Zookeeper Ha集群简介+jdbcClient访问Ha集群环境
Hadoop-HA机制
HA概述
high available(高可用)
所谓HA(high available),即高可用(7*24小时不中断服务)。
实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
高可靠:hdfs多个副本
最大的作用解决:单点故障存在的问题
单点故障原因:
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
NameNode故障解决
HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器
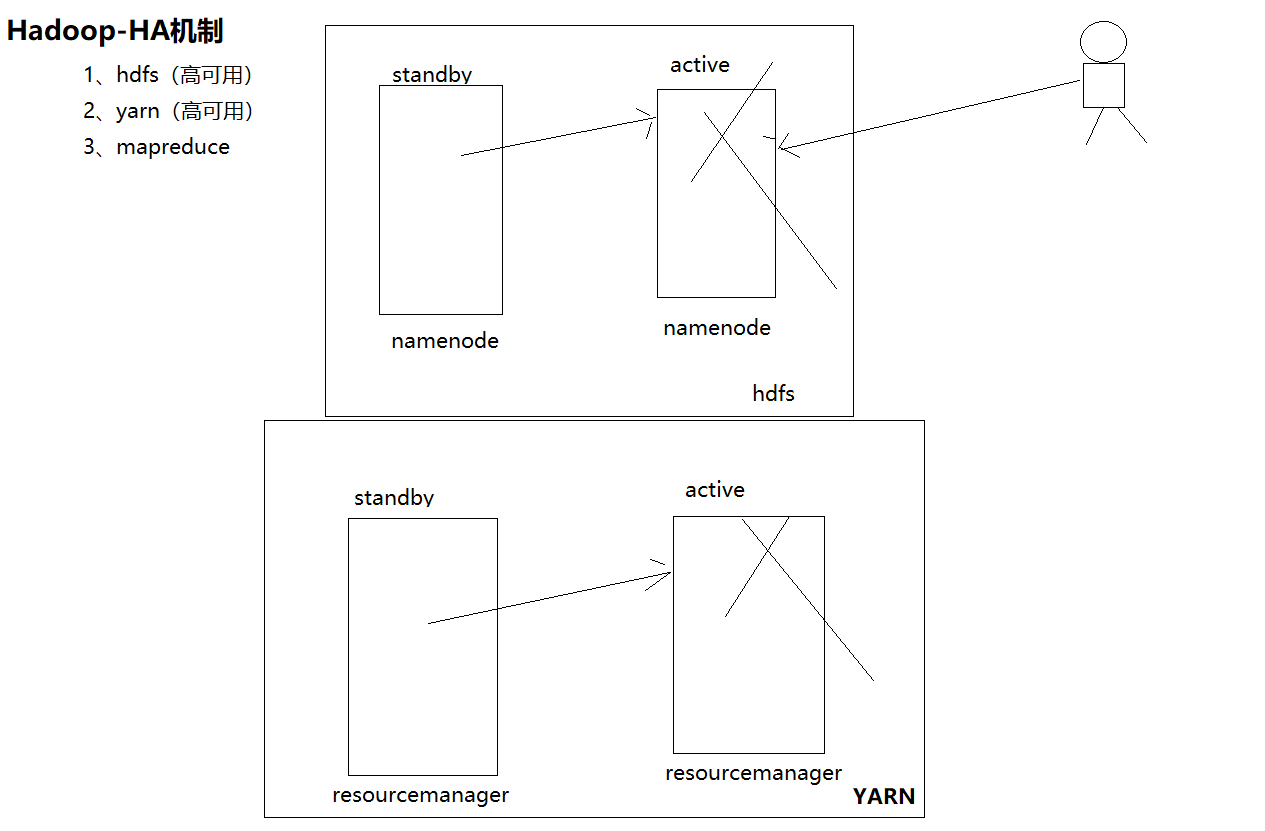
HA的运作机制(重点)
涉及组件:
1、zookeeper:协调主备namenode的切换
2、qjournal:主备namenode的数据同步
3、zkfc:它zookeeper的客户端应用,主要检测namenode的健康状态
4、active namenode:激活的namenode
5、standby namenode:备用的namenode
HDFS-HA工作要点
元数据管理方式需要改变
需要一个状态管理功能模块
必须保证两个NameNode之间能够ssh无密码登录。
隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
元数据管理方式
内存中各自保存一份元数据
Edits日志只有Active状态的namenode节点可以做写操作
两个namenode都可以读取edits
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,
利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生
故障转移工作机制
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程。
Zookeeper作用
故障检测
集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
现役NameNode选择
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
健康监测
active选择
jdbcClient访问Ha集群环境
package com.gec.demo; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; public class HdfsClientApp {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
Configuration configuration=new Configuration();
FileSystem fileSystem= FileSystem.get(new URI("hdfs://bi/"),configuration,"hadoop");
// 2 把本地文件上传到文件系统中 fileSystem.copyFromLocalFile(new Path("D:/hello.txt"), new Path("/hello1.copy.txt")); // 3 关闭资源 fileSystem.close(); }
}
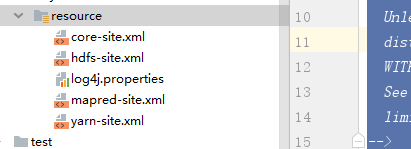
注意要将以下配置文件copy到resource文件夹中。否则会报错!!!
Zookeeper Ha集群简介+jdbcClient访问Ha集群环境的更多相关文章
- 大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述 NameNode 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中 这个集群有哪些DataNode ...
- oracle ebs应用产品安全性-数据访问权限集
定义 数据访问权限集是一个重要的.必须设定的系统配置文件选项.对具有相同科目表.日历和期间类型的分类帐及其所有平衡段值或管理段值的定义读写权限,系统管理员将其分配至不同的责任以控制不同的责任对分类帐数 ...
- HA(High available)-Keepalived高可用性集群(双机热备)单点实验-菜鸟入门级
HA(High available)-Keepalived高可用性集群 Keepalived 是一个基于VRRP虚拟路由冗余协议来实现的WEB 服务高可用方案,虚拟路由冗余协议 (Virtual ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- HA(High available)--Heartbeat高可用性集群(双机热备)菜鸟入门级
HA(High available)--Heartbeat高可用性集群(双机热备) 1.理解:两台服务器A和B ,当A提供服务,B闲置待命,当A服务宕机,会自动切换至B机器继续提供服务.当主机恢复 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- Zookeeper简介及单机、集群模式搭建
1.zookeeper简介 一个开源的分布式的,为分布式应用提供协调服务的apache项目. 提供一个简单的原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务. 设计非常易于编程,它使用的是 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案
http://aokunsang.iteye.com/blog/2053719 声明:以下仅为个人的一些总结和随写,如有不对之处,还请看到的网友指出,以免误导. (详细的配置方案请google,这 ...
- web应用的负载均衡、集群、高可用(HA)解决方案
看看别人的文章: 1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代 ...
随机推荐
- 并发的HTTP请求,apache是如何响应的,以及如何调用php文件的
作者:酒窝链接:https://www.zhihu.com/question/23786410/answer/153455460来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- python scrapy 数据处理时间格式转换
def show(self,response): # print(response.url) title = response.xpath('//main/div/div/div/div/h1/tex ...
- 在Ubuntu上搭建IntelliJ IDEA license server服务器
1.下载激活文件 2.ubuntu需要使用 IntelliJIDEALicenseServer_linux_amd64 ,把该文件传到服务器的某个目录,我是放在了/jideal 下 3.进入上面的目录 ...
- ecmall 的一些方法说明
ecmall/eccore /ecmall.php 常量: define('START_TIME', ecm_microtime()); define('IS_POST', (strtoupper($ ...
- table标签总结
一.table标签:定义一个表格简单表格由table元素以及一个或多个tr(行标签).th(表头单元格标签).td(普通单元格标签) <table border=1><tr>& ...
- linux 命令使用方法(随时更新)
1.hexdump 命令简介:hexdump是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII.八进制.十进制.十六进制格式进行查看. 命令语法:hexdump: [-bcCd ...
- 【leetcode】409. Longest Palindrome
problem 409. Longest Palindrome solution1: class Solution { public: int longestPalindrome(string s) ...
- 【转】visualSFM生成的bundle.rd.out文件的格式
1.bundle.out 文件包含了一些经过估算得到的场景和相机几何信息.文件的格式如下: //---------------------------------------------------- ...
- jquery中on绑定click事件在苹果手机失效的问题
因为是动态添加的内容,所以想要使用click事件,需要给他用on绑定一下: $(document).on("click",".next_button",func ...
- python 闭包和迭代器
一 函数名的运用:(函数名是一个变量,但它是一个特殊变量,与括号配合可以执行变量. (1) 函数名可以赋值给其他变量 def chi(): print("吃月饼") fn=chi ...