weka数据挖掘拾遗(三)----再谈如果何生成arff
前一阵子写过一个arff的随笔,但是写完后发现有些啰嗦。其实如果使用weka自带的api,生成arff文件将变成一件很简单的事儿。
首先,可以先把特征文件生成csv格式的。csv格式就是每列数据都用逗号分隔的一种格式。(还有不清楚的googling一下就知道了)
一、首先看下特征文件怎么保存成csv格式。
1、首行为特征名,以逗号分隔。
2、除首行外的行都为数据行,每列数据都是首行对应的值。(可以是字符串,数字)
例: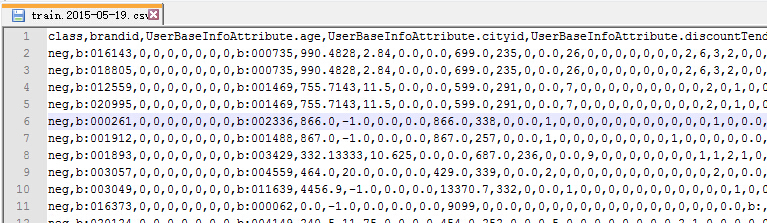
二、通过weka的api把上面的csv转化成arff格式文件
1、weka代码
public static void genArffFile(String input , String output){
try{
File file = new File(input);
CSVLoader csvLoader = new CSVLoader();
csvLoader.setSource(file);
Instances data = csvLoader.getDataSet();
savaInstances(data, output);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* @function 保存Arff文件
* @param data arff格式的数据
* @param outputPath 数据保存路径
* @return
*/
public static boolean savaInstances(Instances data , String outputPath)
{
try{
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(outputPath), Charset.forName("utf-8"))); bw.write(data.toString());
bw.close();
}catch(Exception e){
e.printStackTrace();
return false;
}
return true;
}
三、总结
从上面的代码能看出,如果已经生成了csv格式的特征文件,那么生成arff文件也就是几行代码的事情。其实,如果生成了csv格式的特征文件,那么weka是直接可以读取的,之后使用 Instances data = csvLoader.getDataSet(); 这行代码其实就是把数据存到了Instances中,而Instances其实就是保存的arff格式的文件。如果没有其它必要,使用weka时,使用以csv格式的特征文件也是可以的,不必要非得转化成arff格式。
weka数据挖掘拾遗(三)----再谈如果何生成arff的更多相关文章
- weka数据挖掘拾遗(一)---- 生成Arff格式文件
一.什么是arff格式文件 1.arff是Attribute-Relation File Format缩写,从英文字面也能大概看出什么意思.它是weka数据挖掘开源程序使用的一种文件模式.由于weka ...
- weka数据挖掘拾遗(二)---- 特征选择(IG、chi-square)
一.说明 IG是information gain 的缩写,中文名称是信息增益,是选择特征的一个很有效的方法(特别是在使用svm分类时).这里不做详细介绍,有兴趣的可以googling一下. chi-s ...
- python之路--小数据池,再谈编码,is和 == 的区别
一 . 小数据池 # 小数据池针对的是: int, str, bool 在py文件中几乎所有的字符串都会缓存. # id() 查看变量的内存地址 s = 'attila' print(id(s)) 二 ...
- python-小数据池,再谈编码,is和 == 的区别
一 . 小数据池 # 小数据池针对的是: int, str, bool 在py文件中几乎所有的字符串都会缓存. # id() 查看变量的内存地址 s = 'attila' print(id(s)) 二 ...
- GoF设计模式三作者15年后再谈模式
Erich Gamma, Richard Helm, 和 Ralph Johnson在GoF设计模式发表15年以后,再谈模式,另外一位作者,也是四色原型的发明者Peter已经过世. 提问者:如今有85 ...
- 【转】 Pro Android学习笔记(四三):Fragment(8):再谈Transaction和管理器
目录(?)[-] Transaction的一些操作 再谈FragmentManager 调用其他fragment的方法 唤起activity 唤起fragment和相互通信 一些其它 Transact ...
- 初试weka数据挖掘
初试weka数据挖掘 Posted on 2013-09-07 13:26 DM张朋飞 阅读(321) 评论(7) 编辑 收藏 偶然间在网上看到了一篇关于weka好的博文,就记录了下来…… weka下 ...
- 再谈SQL Server中日志的的作用
简介 之前我已经写了一个关于SQL Server日志的简单系列文章.本篇文章会进一步挖掘日志背后的一些概念,原理以及作用.如果您没有看过我之前的文章,请参阅: 浅谈SQL Server ...
- [转载]再谈百度:KPI、无人机,以及一个必须给父母看的案例
[转载]再谈百度:KPI.无人机,以及一个必须给父母看的案例 发表于 2016-03-15 | 0 Comments | 阅读次数 33 原文: 再谈百度:KPI.无人机,以及一个必须 ...
随机推荐
- C#--简单的串口通信程序
前几天做毕业设计,其中要用到串口和下位机进行通信,于是自己捣鼓了一个简单的串口通信程序. 在做通信之前要先弄一个SerialPort组件出来,当然也可以通过程序来创建.本次设计中采用的是拖的winfo ...
- java 验证身份证号
- Application, JDBC, 数据库连接池, Session, 数据库的关系
RT,这几个东东已经困扰我很长一段时间了... 这次争取把她们理清楚了! 参考资料: 1. 数据库连接池:http://www.cnblogs.com/shipengzhi/archive/2011/ ...
- Js高程笔记->引用类型
1 . Object 对象 2 . Array 对象 : 检测方法:ES5 : isArray 转换方法: toLocaleString , toString , val ...
- 常量折叠 const folding
http://bbs.byr.cn/#!article/CPP/86336?p=1 下列代码给出输出结果: #include"stdafx.h" #include <iost ...
- in_array函数的第三个参数 strict
看段代码 <?php $array = array('testing',0,'name'); var_dump($array); var_dump(in_array('foo', $array) ...
- IIS 发布程序的一些心得
1.应用程序池一般自己建立对应Framework版本的程序池,并托管管道模式为经典 2.在IIS根目录双击,右侧的“ISAPI和CGI限制” 双击打开,将自己所需要的Framework版本的限制设置为 ...
- (转)【移动开发】Android中三种超实用的滑屏方式汇总(ViewPager、ViewFlipper、ViewFlow)
转自: http://smallwoniu.blog.51cto.com/3911954/1308959 现如今主流的Android应用中,都少不了左右滑动滚屏这项功能,(貌似现在好多人使用智能机都习 ...
- typedef (还需经常看看加深理解)
看了 c++primer 1,typedef名字 typedef定义以关键字typedef开始,后面是 数据类型+标示符. 并未引入新的类型,只是现有数据类型的同义词 例: typedef doubl ...
- js截取指定字节长度的字符串
默认的截取字符串都是根据字符长度或位置截取的,典型的两个方法是substr和substring. 这样导致的问题是截取同样长度的字符串时,多字节字符(汉字等)和单字节字符(半角英文字母.半角数字)占的 ...