spark RDD transformation与action函数整理
1.创建RDD
val lines = sc.parallelize(List("pandas","i like pandas"))

2.加载本地文件到RDD
val linesRDD = sc.textFile("yangsy.txt")
3.过滤 filter 需要注意的是 filter并不会在原有RDD上过滤,而是根据filter的内容重新创建了一个RDD
val spark = linesRDD.filter(line => line.contains("damowang"))

4.count() 也是aciton操作 由于spark为懒加载 之前的语句不管对错其实都没执行 只有到调用action 如count() first() foreach()等操作的时候 才会真正去执行
spark.count()
5.foreach(println) 输出查看数据 (使用take可获取少量数据,如果工程项目中为DataFrame,可以调用show(1)) 这里提到一个东西,就是调用collect()函数 这个函数会将所有数据加载到driver端,一般数据量巨大的时候还是不要调用collect函数()否则会撑爆dirver服务器 虽然我们项目中暂时的确是用collect()把4000多万数据加载到dirver上了- =)
spark.take(1).foreach(println)
6.常见的转化操作和行动操作 常见的转化操作如map()和filter()
比如计算RDD中各值的平方:
val input = sc.parallelize(List(1,2,3,4))
val result = input.map(x => x*x)
println(result.collect().mkString(","))
7.flatMap() 与map类似,不过返回的是一个返回值序列的迭代器。得到的是一个包含各种迭代器可访问的所有元素的RDD。简单的用途比如把一个字符串切分成单词
val lines = sc.parallelize(List("xiaojingjing is my love","damowang","kings_landing"))
val words = lines.flatMap(line => line.split(","))
//调用first()返回第一个值
words.first()
归类总结RDD的transformation操作:
对一个数据集(1,2,3,3)的RDD进行基本的RDD转化操作
map: 将函数应用于RDD中的每个元素,将返回值构成一个新的RDD eg: rdd.map(x => x+1) result: {2,3,4,4)
flatmap:将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD,通常用来拆分 eg:rdd.flatMap(x => x.split(",")) .take(1).foreach(println) result: 1
flter:返回一个由通过传给filter的函数的元素组成的RDD eg:rdd.filter(x => x != 1) result: {2,3,3}
distinct:用来去重 eg:rdd.distinct() {1,2,3}
对数据分别为{1,2,3}和{3,4,5}的RDD进行针对两个RDD的转换操作
union: 生成一个包含所有两个RDD中所有元素的RDD eg: rdd.union(other) result:{1,2,3,3,4,5}
intersection:求两个元素中的共同的元素 eg:rdd.intersection(ohter) result:{3}
substract() 移除RDD中的内容 eg:rdd.substract(other) result:{1,2}
cartesian() 与另一个RDD的笛卡尔积 eg:rdd.cartesian(other) result:{(1,3),(1,4),(1,5)....(3,5)}
以上皆为transformation操作,下来action操作
9.reduce 并行整合RDD中所有数据
val lines1 = sc.parallelize(List(1,2,3,3))
lines1.reduce((x,y) => x + y)

10.reducebykey 最简单的就是实现wordcount的 统计出现的数目,原理在于map函数将rdd转化为一个二元组,再通过reduceByKey进行元祖的归约。
val linesRDD = sc.textFile("yangsy.txt")
val count = linesRDD.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_).collect()
11.aggregate函数 与reduce相似,不过返回的是不同类型的函数
val result = input.aggregate((0,0))(acc.value) => (acc._1+value,acc._2+1),(acc1,acc2) =>(acc1._1 + acc2._1 , acc1._2 + acc2._2))
还有很多比如count(),take(num)等就不一一练习了
12.collect函数还有foreach函数 其实刚才已经用到了,这里也不多说了~
归纳总结RDD的action操作:
对一个数据为{1,2,3,3}的RDD的操作
collect: 返回RDD中的所有元素 rdd.collect()
count: RDD中的元素的个数
countByValue: 返回各元素在RDD中出现的次数 : eg:rdd.countByValue() [(1,1),(2,1),(3,2)....]
take(num): 从RDD中返回num个元素
top(num) : 从RDD中返回最前面的num个元素
takeSample(withReplacement,num,[seed]) : 从RDD中返回任意一些元素 eg: rdd.takeSample(false,1)
reduce(func): 并行整合RDD中所有的数据 rdd.reduce(x,y) => x + y)
foreach(func):对RDD中的每个元素使用给定的函数
在调用persist()函数将数据缓存如内存 想删除的话可以调用unpersist()函数
Pari RDD的转化操作
由于Pair RDD中包含二元组,所以需要传递的函数应当操作二元组而不是独立的元素
12.reduceByKey(fuc) 其实刚才wordcount应经用过 就是将相同的key的value进行合并
val lines1 = sc.parallelize(List((1,2),(3,4),(3,6)))
val lines = lines1.reduceByKey((x,y) => x + y) lines.take(2).foreach(println)
13.groupByKey 将相同键的值进行分组
val lines1 = sc.parallelize(List((1,2),(3,4),(3,6)))
lines1.groupByKey()
lines.take(3).foreach(println)
14.mapValues 对pair RDD中的每个值应用一个函数而不改变键
val lines1 = sc.parallelize(List((1,2),(3,4),(3,6)))
val lines = lines1.mapValues(x => x+1)
lines.take(3).foreach(println)
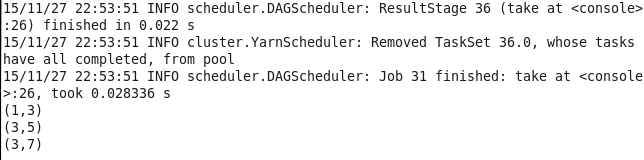
15.sortByKey 返回一个根据键排序的RDD
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val lines = lines1.sortByKey()
lines.take(3).foreach(println)
针对两个不同的pair RDD的转化操作
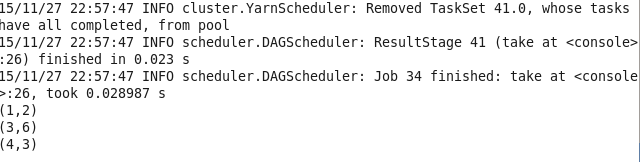
16.subtractByKey 删掉RDD中键与其他RDD中的键相同的元素
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val lines2 = sc.parallelize(List((1,3),(5,3),(7,6)))
val lines = lines1.subtractByKey(lines2)
lines.take(3).foreach(println)
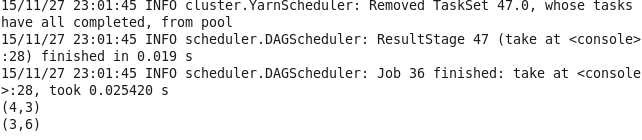
17.join 对两个RDD具有相同键的进行合并
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val lines2 = sc.parallelize(List((1,3),(5,3),(7,6)))
val lines = lines1.join(lines2)
lines.take(3).foreach(println)

18.rightOuterJoin 对两个RDD进行连接操作,确保第一个RDD的键必须存在 相反的为leftOuterJoin
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val lines2 = sc.parallelize(List((1,3),(5,3),(7,6)))
val lines = lines1.rightOuterJoin(lines2)
lines.take(3).foreach(println)
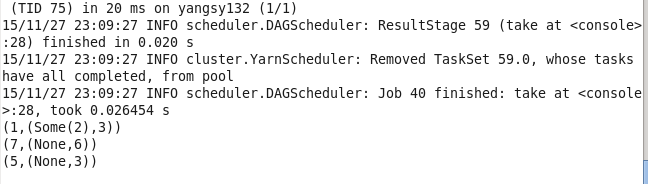
19.cogroup 将两个RDD中拥有相同键的数据分组
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val lines2 = sc.parallelize(List((1,3),(5,3),(7,6)))
val lines = lines1.cogroup(lines2)
lines.take(3).foreach(println)

20. 用Scala对第二个元素进行筛选
val lines1 = sc.parallelize(List((1,2),(4,3),(3,6)))
val result = lines1.filter{case(key,value) => value < 3}
result.take(3).foreach(println)

聚合操作
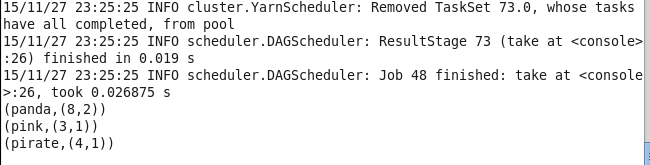
21.在scala中使用reduceByKey()和mapValues()计算每个值对应的平均值 这个过程是这样的 首先通过mapValues函数,将value转化为了(2,1),(3,1),(6,1),(4,1) 然后通过reduceByKey合并相同键的结果 (其实就是mapreduce)
val lines1 = sc.parallelize(List(("panda",2),("pink",3),("panda",6),("pirate",4)))
val lines = lines1.mapValues(x =>(x,1)).reduceByKey((x,y) => (x._1 + y._1 , x._2 + y._2))
lines.take(3).foreach(println)
22.countByValue 其实原理跟reduceByKey一样 另一半wordCount
val linesRDD = sc.textFile("yangsy.txt")
val count = linesRDD.flatMap(line => line.split(" ")).countByValue()

22.并行度问题
在执行聚合操作或者分组操作的时候,可以要求Spark使用给定的分区数,Spark始终尝试根据集群的大小推出一个有意义的默认值,但是有时候可能要对并行度进行调优来获取更好的性能。 (重要)比如wordcount,多加一个参数代表需要执行的partition的size
val linesRDD = sc.textFile("yangsy.txt")
val count = linesRDD.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_,10)
读取HDFS中csv文件
import java.io.StringReader
import au.com.bytecode.opencsv.CSVReader val input = sc.textFile("test.csv")
val result = input.map{line => val reader = new CSVReader(new StringReader(line)); reader.readNext()} result.collect()

spark RDD transformation与action函数整理的更多相关文章
- spark rdd Transformation和Action 剖析
1.看到 这篇总结的这么好, 就悄悄的转过来,供学习 wordcount.toDebugString查看RDD的继承链条 所以广义的讲,对任何函数进行某一项操作都可以认为是一个算子,甚至包括求幂次,开 ...
- Spark学习笔记之RDD中的Transformation和Action函数
总算可以开始写第一篇技术博客了,就从学习Spark开始吧.之前阅读了很多关于Spark的文章,对Spark的工作机制及编程模型有了一定了解,下面把Spark中对RDD的常用操作函数做一下总结,以pys ...
- Spark RDD Transformation 简单用例(三)
cache和persist 将RDD数据进行存储,persist(newLevel: StorageLevel)设置了存储级别,cache()和persist()是相同的,存储级别为MEMORY_ON ...
- Spark(四)Spark之Transformation和Action
Transformation算子 基本的初始化 java static SparkConf conf = null; static JavaSparkContext sc = null; static ...
- Spark RDD Transformation 简单用例(二)
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) aggregateByKey(zeroValue)(seqOp, combOp, [numTa ...
- Spark RDD Transformation 简单用例(一)
map(func) /** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: C ...
- Spark RDD中的aggregate函数
转载自:http://blog.csdn.net/qingyang0320/article/details/51603243 针对Spark的RDD,API中有一个aggregate函数,本人理解起来 ...
- 理解Spark RDD中的aggregate函数(转)
针对Spark的RDD,API中有一个aggregate函数,本人理解起来费了很大劲,明白之后,mark一下,供以后参考. 首先,Spark文档中aggregate函数定义如下 def aggrega ...
- Spark Core (一) 什么是RDD的Transformation和Action以及Dependency(转载)
1. Spark的RDD RDD(Resilient Distributed Datasets),弹性分布式数据集,是对分布式数据集的一种抽象. RDD所具备5个主要特性: 一组分区列表 计算每一个数 ...
随机推荐
- 远程升级openSSH
1.确认安装了telnet服务,并且telnet服务能正常运行 查询是否安装了telnet服务:rpm -qa telnet 如果显示出 类似于telnet-server-0.17-31.EL4.5这 ...
- HDU-4405 Aeroplane chess(概率DP求期望)
题目大意:一个跳棋游戏,每置一次骰子前进相应的步数.但是有的点可以不用置骰子直接前进,求置骰子次数的平均值. 题目分析:状态很容易定义:dp(i)表示在第 i 个点出发需要置骰子的次数平均值.则状态转 ...
- poj1417 带权并查集+0/1背包
题意:有一个岛上住着一些神和魔,并且已知神和魔的数量,现在已知神总是说真话,魔总是说假话,有 n 个询问,问某个神或魔(身份未知),问题是问某个是神还是魔,根据他们的回答,问是否能够确定哪些是神哪些是 ...
- 越狱Season 1-Season 1, Episode 3: Cell Test
Season 1, Episode 3: Cell Test -CO: Oh, my God. 我的天 Williamson, get in here. Williamson 快进来 What the ...
- HttpWebRequest's Timeout and ReadWriteTimeout — What do these mean for the underlying TCP connection?
http://stackoverflow.com/questions/7250983/httpwebrequests-timeout-and-readwritetimeout-what-do-thes ...
- ASM磁盘组空间不足--ORA-15041:DISGROUP DATA space exhausted (生产库案例)
原创作品,出自 "深蓝的blog" 博客,深蓝的blog:http://blog.csdn.net/huangyanlong/article/details/47277715 近日 ...
- adaptive hash index
An optimization for InnoDB tables that can speed up lookups using = and IN operators, by constructin ...
- 一次zabbix的渗透
wget http://xxxxxxx:8888/back.py -O /tmp/1.py 写入python反弹马 反弹到vps python /tmp/back.py IP port ...
- php 错误 Strict Standards: PHP Strict Standards: Declaration of .... should be compatible with that of 解决办法
错误原因:这是由于 php 5.3版本后.要求继承类必须在父类之后定义.否则就会出现Strict Standards: PHP Strict Standards: Declaration of ... ...
- CodeFirstMigrations更新数据库结构(EF数据迁移)
背景 code first起初当修改model后,要持久化至数据库中时,总要把原数据库给删除掉再创建(DropCreateDatabaseIfModelChanges),此时就会产生一个问题,当我们的 ...