Hadoop自定义类型处理手机上网日志
job提交源码分析
在eclipse中的写的代码如何提交作业到JobTracker中的哪?
(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法
connect();
info = jobClient.submitJobInternal(conf);
(2)在connect()方法中,实际上创建了一个JobClient对象。
在调用该对象的构造方法时,获得了JobTracker的客户端代理对象JobSubmissionProtocol。
JobSubmissionProtocol的实现类是JobTracker。
(3)在jobClient.submitJobInternal(conf)方法中,调用了
JobSubmissionProtocol.submitJob(...),
即执行的是JobTracker.submitJob(...)。
Hadoop数据类型
1.Hadoop的数据类型要求必须实现Writable接口。
2.java基本类型与Hadoop常见基本类型的对照
Long LongWritable
Integer IntWritable
Boolean BooleanWritable
String Text
java类型如何转化为hadoop基本类型?
调用hadoop类型的构造方法,或者调用set()方法。
new LongWritable(123L);
hadoop基本类型如何转化为java类型?
对于Text,需要调用toString()方法,其他类型调用get()方法。
使用Hadoop自定义类型处理手机上网日志
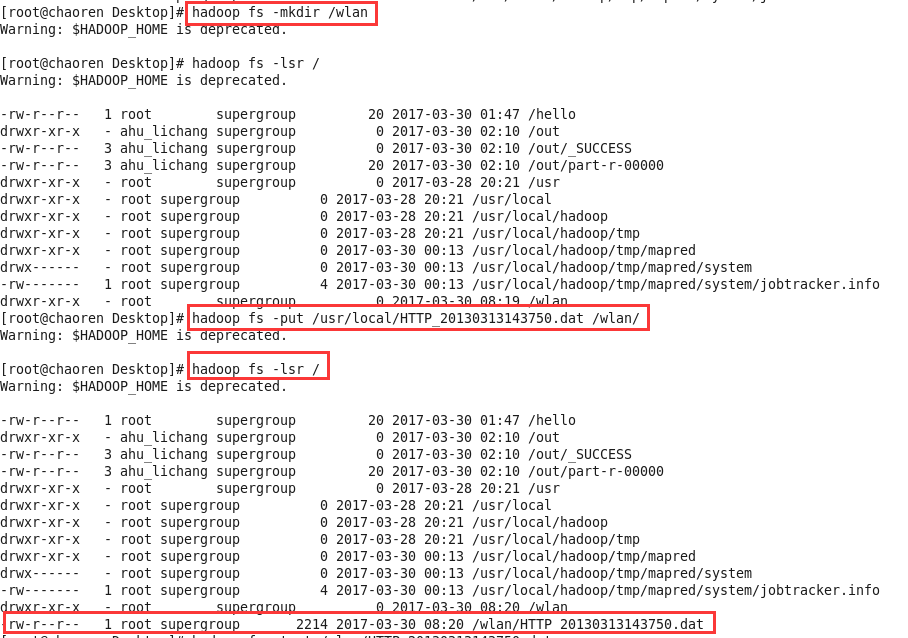
1、首先,将手机上网日志文件HTTP_20130313143750.dat通过WinSCP工具复制到/usr/local目录下
2、将日志文件上传到hdfs://chaoren:9000/wlan文件夹下
日志文件:

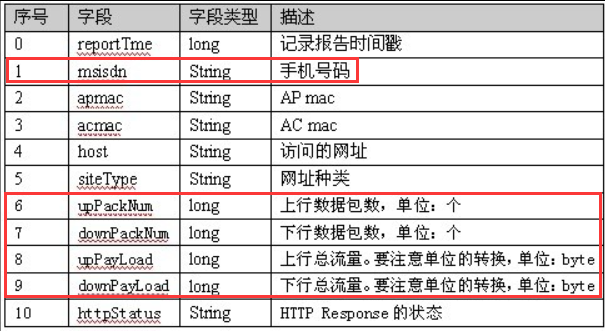
日志文件中各字段含义:
3、编写Java代码将日志文件中想要的数据统计出来。
package mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class KpiApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/wlan";//wlan是个文件夹,日志文件放在/wlan目录下
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
final Job job = new Job(new Configuration(),
KpiApp.class.getSimpleName());
// 1.1 指定输入文件路径
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定哪个类用来格式化输入文件
job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的Mapper类
job.setMapperClass(MyMapper.class);
// 指定输出<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class); // 1.3 指定分区类
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1); // 1.4 TODO 排序、分区 // 1.5 TODO (可选)归约 // 2.2 指定自定义的reduce类
job.setReducerClass(MyReducer.class);
// 指定输出<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(KpiWritable.class); // 2.3 指定输出到哪里
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
// 设定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class); // 把代码提交给JobTracker执行
job.waitForCompletion(true);
} static class MyMapper extends Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
final String[] splited = value.toString().split("\t");
final String msisdn = splited[1];
final Text k2 = new Text(msisdn);
final KpiWritable v2 = new KpiWritable(splited[6], splited[7],
splited[8], splited[9]);
context.write(k2, v2);
};
} static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
/**
* @param k2
* 表示整个文件中不同的手机号码
* @param v2s
* 表示该手机号在不同时段的流量的集合
*/
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L; for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
} final KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum
+ "", upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
} class KpiWritable implements Writable {
long upPackNum;
long downPackNum;
long upPayLoad;
long downPayLoad; public KpiWritable() {
} public KpiWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
this.upPayLoad = Long.parseLong(upPayLoad);
this.downPayLoad = Long.parseLong(downPayLoad);
} public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
} public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
} @Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t"
+ downPayLoad;
}
}
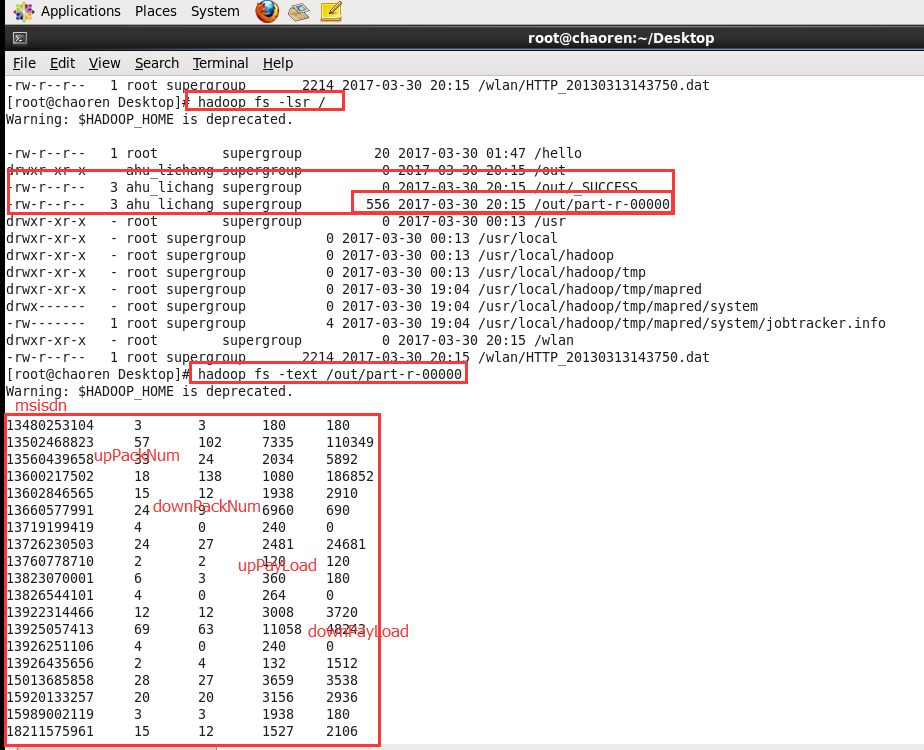
4、运行结果
Hadoop自定义类型处理手机上网日志的更多相关文章
- Hadoop日记Day13---使用hadoop自定义类型处理手机上网日志
测试数据的下载地址为:http://pan.baidu.com/s/1gdgSn6r 一.文件分析 首先可以用文本编辑器打开一个HTTP_20130313143750.dat的二进制文件,这个文件的内 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- 使用Pig对手机上网日志进行分析
在安装成功Pig的基础上.本文将使用Pig对手机上网日志进行分析,详细过程例如以下: 写在前面: 手机上网日志文件phone_log.txt.文件内容 及 字段说明部分截图例如以下 需求分析 显示每一 ...
- MapReduce实现手机上网日志分析(分区)
一.问题背景 实际业务的需要,比如以移动为例,河南的用户去了北京上网,那么他的上网信息默认保存在了北京的基站,那么我们想要查询北京地区的上网日志信息默认也包含了其他地区用户的在本区的上网信息,否则只能 ...
- MapReduce实现手机上网日志分析(排序)
一.背景 1.1 流程 实现排序,分组拍上一篇通过Partitioner实现了. 实现接口,自动产生接口方法,写属性,产生getter和setter,序列化和反序列化属性,写比较方法,重写toStri ...
- 2017.9.2Java中的自定义类型的定义及使用&&自定义类的内存图
今日内容介绍 1.自定义类型的定义及使用 2.自定义类的内存图 3.ArrayList集合的基本功能 4.随机点名器案例及库存案例代码优化 01引用数据类型_类 * A: 数据类型 * a: java ...
- hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量 数据库类型如下: 数据库内容如下: 下面自定义类型SimLines,类似于平时编写的model import java.io.DataIn ...
- CMWAP CMWAP是手机上网使用的接入点的名称
CMWAP 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . CMWAP是手机上网使用的接入点的名称.CMWAP使用HTTP代理协议和WAP网关协议可以访问到Internet.移动用 ...
- APN APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络。
apn 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络. 对于手机用户来说,可 ...
随机推荐
- mongo转换副本集
本文介绍如何把独立的mongo实例转换成包含3个成员的副本集.开发和测试使用独立实例,生产使用副本集.如何安装独立的mongo实例本文不再赘述. 如果在部署副本集时还没有安装mongo实例,可以查看部 ...
- 超简单将Centos的yum源更换为国内的阿里云源
自己的yum源不知道什么时候给改毁了……搜到了个超简单的方法将yum源更换为阿里的源 完全参考 http://mirrors.aliyun.com/help/centos?spm=5176.bbsr1 ...
- 2017 清北济南考前刷题Day 5 afternoon
期望得分:100+100+30=230 实际得分:0+0+0=30 T1 直接模拟 #include<cstdio> #include<iostream> using name ...
- hihoCoder #1143 : 骨牌覆盖问题·一
#1143 : 骨牌覆盖问题·一 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 骨牌,一种古老的玩具.今天我们要研究的是骨牌的覆盖问题:我们有一个2xN的长条形棋盘,然 ...
- negativeView 的使用
参考链接:http://blog.csdn.net/u012702547/article/details/51253222 1.一般来讲,是配合drawerLayout使用的,在xml文件中声明,其中 ...
- UNDERSTANDING THE GAUSSIAN DISTRIBUTION
UNDERSTANDING THE GAUSSIAN DISTRIBUTION Randomness is so present in our reality that we are used to ...
- Java并发编程原理与实战三:多线程与多进程的联系以及上下文切换所导致资源浪费问题
一.进程 考虑一个场景:浏览器,网易云音乐以及notepad++ 三个软件只能顺序执行是怎样一种场景呢?另外,假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作),而 ...
- MongoDB - MongoDB CRUD Operations, Delete Documents
Delete Methods MongoDB provides the following methods to delete documents of a collection: Method De ...
- 20155117王震宇实验四 Andoid开发基础实验报告
实验内容 1.Android Stuidio的安装测试: 参考<Java和Android开发学习指南(第二版)(EPUBIT,Java for Android 2nd)>第二十四章: - ...
- 爬虫笔记之JS检测浏览器开发者工具是否打开
在某些情况下我们需要检测当前用户是否打开了浏览器开发者工具,比如前端爬虫检测,如果检测到用户打开了控制台就认为是潜在的爬虫用户,再通过其它策略对其进行处理.本篇文章主要讲述几种前端JS检测开发者工具是 ...