大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述
NameNode
- 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中
- 这个集群有哪些DataNode,每一个DataNode的主机名、磁盘容量大小等信息
SecondaryNameNode
辅助NameNode来提高性能,以及防止丢数据的
DataNode
真正存储数据的节点
Client
HDFS中的数据块(Block)
每一个数据块默认容量是128M,可以通过设置修改,在${HADOOP_HOME}/etc/hadoop/hdfs-site.xml中加上配置:
<property>
<name>dfs.block.size</name>
<!--修改为256M: 256*1024*1024 -->
<value>268435456</value>
</property>
重启HDFS:stop-dfs.sh
通过WebUI查看(http://${host}:50070/**)
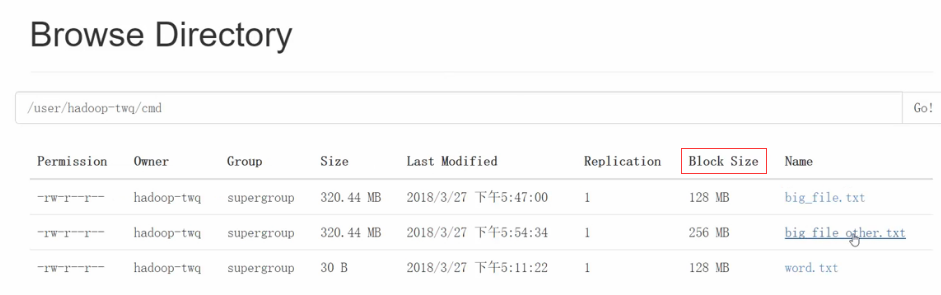
数据块备份
数据块默认备份数为3,可通过命令修改:hadoop fs -setrep 2 /users/hadoop-twq/cmd/word.txt
Java访问HDFS集群
大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群的更多相关文章
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记3 - 并行编程模型MapReduce
分布式并行编程用于解决大规模数据的高效处理问题.分布式程序运行在大规模计算机集群上,集群中计算机并行执行大规模数据处理任务,从而获得海量计算能力. MapReduce是一种并行编程模型,用于大规模数据 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习笔记2 - 分布式文件系统HDFS(待续)
分布式文件系统结构 分布式文件系统是一种通过网络实现文件在多台主机上进行分布式存储的文件系统,采用C/S模式实现文件系统数据访问,目前广泛应用的分布式文件系统主要包括GFS和HDFS,后者是前者的开源 ...
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
随机推荐
- mongodb查询后排序
var user = db.getCollection('user') //user.find({},{_id:0}).pretty().count() user.find({age:{$gte:25 ...
- [BJOI2014]大融合
Description 给你一个n个点的森林,要求支持m个操作: 1.连接两个点 x,y 2.询问若断掉 x,y这条边,两点所在联通块乘积的大小 Hint: \(n,m<=10^5\) Solu ...
- 20172302 《Java软件结构与数据结构》第三周学习总结
2018年学习总结博客总目录:第一周 第二周 第三周 教材学习内容总结 第五章 队列 1.队列是一种线性集合,其元素从一端加入,从另一端删除:队列元素是按先进先出(FIFO(First in Firs ...
- netty如何知道连接已经关闭,socket心跳,双工?异步?
https://stackoverflow.com/questions/10240694/java-socket-api-how-to-tell-if-a-connection-has-been-cl ...
- 常见的机器学习&数据挖掘知识点
原文:http://blog.csdn.net/heyongluoyao8/article/details/47840255 常见的机器学习&数据挖掘知识点 转载请说明出处 Basis(基础) ...
- Morris图表使用小记
挺好用的,碰到几个问题,有的是瞎试解决了的: 1.我想折线图能够响应单击事件,即点击某个节点后,就能加载进一步的信息,帮助没找到,参照另外一个地方的写法,居然支持事件 Morris.Line({ el ...
- Linux 下Tomcat配置远程访问管理端
1:修改Tomcat默认端口号,将默认的8080修改为8081 apache-tomcat-8.5.31\conf\server.xml <Connector port="8081&q ...
- linux 切分文件
linux经常需要处理文件,如果文件比较大,那么需要切分成为若干的小文件再处理. 命令:split 比如有一个文件: ll -h 1431531915758 -rw-r--r-- 1 ticketde ...
- 基于Python的datetime模块和time模块源码阅读分析
目录 1 前言 2 datetime.pyi源码分步解析 2.1 头部定义源码分析 2.2 tzinfo类源码分析 2.3 date类源码分析 2.4 time类源码分析 2.5 timedelta ...
- 迁移ORACLE_HOME引发的登录sqlplus无法加载类库错误
在10g以后,一般情况下环境变量中没有必要设置LD_LIBRARY_PATH,但是一旦将ORACLE_HOME迁移到其他目录,则环境变量中还需要添加这个变量. Linux和Unix支持TAR方式迁移O ...