Python开启进程的2中方式
知识点一:进程的理论
进程:正在进行的一个程序或者说一个任务,而负责执行任务的则是CPU
进程运行的的三种状态:
1.运行:(由CPU来执行,越多越好,可提高效率)
2.阻塞:(遇到了IQ,3个里面可以通过减少阻塞有效的来提高效率)
3.就绪:(等待CPU来执行的过程)
知识点二:开启进程的两种方式
开启进程:开启进程就是将父进程里面串行执行的程序放到子进程里,实现并发执行,这个过程中,会将父进程数据拷贝一份到子进程。
运行角度:是2个进程
注意:子进程内的初始数据与父进程的一样,如果子进程被创建了被运行了,那么
子进程里面数据更改对父进程无影响,2个进程是存在运行的
方式一:通过调用multiprocessing模块下面的Process类方法
#方式一:通过调用multiprocessing模块下面的Process类方法 '''
p = Process(target=task, args=('子进程',)) :
target=task:指定执行任务的目标是谁 args:后面跟元组,是给target指定函数传的参数
p=Process(..)相当于是对类Process进行实例化得到了P对象
'''
from multiprocessing import Process
import time
def task(x):
print("%s is runnin"%x) #子进程打印输出
time.sleep(3)
print('%s is done'%x) #子进程打印输出 if __name__ == '__main__': #开进程要统一放到main方法的下面
p=Process(target=task,args=('子进程',))
p.start()
print('主') #父进程的打印输出 '''
注意点:
1.p=Process(target=task,args=('子进程',))
这一步:只是在向操作系统发我要开启一个子进程的信号(具体开子进程的操作是由操作系统来完成的)
*所有这个过程中的时间也是不固定的
2.p.start():
开启一个子进程 运行过程分析:
右键运行父类先运行起来(此时p.start()子类也已经在造了,但是会有时间延迟)-->print('主')-->
然后依次运行子进程里面内容;子进程 is runnin\子进程 is done '''
方式二:借助process类,自定义一个类(继承Process),从而造一个对象
#方式二:借助process类,自定义一个类(继承Process),从而造一个对象
from multiprocessing import Process
import time class Myprocess(Process):
#辅助理解,
# def __init__(self,x):
# super().__init__()#保留原有Process类里面的方法
# self.name=x #***如果要自定义传参,self.name=x必须要放到super()._init_()下面
#
def run(self):
print("%s is running" % self.name) #默认函数对象有name方法 ,结果为:Myprocess-1
time.sleep(3)
print('%s is done' % self.name) if __name__ == '__main__':
# p=Myprocess('子进程1',) 开启init方式就可以自定义参数传值
p=Myprocess() #实例化Myprocess类调用了类面的init方法,得到了一个对象p p1=Myprocess() p.start() #p.run() 对象去调用了类里面的run方法,进而执行run里面的函数体代码
p1.start()
print('主')
以上2中方式的对比分析:
方式二:子类只能运行同一个run里面输出的方式(run名字是固定的,不能更改)
方式一:可以自定义多个task函数,并且写不同的输出内容,例如task1-->p1 task2-->p2...等等灵活性更高
父类、子类进程内存空间是彼此隔离的:
from multiprocessing import Process
import time x=100
def task():
global x
x=11 #当子类已经建立成功时,子类里面对数据的变动,不会印象父类
print(x) #
print('done')
if __name__ == '__main__':
p=Process(target=task)
p.start()
time.sleep(10) # 让父进程在原地等待10,是为了等父类先建立好,用于验证子类里面的变动不会影响父类的值
print(x) #打印时父类的,即全局的 100
知识点三:僵尸进程、孤儿进程
僵尸进程:(无害的)
子进程运行结束后,会保留进程的ID号等信息,
目的是为了父进程能查看子进程的状态,以及回收僵尸状态的子进程
孤儿进程:(无害的)
在子类没有运行完的情况下,父类先行结束,这种情况下,当子进程结束时,
状态就叫做孤儿进程,当然也会被系统层面上的孤儿院回收
有一种情况是有害的:
如果父类,不停的在造子类,父类一直不死,此时PID会占用过多,导致内存也会占用很多
这种情况是有害的
知识点四:进程对象相关的属性
1.PID接口查看
#查看PID应用:
# print(p.pid):外面直接查看子类pid
#os.getpid():在内部查看子类pid
#os.getpid():在外面查看父类的pid
#os.getppid():在里面查看父类的pid
import time
import os
from multiprocessing import Process def task(x): print('%s is running'%os.getpid()) #子进程内查看自己pid的方式
time.sleep(100)
print('子类下查看父类的id:%s'%os.getppid()) #查看父类的pid
time.sleep(100)
print('%s is done'%x) if __name__ == '__main__':
p=Process(target=task,args=('子进程1',))
p.start()
print(p.pid,) #父进程内查看子类pid的方式
time.sleep(50)
print('父类下查看父类自己的id:',os.getpid())
print('主')
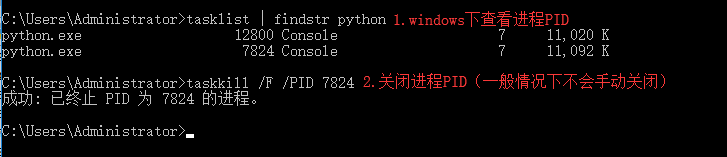
2.join()
import time
from multiprocessing import Process def task(name,n):
print('%s is running'%name)
time.sleep(n)
print('%s is done'%name) if __name__ == '__main__':
p1=Process(target=task,args=("进程1",1)) #用时1s
p2=Process(target=task,args=("进程2",2)) #用时1s
p3=Process(target=task,args=("进程3",3)) #用时1s start_time=time.time()
p1.start()
# p1.join() #如果是这种情况就是总共6s左右了
p2.start()
# p2.join()
p3.start()
# p3.join() # 让父进程在原地等待,等子进程在运行完毕后,才执行下一行代码()
#注意:并不是串行,当第一秒在运行p1时,其实p2、p3也已经在运行,当1s后到p2时只需要再运行1s就到p3了,到p3也是一样。
p1.join()
p2.join()
p3.join()
stop_time=time.time() #3.2848567962646484总结
print(stop_time-start_time)
print('主')
Python开启进程的2中方式的更多相关文章
- Python 开启线程的2中方式,线程VS进程(守护线程、互斥锁)
知识点一: 进程:资源单位 线程:才是CPU的执行单位 进程的运行: 开一个进程就意味着开一个内存空间,存数据用,产生的数据往里面丢 线程的运行: 代码的运行过程就相当于运行了一个线程 辅助理解:一座 ...
- [操作系统知识储备,进程相关概念,开启进程的两种方式、 进程Queue介绍]
[操作系统知识储备,进程相关概念,开启进程的两种方式.进程Queue介绍] 操作系统知识回顾 为什么要有操作系统. 程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作 ...
- Day9 进程理论 开启进程的两种方式 多进程实现并发套接字 join方法 Process对象的其他属性或者方法 守护进程 操作系统介绍
操作系统简介(转自林海峰老师博客介绍) #一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理.调度进程,并且将多个进程对硬件的竞争变得有序 #二 多道技术: 1.产生背景: ...
- python 开启进程两种方法 multiprocessing模块 介绍
一 multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu\_count\(\)查看),在python中大部分情况需要使用多进 ...
- python实现进程的三种方式及其区别
在python中有三种方式用于实现进程 多进程中, 每个进程中所有数据( 包括全局变量) 都各有拥有⼀份, 互不影响 1.fork()方法 ret = os.fork() if ret == 0: # ...
- Python—创建进程的三种方式
方式一:os.fork() 子进程是从os.fork得到的值,然后赋值开始执行的.即子进程不执行os.fork,从得到的值开始执行. 父进程中fork之前的内容子进程同样会复制,但父子进程空间独立,f ...
- python创建进程的两种方式
1.方式1 import time import multiprocessing def task(arg): time.sleep(2) print(arg) def run(): # 进程1 p1 ...
- Python创建进程、线程的两种方式
代码创建进程和线程的两种方式 """ 定心丸:Python创建进程和线程的方式基本都是一致的,包括其中的调用方法等,学会一个 另一个自然也就会了. "" ...
- 并发编程---开启进程方式---查看进程pid
1.开启进程的两种方式 方式一: from multiprocessing import Process import time def task(name): print('%s is runnin ...
随机推荐
- cocos2d-android-1学习之旅01
学习cocos2d-android-1也大概有半个月了,来整理一下自己的学习心得和提出自己的疑问.之所以不学习非常火的cocos2d-x,转而来学习这个网上学习资料少得可怜的cocos2d-andro ...
- The Mythical Man-Month
大家所熟知的Windows XP操作系统,源代码行数已经达到40百万行.为了连接用户和计算机底层硬件,庞大操作系统这一层太过于复杂,没有一个人能完全理解它如此数量的所有代码,而多人的合作开发又需要它被 ...
- 大家一起和snailren学java-(序)
由于最近在面试实习的时候,发现自己的java基础还是不是特别的扎实.因此再重新深入学习一下java.每天学习一点,都能进步一些. 用书<Thinking in java><effec ...
- 云计算的那些「What」
本文从云计算讲起,介绍了选择云计算的各种理由和一些最基本的概念. 经过十多年发展,云计算早已成为不可阻挡的技术潮流,逐渐深入到各行各业,不同规模的组织中,帮助用户以更低运营成本获得完善高效的 IT 服 ...
- python+selenium之处理HTML5的视频播放
from selenium import webdriver from time import sleep driver = webdriver.Firefox() driver.get(" ...
- HDU 2149 Public Sale 拍卖(巴什博弈)
思路:只要能给对方留下n+1,我就能胜,否则败. #include <iostream> #include <cstdio> using namespace std; int ...
- 【exFat】利用命令提示符在windows 7 及 windows server 2008 r2 中将卷(分区)格式化为exFAT
步骤 运行cmd.exe: 查看磁盘信息.输入diskpart并回车: 选择磁盘.输入select disk 0(“0”代表要选择的磁盘号)并回车: 查看所选硬盘的分区.输入list partitio ...
- Update主循环的实现原理
从写一段程序,到写一个app,写一个游戏,到底其中有什么不同呢?一段程序的执行时间很短,一个应用的执行时间很长,仅此而已.游戏中存在一个帧的概念. 这个概念大家都知道,类比的话,它就是电影胶卷的格.一 ...
- input输入大于0的小数和整数
<input onkeyup="num(this)"onbeforepaste="num(this)"> <script src='jquer ...
- ZOJ 1729 Hidden Password (字符串最小表示)
以前听过,不知道是什么,其实就是字符串首尾相连成一个环,n种切法求一个字典序最小的表示. 朴素算法大家都懂.O(n)的算法代码非常简单,最主要的思想是失配的时候尽可能大的移动指针. 另外附上一个不错的 ...