An overview of gradient descent optimization algorithms (更新到Adam)
Momentum:解快了收敛速度,同时也减弱了SGD的波动
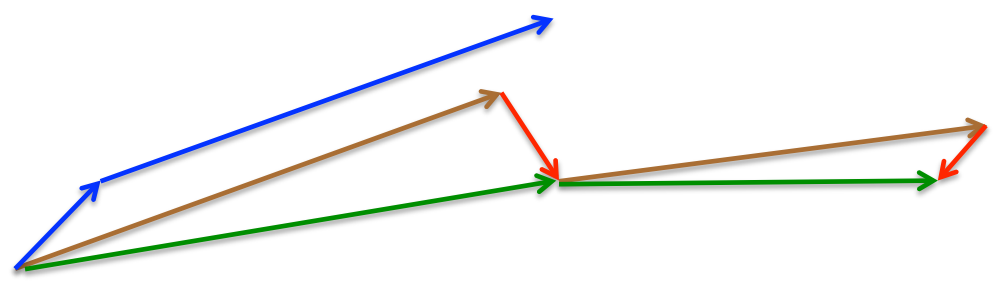
NAG: 减速了Momentum更新参数太快
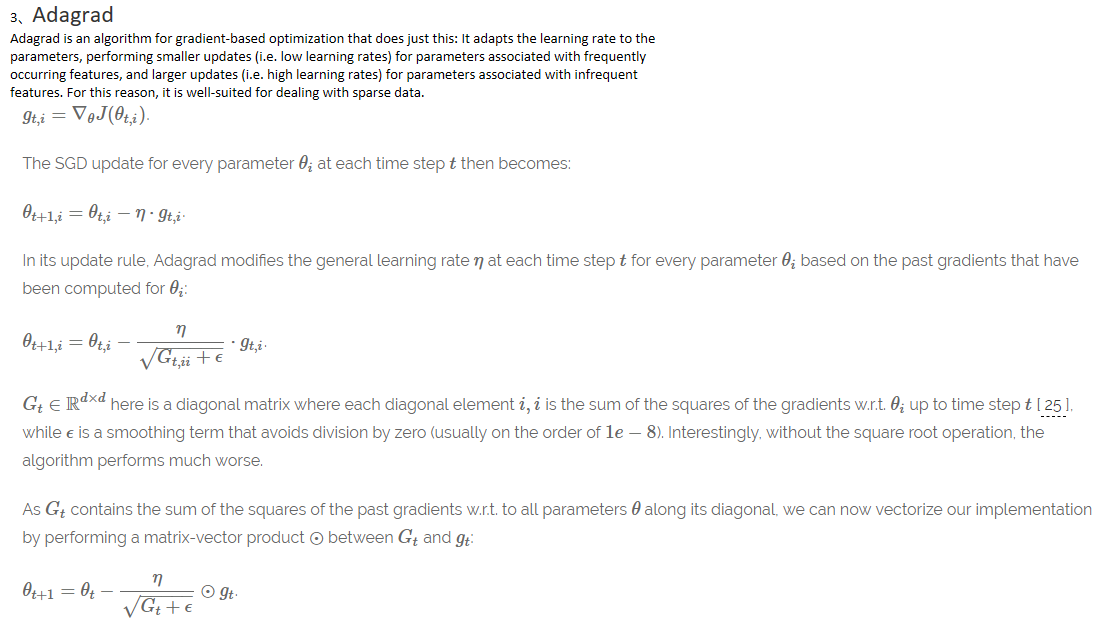
Adagrad: 出现频率较低参数采用较大的更新,对于出现频率较高的参数采用较小的,不共用一个学习率
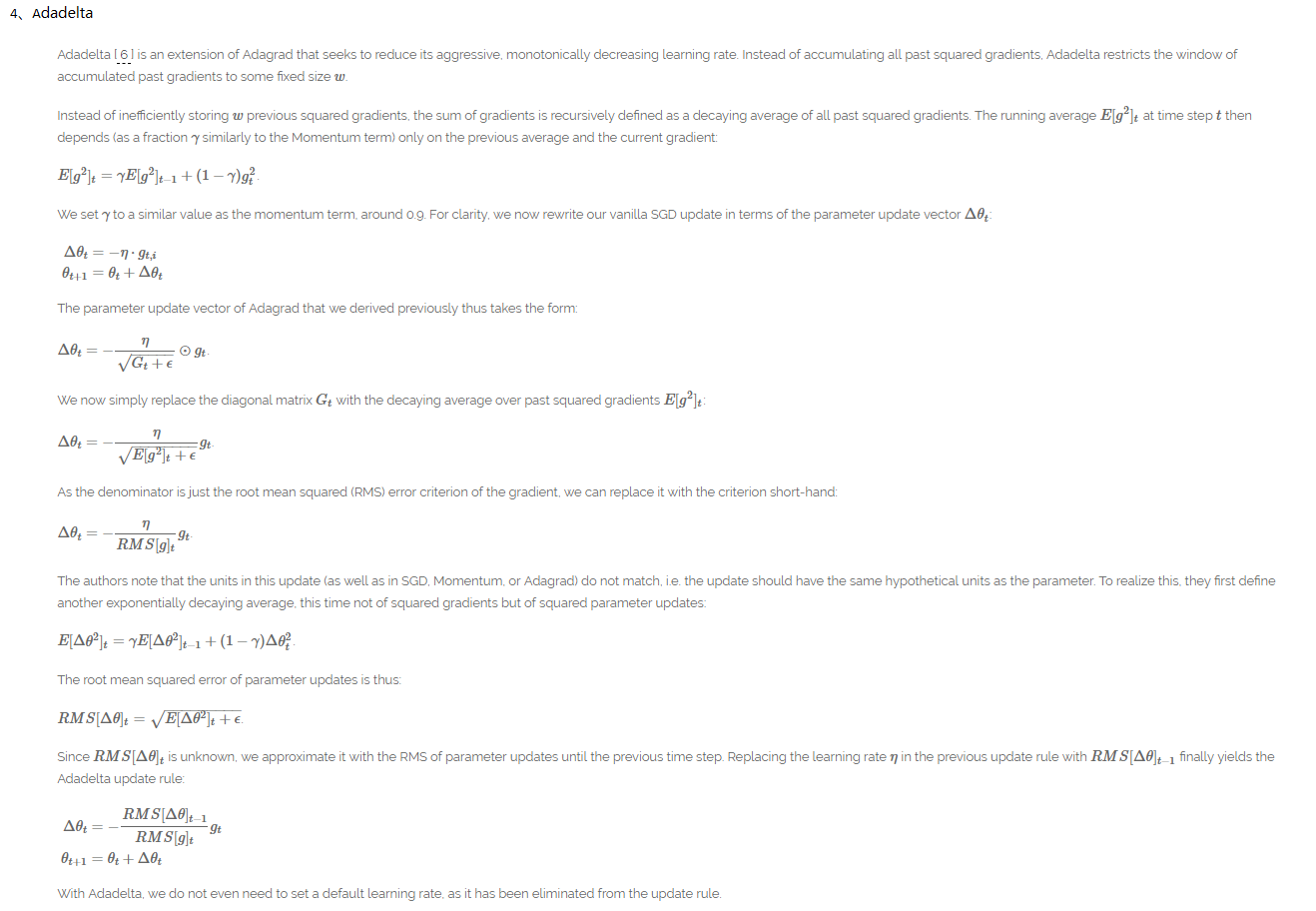
Adadelta:解决了Adagrad后续学习率为0的缺点,同时不要defalut 学习率
RMSprop:解决了Adagrad后续学习率为0的缺点
Adam: 结合了RMSprop和Momentum的优点,Adam might be the best overall choice
参考博客:http://ruder.io/optimizing-gradient-descent/index.html#batchgradientdescent(真大神)




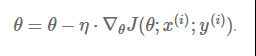


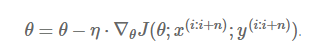





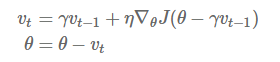

An overview of gradient descent optimization algorithms (更新到Adam)的更多相关文章
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- [Converge] Gradient Descent - Several solvers
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}, default: ‘liblinear’ Algorithm to use in the op ...
- [C2W2] Improving Deep Neural Networks : Optimization algorithms
第二周:优化算法(Optimization algorithms) Mini-batch 梯度下降(Mini-batch gradient descent) 本周将学习优化算法,这能让你的神经网络运行 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
随机推荐
- 【BZOJ1502】【NOI2005】月下柠檬树
Portal 传送门 Solution 显然的是,每一个圆的影子,就是从树上的圆按光线方向平移至地面的圆.至于两个圆之间的连接部分,则是每两个在树上相邻的圆的,对应的影子圆的,公切线围起来的部分,如下 ...
- 解题:CF825E Minimal Labels
题面 看起来似乎是个水水的拓扑排序+堆,然而并不对,因为BFS拓扑排序的话每次只会在“当前”的点中排出一个最小/大的字典序,而我们是要一个确定的点的字典序尽量小.正确的做法是反向建图,之后跑一个字典序 ...
- lumen 使用 dingo API 在 phpunit 中 404 的解决方法, 以及鉴权问题
1. phpunit.xml 中添加 dingo 相关配置 <env name="API_STANDARDS_TREE" value="x"/> & ...
- laravel 数据库迁移转 sql 语句
可以使用下面的命令 php artisan migrate --pretend --no-ansi 当然,你需要有可以 migrate 的东西. 数据库迁移导出到文件(使用命令) <?php n ...
- 「Vue」Vue cli3中引用mui-ui问题及解决办法
1.引用mui.js无效,top-bar划动,numbox点击无效等问题 解决办法: -main.js中import mui from './lib/mui/js/mui.js' Vue.protot ...
- python---基础知识回顾(八)数据库基础操作(sqlite和mysql)
一:sqlite操作 SQLite是一种嵌入式数据库,它的数据库就是一个文件.由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以 ...
- Bzoj1939 [Croatian2010] Zuma
Time Limit: 4 Sec Memory Limit: 64 MBSubmit: 43 Solved: 31 Description 有一行 N 个弹子,每一个都有一个颜色.每次可以让超过 ...
- 20155315 2016-2017-2 《Java程序设计》第五周学习总结
教材学习内容总结 第8章 异常处理 1.使用try...catch 与C语言中程序流程和错误处理混在一起不同,Java中把正常流程放try块中,错误(异常)处理放catch块中. 如果父类异常对象在子 ...
- Tetrahedron(Codeforces Round #113 (Div. 2) + 打表找规律 + dp计数)
题目链接: https://codeforces.com/contest/166/problem/E 题目: 题意: 给你一个三菱锥,初始时你在D点,然后你每次可以往相邻的顶点移动,问你第n步回到D点 ...
- llg的农场(farm)
评测传送门 [题目描述] llg 是一名快乐的农民,他拥有一个很大的农场,并且种了各种各样的瓜果蔬菜,到了每年秋天,他就可以把所有蔬菜水果卖到市场上,这样他就可以获利.但今年他遇到了一个难题——有许多 ...