2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码
html = requests.get(YieldCurveUrl, headers=headers)
html=html.content.decode('UTF-8')
# print(html)
soup = BeautifulSoup(html, 'lxml')
之前是这样的
html = requests.get(YieldCurveUrl, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
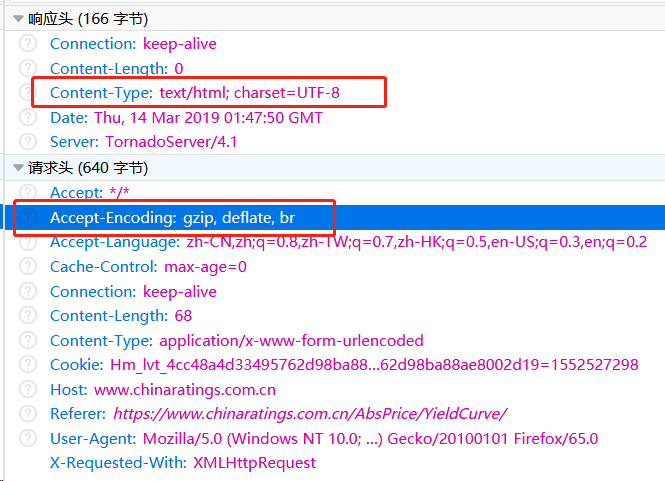
出现乱码,一般是两种原因,charset使用了geb2312的编码方式,而非utf-8
这里用的是utf-8,所以问题出在使用了gzip的压缩方式
2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码的更多相关文章
- python 爬虫(爬取网页的img并下载)
from urllib.request import urlopen # 引用第三方库 import requests #引用requests/用于访问网站(没安装需要安装) from pyquery ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
随机推荐
- 关于python从Oracle中读取数据中文全是问号的问题
import os os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' 问题搞定
- (OpenExplorer For Eclipse)Eclipse 中打开工程目录的插件(转)
我们想在Eclipse中的打开工程目录,Eclipse 自身没有这个功能,我们可以安装一个插件来实现这个功能.具体的操作方法如下: (1).到以下链接中下载插件:https://github.com/ ...
- 洛谷——P1802 5倍经验日
https://www.luogu.org/problem/show?pid=1802#sub 题目背景 现在乐斗有活动了!每打一个人可以获得5倍经验!absi2011却无奈的看着那一些比他等级高的好 ...
- poi判断一行是隐藏的getZeroHeight()
poi判断一行是隐藏的 getZeroHeight() boolean isZeroHeight = row.getZeroHeight(); if(isZeroHeight){ // 如果为隐藏行就 ...
- Ruby中使用patch HTTP方法
Ruby中使用patch HTTP方法 如果使用patch,在后台可以看到只更新了改动的部分: Started PATCH "/ads/5/update" for ::1 at 2 ...
- Linux Unix shell 编程指南学习笔记(第三部分)
第十三章 登陆环境 登陆系统时.输入username和password后.假设验证通过.则进入登录环境. 登录过程 文件/etc/passwd $HOME.profile 定制$HOME.profi ...
- JPEG压缩图像超分辨率重建算法
压缩图像超分辨率重建算法学习 超分辨率重建是由一幅或多幅的低分辨率图像重构高分辨率图像,如由4幅1m分辨率的遥感图像重构分辨率0.25m分辨率图像.在军用/民用上都有非常大应用. 眼下的超分辨率重建方 ...
- Android 零基础学习之路
第一阶段:Java面向对象编程 1.Java基本数据类型与表达式,分支循环. 2.String和StringBuffer的使用.正則表達式. 3.面向对象的抽象.封装,继承,多态.类与对象.对象初始化 ...
- zzulioj--1613--少活一年?(稍微有点坑,水!)
1613: 少活一年? Time Limit: 1 Sec Memory Limit: 128 MB Submit: 344 Solved: 70 SubmitStatusWeb Board De ...
- Python笔记(四)
# -*- coding:utf-8 -*- # 控制语句 # if...else... print "********************1********************** ...