Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match
最近在用python做数据挖掘,在聚类的时候遇到了一个非常恶心的问题。话不多说,直接上代码:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
#kmeans算法
df1=df23
kmeans = KMeans(n_clusters=5, random_state=10).fit(df1)
#贴上每个样本对应的簇类别标签
df1['level']=kmeans.labels_
#df1.to_csv('new_df.csv') df2=df1.groupby('level',as_index=False)['level'].agg({'num': np.size})
print(df2.head()) #将用于聚类的数据的特征的维度降至2维
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(df1))
print(new_pca.head()) #可视化
d = new_pca[df1['level'] == 0]
plt.plot(d[0], d[1], 'gv')
d = new_pca[df1['level'] == 1]
plt.plot(d[0], d[1], 'ko')
d = new_pca[df1['level'] == 2]
plt.plot(d[0], d[1], 'b*')
d = new_pca[df1['level'] == 3]
plt.plot(d[0], d[1], 'y+')
d = new_pca[df1['level'] == 4]
plt.plot(d[0], d[1], 'c.') plt.title('the result of polymerization')
plt.show()
错误如下:

网上找了好久都没找到解决方法,明明之前成功过的。于是我查看了df23数据,发现它是这样的:
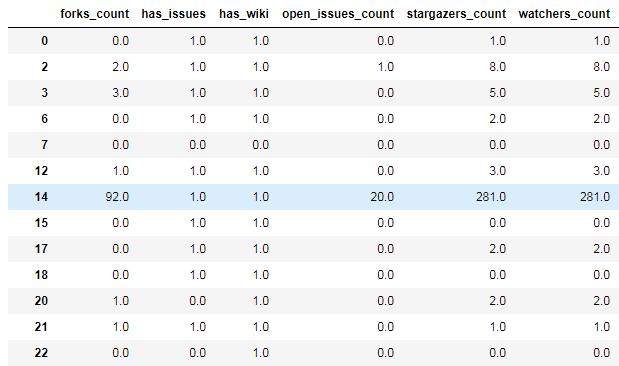
与之前成功的dataframe的唯一差别就是索引!!!重要的事情说三遍!!!索引!!!索引!!!于是乎,我去找怎么重置索引的方法,见代码:
df24=df23[["forks_count","has_issues","has_wiki","open_issues_count","stargazers_count","watchers_count","created_pushed_time","created_updated_time"]]
df24=df24.reset_index()
df24=df24[["forks_count","has_issues","has_wiki","open_issues_count","stargazers_count","watchers_count","created_pushed_time","created_updated_time"]]
然后聚类就成功了。。。心累。。。。
Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match的更多相关文章
- pandas之Seris和DataFrame
pandas是一个强大的python工具包,提供了大量处理数据的函数和方法,用于处理数据和分析数据. 使用pandas之前需要先安装pandas包,并通过import pandas as pd导入. ...
- pandas中的Series
我们使用pandas经常会用到其下面的一个类:Series,那么这个类都有哪些方法呢?另外Series和DataFrame都继承了NDFrame这个类,df.to_sql()这个方法其实就是NDFra ...
- [简单]docx4j常用方法小结
http://53873039oycg.iteye.com/blog/2194479?utm_source=tuicool&utm_medium=referral —————————————— ...
- Android Folding View(折叠视图、控件)
版本号:1.0 日期:2014.4.21 版权:© 2014 kince 转载注明出处 非常早之前看过有人求助以下这个效果是怎样实现的, 也就是側滑菜单的一个折叠效果,事实上关于这个效果的实现,谷 ...
- 深入理解Android中ViewGroup
文章目录 [隐藏] 一.ViewGroup是什么? 二.ViewGroup这个容器 2.1 添加View的算法 2.1.1 我们先来分析addViewInner方法: 2.1.2 addInArr ...
- dev简单实现柱状图,曲线图
1.数据源代码: DataTable dt = new DataTable(); dt.Columns.Add("A"); dt.Columns.Add("B" ...
- 【docx4j】docx4j操作docx,实现替换内容、转换pdf、html等操作
主要是想要用此功插件操作docx,主要的操作就是操作段落等信息,另外,也想实现替换docx的内容,实现根据模板动态生成内容的效果,也想用此插件实现docx转换pdf. word的格式其实可以用xml来 ...
- CopyOnWriteList-JDK1.8
CopyOnWrite,一个写时复制的技术来保证并发操作的安全,使用这种技术的前提是读大于写. 读读之间相容, 写写之间互斥, 读写操作相容. 实现方法: 在对底层数据进行写的时候,把底层数据复制一份 ...
- 推荐系统之基于图的推荐:基于随机游走的PersonalRank算法
转自http://blog.csdn.net/sinat_33741547/article/details/53002524 一 基本概念 基于图的模型是推荐系统中相当重要的一种方法,以下内容的基本思 ...
随机推荐
- NYOJ 数独 DFS
数独 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 数独是一种运用纸.笔进行演算的逻辑游戏.玩家需要根据9×9盘面上的已知数字,推理出所有剩余空格的数字,并满足每一 ...
- Linux块设备和字符设备
块设备:系统能够随机无序访问固定大小的数据片的设备,这些数据片称为块.块设备是以固定大小长度来传送资料的,它使用缓冲区暂存数据,时机成熟后从缓存中一次性写入到设备或者从设备中一次性放到缓存区.常见的块 ...
- CentOS 7快速入门系列教程(一)
基本命令 ls 列举当前目录下的所有文件夹 ls -l 查看文件还是文件夹 d表示文件夹 -表示文件 ls --help man ls 询问命令 man 3 malloc 查看函数 cd 跳转 ...
- java后台代码发送邮件
1:安装 eyoumailserversetup 易邮邮件服务器 注册账号 2:安装Foxmail 登录以后会有个还原页面 3:测试 4:java 代码编写 配置文件: mail.host=http ...
- Concat层解析
Concat层的作用就是将两个及以上的特征图按照在channel或num维度上进行拼接,并没有eltwise层的运算操作,举个例子,如果说是在channel维度上进行拼接conv_9和deconv_9 ...
- 【codeforces】【比赛题解】#948 CF Round #470 (Div.2)
[A]Protect Sheep 题意: 一个\(R*C\)的牧场中有一些羊和一些狼,如果狼在羊旁边就会把羊吃掉. 可以在空地上放狗,狼不能通过有狗的地方,狼的行走是四联通的. 问是否能够保护所有的羊 ...
- Linux中断处理驱动程序编写【转】
转自:http://blog.163.com/baosongliang@126/blog/static/1949357020132585316912/ 本章节我们一起来探讨一下Linux中的中断 中断 ...
- Codechef AMXOR
Problem Codechef Solution 我们可以按位进行考虑,如果一个 \(m_i\) 在某一位上为1,但 \(x_i\) 却取了0,那么我们就称它脱离了限制,更低位可以随便乱填.也就是说 ...
- c++ 类的构造顺序
在单继承的情况下,父类构造先于子类,子类析构先于父类,例: class A { public: A() { cout << "A" << endl; } ~ ...
- sicily 1500. Prime Gap
Description The sequence of n ? 1 consecutive composite numbers (positive integers that are not prim ...