Flume的基本概念
Flume 概念
Flume 最早是Cludera提供的日志收集系统,后贡献给Apache。所以目前是Apache下的项目,Flume支持在日志系统中指定各类数据发送方,用于收集数据。
Flume 是一个高可用的,高可靠的,鲁棒性(robust健壮性),分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据(source);同时,Flume提供对数据进行简单处理,并写到各种数据接受仿的能力(sink)。

flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
event 事件
event相关概念:flume的核心是把数据从数据源(source)中收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证传输的过程一定成功,在送到目的地之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己的缓存数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、event信息(即文本文件中的单行记录),如下所以:

其中event信息就是flume收集到的日记记录。
flume的运行机制
flume运行的核心就是agent,agent本身是一个Java进程。
agent 里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
一个完整的工作流程:source不断的接收数据,将数据封装成一个一个的event,然后将event发送给channel,chanel作为一个缓冲区会临时存放这些event数据,随后sink会将channel中的event数据发送到指定的地方—-例如HDFS等。
注:只有在sink将channel中的数据成功发送出去之后,channel才会将临时event数据进行删除,这种机制保证了数据传输的可靠性与安全性。

flume的用法
flume之所以这么神奇—-其原因也在于flume可以支持多级flume的agent,即flume可以前后相继形成多级的复杂流动,例如sink可以将数据写到下一个agent的source中,这样的话就可以连成串了,可以整体处理了。
此外,flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是source可以接受多个输入,所谓扇出就是sink可以将数据输出多个目的地中。
置多个agent的数据流(多级流动)

数据流合并(扇入流)
在做日志收集的时候一个常见的场景就是,大量的生产日志的客户端发送数据到少量的附属于存储子系统的消费者agent。例如,从数百个web服务器中收集日志,它们发送数据到十几个负责将数据写入HDFS集群的agent。
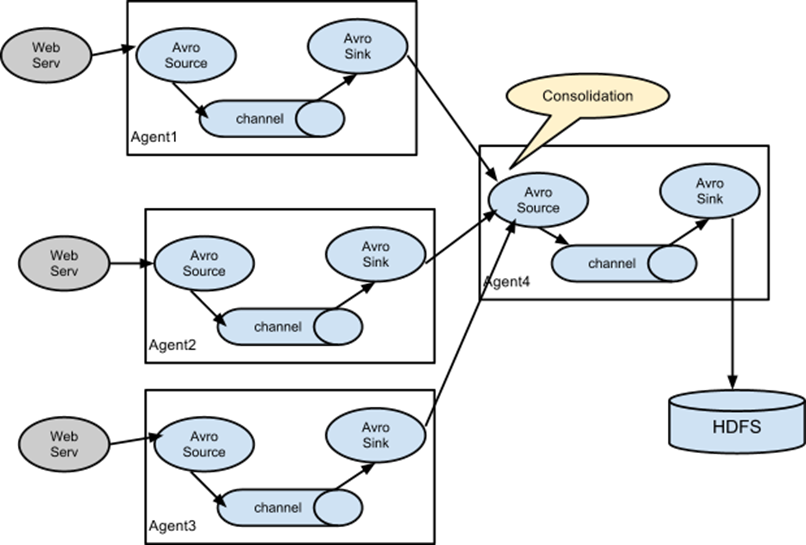
这个可在Flume中可以实现,需要配置大量第一层的agent,每一个agent都有一个avro sink,让它们都指向同一个agent的avro source(强调一下,在这样一个场景下你也可以使用thrift source/sink/client)。在第二层agent上的source将收到的event合并到一个channel中,event被一个sink消费到它的最终的目的地。
数据流复用(扇出流)
Flume支持多路输出event流到一个或多个目的地。这是靠定义一个多路数据流实现的,它可以实现复制和选择性路由一个event到一个或者多个channel。

上面的例子展示了agent foo中source扇出数据流到三个不同的channel,这个扇出可以是复制或者多路输出。在复制数据流的情况下,每一个event被发送所有的三个channel;在多路输出的情况下,一个event被发送到一部分可用的channel中,它们是根据event的属性和预先配置的值选择channel的。 这些映射关系应该被填写在agent的配置文件中。
Flume的特性
可靠性
事务型的数据传递,保证数据的可靠性
一个日志交给flume来处理,不会出现此日志丢失或未被处理的情况。
可恢复性
通道可以以内存或文件的方式实现,内存更快,但不可恢复。文件较慢但提供了可恢复性。
Flume的基本概念的更多相关文章
- Flume NG基本架构与Flume NG核心概念
导读 Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合.移动,最后存储到一个中心化数据存储系统中. 由原来的Flume OG到现在的Flume NG, ...
- Flume的核心概念
Event:一条数据 Client:生产数据,运行在一个独立的线程. Agent (1)Sources.Channels.Sinks (2)其他组件:Interceptors.Channel S ...
- Flume应用场景及架构原理
Flume概念 Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. ...
- flume用场景及架构原理
Flume是什么 1.flume可以将采集到的数据存储到HDFS上,也可以放在Hbase上. 2.flume就是一个中间插件,他的作用就是屏蔽数据源和数据存储系统的差异.可以在不同的数据源采集数据,因 ...
- hadoop flume 架构及监控的部署
1 Flume架构解释 Flume概念 Flume是一个分布式 ,可靠的,和高可用的,海量的日志聚合系统 支持在系统中定制各类的数据发送方 用于收集数据 提供简单的数据提取能力 并写入到各种接受方 ...
- Flume学习总结
Flume学习总结 flume是一个用来采集数据的软件,它可以从数据源采集数据到一个集中存放的地方. 最常用flume的数据采集场景是对日志的采集,不过,lume也可以用来采集其他的各种各样的数据,因 ...
- Flume NG初次使用
一.什么是Flume NG Flume是一个分布式.可靠.和高可用性的海量日志采集.聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据:同时Flume提供对数据的简单处理,并写到各种数 ...
- 海量日志收集利器 —— Flume
Flume 是什么? Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的 ...
- 事件序列化器 Flume 的无数据丢失保证,Channel 和事务
小结: 1.Flume 的持久性保证依赖于使用的持久性Channel 的保证 通过事件序列化器将Flume事件转化为外部存储格式 主要的事件序列化器: 1.文本 2.带有头信息的文本 3.Avro序列 ...
随机推荐
- No setter found for property 'cronExpression' in class 'org.springframework.scheduling.quartz.CronTriggerBean'
今天想写个Spring集成Quartz的小Demo,结果报错cronExpression未定义,通过差错,原来是因为Spring 3.0.5与Quartz2.2.2不兼容,Spring3.1以下的只能 ...
- day 014 python 内置函数
1. lamda匿名函数2. sorted()3. filter()4. map()5. 递归函数 一 匿名函数(lambda) 函数名= lambda 参数: 返回值 简单算法 a+b 常规算 ...
- 洛谷 P1164:小A点菜(DP/DFS)
题目背景 uim神犇拿到了uoi的ra(镭牌)后,立刻拉着基友小A到了一家--餐馆,很低端的那种. uim指着墙上的价目表(太低级了没有菜单),说:"随便点". 题目描述 不过ui ...
- 当爬虫遇到js加密
当爬虫遇到js加密 我们在做python爬虫的时候经常会遇到许多的反爬措施,js加密就是其中一种. 破解js加密的方法也有很多种: 1.直接驱动浏览器抓取数据,无视js加密. 2.找到本地加密的js代 ...
- linux---三剑客
linux的三剑客分别为awk/sed/grep,是运维人员必不可少的常用命令. 一:awk取列 awk ‘{print $1 “ ” $2}’ old.txt awk /aaa/ old.txt 二 ...
- postgresql的基本使用,以及数据库的备份与恢复
安装过程没什么说的,基本是一直下一步下一步,就是中间需要输入密码之类的 postgresql使用模式是数据库表,视图等的集合,我们可以自荐创建一个schema 创建表的方法 进入sql命令行窗口的方法 ...
- lua-resty-qless-web UI 界面运行
lua-resty-qless-web 是 lua-resty-qless 的web 管理界面以及lua-resty-template 模版引擎开发的,里面实现了一个简单的 路由功能 备注: demo ...
- Linux 定时任务crontab使用
正好要搞一个定时删除数据的功能,想到linux 可设置定时器定时执行任务就学习了下~ 并不是所有的linux服务器上都装了crontab 像我这: [root@hehe local]# crontab ...
- 我的虚拟机静态IP配置
- MFC message routine
现在维护的一个软件还是用mfc写的,最近被要加入一个功能弄得焦头烂额.主要现象就是加入的菜单的响应函数没被call到 上网搜索,在官方网站找到了不少资料 主要链接如下 https://msdn.mic ...