机器学习数据处理时label错位对未来数据做预测
这篇文章继上篇机器学习经典模型简单使用及归一化(标准化)影响,通过将测试集label(行)错位,将部分数据作为对未来的预测,观察其效果。
实验方式
- 以不同方式划分数据集和测试集
- 使用不同的归一化(标准化)方式
- 使用不同的模型
- 将测试集label错位,计算出MSE的大小
- 不断增大错位的数据的个数,并计算出MSE,并画图
- 通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据预处理部分与上次相同。两种划分方式:
一、
test_sort_data = sort_data[16160:]
test_sort_target = sort_target[16160:] _sort_data = sort_data[:16160]
_sort_target = sort_target[:16160]
sort_data1 = _sort_data[:(int)(len(_sort_data)*0.75)]
sort_data2 = _sort_data[(int)(len(_sort_data)*0.75):]
sort_target1 = _sort_target[:(int)(len(_sort_target)*0.75)]
sort_target2 = _sort_target[(int)(len(_sort_target)*0.75):]
二、
test_sort_data = sort_data[:5000]
test_sort_target = sort_target[:5000] sort_data1 = _sort_data[5000:16060]
sort_data2 = _sort_data[16060:]
sort_target1 = _sort_target[5000:16060]
sort_target2 = _sort_target[16060:]
一开始用的第一种划分方式,发现直接跑飞了

然后仔细想了想,观察了上篇博客跑出来的数据,果断换了第二种划分方式,发现跑出来的结果还不错
MaxMinScaler()
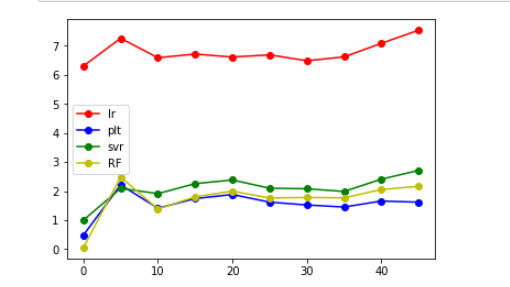
看到lr模型明显要大,就舍弃了
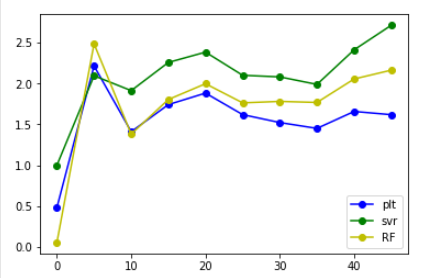
(emmmmm。。。这张图看起来就友好很多了)
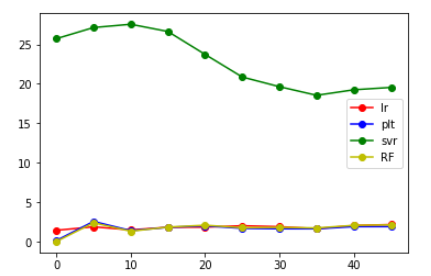
MaxAbsScaler()

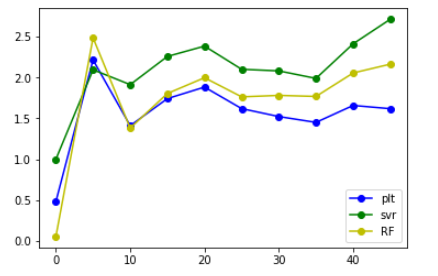
StandardScaler()
代码
其中大部分的代码都是一样的,就是改改归一化方式,就只放一部分了
数据预处理部分见上篇博客
加上这一段用于画图
import matplotlib.pyplot as plt
lr_plt=[]
ridge_plt=[]
svr_plt=[]
RF_plt=[]
接着,先计算不改变label时的值
from sklearn.linear_model import LinearRegression,Lasso,Ridge
from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler
from sklearn.metrics import mean_squared_error as mse
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
#最大最小归一化
mm = MinMaxScaler() lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(sort_data2[new_fea]))
lr_mse=mse(lr_ans,sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(sort_data2[new_fea]))
svr_mse=mse(svr_ans,sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea]))
RF_mse=mse(predict_RF,sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0,
subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1)
bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
bst_ans = bst.predict(mm.transform(sort_data2[new_fea]))
print('bst:',mse(bst_ans,sort_target2))
先将label错位,使得data2的第i位对应target2的第i+5位
change_sort_data2 = sort_data2.shift(periods=5,axis=0)
change_sort_target2 = sort_target2.shift(periods=-5,axis=0)
change_sort_data2.dropna(inplace=True)
change_sort_target2.dropna(inplace=True)
然后用一个循环不断迭代,改变错位的数量
mm = MinMaxScaler() for i in range(0,45,5):
print(i)
lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea]))
lr_mse=mse(lr_ans,change_sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,change_sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea]))
svr_mse=mse(svr_ans,change_sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea]))
RF_mse=mse(predict_RF,change_sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0,
# subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1)
# bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
# bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea]))
# print('bst:',mse(bst_ans,change_sort_target2)) change_sort_target2=change_sort_target2.shift(periods=-5,axis=0)
change_sort_target2.dropna(inplace=True)
change_sort_data2 = change_sort_data2.shift(periods=5,axis=0)
change_sort_data2.dropna(inplace=True)
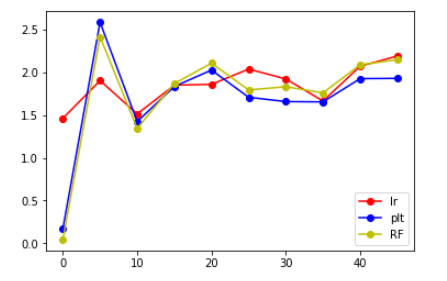
然后就可以画图了
x=[0,5,10,15,20,25,30,35,40,45]
plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='plt',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
结果分析
从上面给出的图来看,发现将label错位后,相比于原来的大小还是有所增大,但是增大后的值并不是特别大,并且大致在某个范围内浮动,大概在错位10个label时能得到的结果是最好的。
机器学习数据处理时label错位对未来数据做预测的更多相关文章
- 机器学习预测时label错位对未来数据做预测
前言 这篇文章时承继上一篇机器学习经典模型使用归一化的影响.这次又有了新的任务,通过将label错位来对未来数据做预测. 实验过程 使用不同的归一化方法,不同得模型将测试集label错位,计算出MSE ...
- 在进行机器学习建模时,为什么需要验证集(validation set)?
在进行机器学习建模时,为什么需要评估集(validation set)? 笔者最近有一篇文章被拒了,其中有一位审稿人提到论文中的一个问题:”应该在验证集上面调整参数,而不是在测试集“.笔者有些不明白为 ...
- 大数据处理时用到maven的repository
由于做数据处理时,经常遇到maven 下载依赖包错误,下面我将自己下载好的repository 分享下 里边包含:Hadoop ,storm ,sprk ,kafka ,等 压缩后500多M. htt ...
- ssh下:系统初始化实现ServletContextListener接口时,获取spring中数据层对象无效的问题
想要实现的功能:SSH环境下,数据层都交由Spring管理:在服务启动时,将数据库中的一些数据加载到ServletContext中缓存起来. 系统初始化类需要实现两个接口: ServletContex ...
- Windows Phone 8初学者开发—第14部分:在运行时绑定到真实的数据
原文 Windows Phone 8初学者开发—第14部分:在运行时绑定到真实的数据 第14部分:在运行时绑定到真实的数据 原文地址: http://channel9.msdn.com/Series/ ...
- 页面跳转时,url 传大数据的参数不全的问题+序列化对象
1.页面跳转时,url 传大数据的参数不全的问题 //传参: url: '/pages/testOfPhysical/shareEvaluation?detailInfo=' +encodeURICo ...
- PDO exec 执行时出错后如果修改数据会被还原?
PDO exec 执行时出错后如果修改数据会被还原? 现象 FastAdmin 更新了 1127 版本,但是使用在线安装方式出现无法修改管理员密码的问题. 一直是默认的 admin 123456 密码 ...
- SQL获取当前日期的年、月、日、时、分、秒数据
SQL Server中获取当前日期的年.月.日.时.分.秒数据: SELECT GETDATE() as '当前日期',DateName(year,GetDate()) as '年',DateName ...
- js中对arry数组的各种操作小结 瀑布流AJAX无刷新加载数据列表--当页面滚动到Id时再继续加载数据 web前端url传递值 js加密解密 HTML中让表单input等文本框为只读不可编辑的方法 js监听用户的键盘敲击事件,兼容各大主流浏览器 HTML特殊字符
js中对arry数组的各种操作小结 最近工作比较轻松,于是就花时间从头到尾的对js进行了详细的学习和复习,在看书的过程中,发现自己平时在做项目的过程中有很多地方想得不过全面,写的不够合理,所以说啊 ...
随机推荐
- UML和模式应用4:初始阶段(4)--需求制品之用例模型模板示例
1. 前言 UP开发包括四个阶段:初始阶段.细化阶段.构建阶段.移交阶段: UP每个阶段包括 业务建模.需求.设计等科目: 其中需求科目对应的需求制品包括:设想.业务规则.用例模型.补充性规格说明.词 ...
- kafka系列五、kafka常用java API
引入maven包 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka- ...
- openstack swift节点安装手册1-节点配置
本文参照官方教程:http://docs.openstack.org/project-install-guide/object-storage/draft/environment-networking ...
- nagios系列(六)之nagios实现对服务器cpu温度的监控
1.安装硬件传感器监控软件sensors yum install -y lm_sensors* 2.运行sensors-detect进行传感器检测 ##一路回车即可 Do you want to ov ...
- lvs持久连接及防火墙标记实现多端口绑定服务
lvs持久连接及防火墙标记实现多端口绑定服务 LVS持久连接: PCC:将来自于同一个客户端发往VIP的所有请求统统定向至同一个RS: PPC:将来自于一个客户端发往某VIP的某端口的所有请求统统定向 ...
- labelImg:no module named pyqt4
最新版的labelImg安装会出错,改变环境变量,在python3.5中就可以了 参考 shaform :https://github.com/tzutalin/labelImg/issues/106
- CNN中各种各样的卷积
https://zhuanlan.zhihu.com/p/29367273 https://zhuanlan.zhihu.com/p/28749411 以及1*1卷积核:https://www.zhi ...
- Java 清理和垃圾回收
java.lang.ref.cleaner包 finalize()//该方法已过时,有风险,慎用 1.对象不可能被垃圾回收 2.垃圾回收并不等于"析构" 只有当垃圾回收发生时fin ...
- codeforce 139E
成段更新+离散化才能过,数据好强.. 单点更新挂在了test27,下次做到成段更新再来做! /* 期望=存活概率*点权值/100 ans=sum(期望) 离散化树木权值,数轴统计累加可能倒下的树木概率 ...
- 用PNChart绘制饼状图简介
写在前面 最近做的小Demo中有一个绘制饼状图的需求.在开始实现之前上网了解了一下现有的一些绘制图形的第三方库,相应的库还是有挺多的,PNChart便是其中一个.PNChart是一个90后的中国boy ...