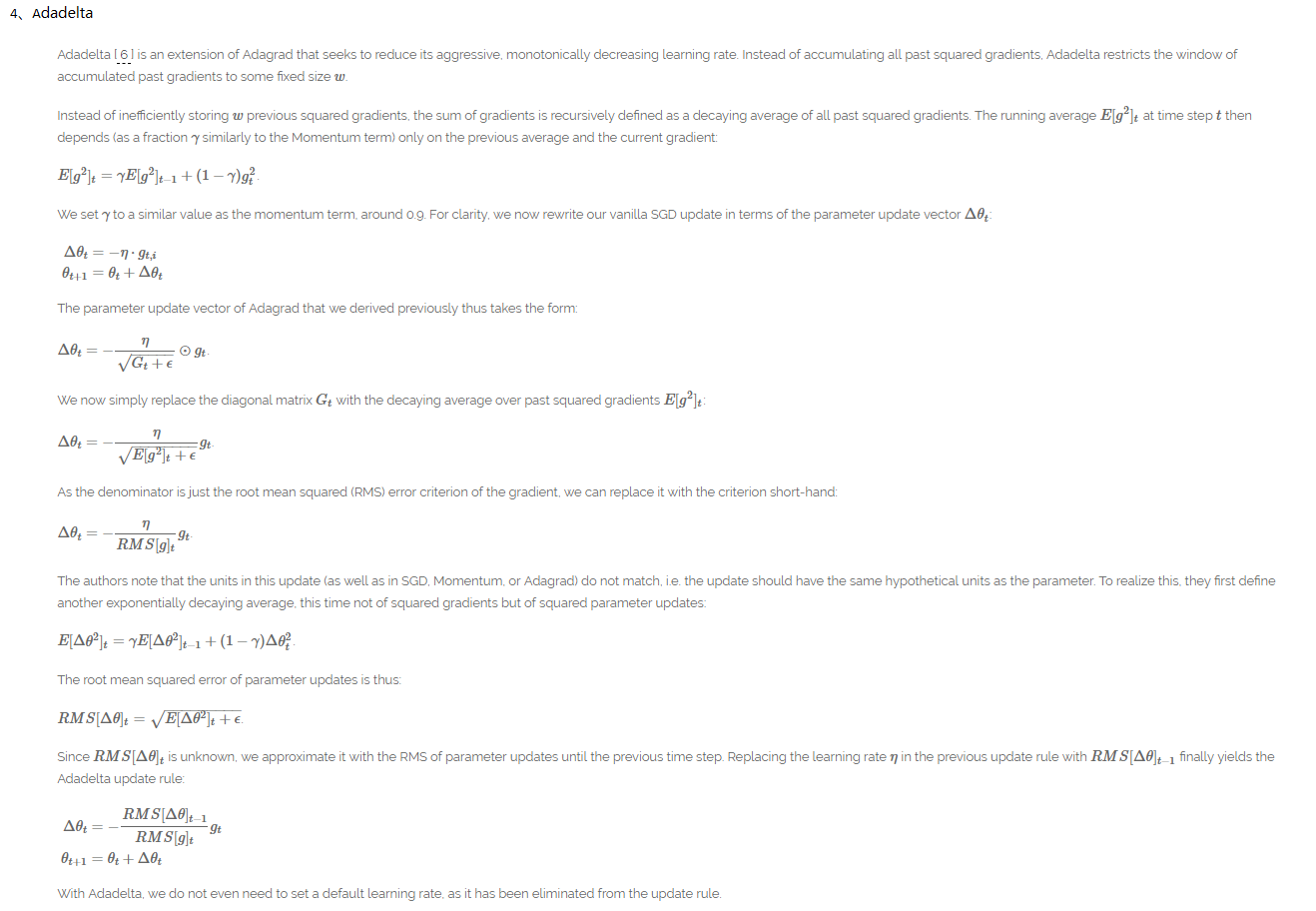
Adadelta:解决了Adagrad后续学习率为0的缺点,同时不要defalut 学习率
RMSprop:解决了Adagrad后续学习率为0的缺点
Adam: 结合了RMSprop和Momentum的优点,Adam might be the best overall choice
参考博客:http://ruder.io/optimizing-gradient-descent/index.html#batchgradientdescent(真大神)




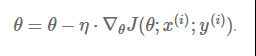


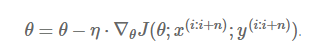





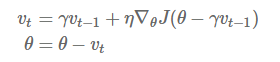

An overview of gradient descent optimization algorithms (更新到Adam)的更多相关文章
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- [Converge] Gradient Descent - Several solvers
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}, default: ‘liblinear’ Algorithm to use in the op ...
- [C2W2] Improving Deep Neural Networks : Optimization algorithms
第二周:优化算法(Optimization algorithms) Mini-batch 梯度下降(Mini-batch gradient descent) 本周将学习优化算法,这能让你的神经网络运行 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
随机推荐
- Python 使用CPickle和pickle模块进行序列化和反序列化
#Cpickle使用C语言进行编写的相比pickle来说效率高很多 #-*-coding:utf-8-*-'''序列化操作'''try: import cPickle as pickleexce ...
- 书架 bookshelf
书架 bookshelf 题目描述 当Farmer John闲下来的时候,他喜欢坐下来读一本好书. 多年来,他已经收集了N本书 (1 <= N <= 100,000). 他想要建立一个多层 ...
- BUG1 解决java compiler level does not match the version of the installed java project facet
因工作的关系,Eclipse开发的Java项目拷来拷去,有时候会报一个很奇怪的错误.明明源码一模一样,为什么项目复制到另一台机器上,就会报“java compiler level does not m ...
- MVC中数据验证
http://www.studyofnet.com/news/339.html http://www.cnblogs.com/kissdodog/archive/2013/05/04/3060278. ...
- 字符串连接比较(std::unique_ptr实现)
比较代码之间可能相差大,可是速度相差很大,而且目的在于测试unique_ptr使用...; C/C++: #include <iostream> std::unique_ptr<ch ...
- Netlink 介绍(译)
原文地址:http://people.redhat.com/nhorman/papers/netlink.pdf 译文: 1 介绍 在Linux和Unix的众多发行版中的网络配置功能, 都是编程者事后 ...
- bzoj 4919 [Lydsy1706月赛]大根堆 set启发式合并+LIS
4919: [Lydsy1706月赛]大根堆 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 599 Solved: 260[Submit][Stat ...
- 使用前端组件化思想修改todolist
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Nginx模块Lua-Nginx-Module学习笔记(一)Nginx Lua API 接口详解
源码地址:https://github.com/Tinywan/Lua-Nginx-Redis 一.介绍 各种* _by_lua,* _by_lua_block和* _by_lua_file配置指令用 ...
- php设计模式之工厂设计模式
概念: 工厂设计模式提供获取某个对象的新实例的一个接口,同时使调用代码避免确定实际实例化基类步骤. 很多高级模式都是依赖于工厂模式. 好处: PHP中能够创建基于变量内容 ...