机器学习预测时label错位对未来数据做预测
前言
这篇文章时承继上一篇机器学习经典模型使用归一化的影响。这次又有了新的任务,通过将label错位来对未来数据做预测。
实验过程
使用不同的归一化方法,不同得模型将测试集label错位,计算出MSE的大小;
不断增大错位的数据的个数,并计算出MSE,并画图。通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据处理(和上一篇的处理方式相同):
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] sort_data1 = _sort_data[:]
sort_data2 = _sort_data[:]
sort_target1 = _sort_target[:]
sort_target2 = _sort_target[:]
完整数据处理代码:
#按时间排序
sort_data = data.sort_values(by = 'time',ascending = True) sort_data.reset_index(inplace = True,drop = True)
target = data['T1AOMW_AV']
sort_target = sort_data['T1AOMW_AV']
del data['T1AOMW_AV']
del sort_data['T1AOMW_AV'] from sklearn.model_selection import train_test_split
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] _sort_data = sort_data[:]
_sort_target = sort_target[:] from sklearn.model_selection import train_test_split
test_sort_data = sort_data[:]
test_sort_target = sort_target[:] sort_data1 = _sort_data[:]
sort_data2 = _sort_data[:]
sort_target1 = _sort_target[:]
sort_target2 = _sort_target[:] import scipy.stats as stats
dict_corr = {
'spearman' : [],
'pearson' : [],
'kendall' : [],
'columns' : []
} for i in data.columns:
corr_pear,pval = stats.pearsonr(sort_data[i],sort_target)
corr_spear,pval = stats.spearmanr(sort_data[i],sort_target)
corr_kendall,pval = stats.kendalltau(sort_data[i],sort_target) dict_corr['pearson'].append(abs(corr_pear))
dict_corr['spearman'].append(abs(corr_spear))
dict_corr['kendall'].append(abs(corr_kendall)) dict_corr['columns'].append(i) # 筛选新属性
dict_corr =pd.DataFrame(dict_corr)
dict_corr.describe()
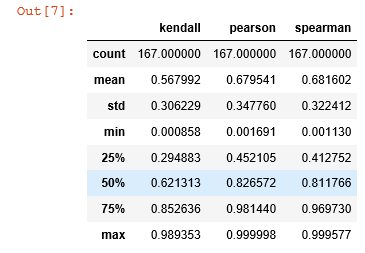
选取25%以上的;
new_fea = list(dict_corr[(dict_corr['pearson']>0.41) & (dict_corr['spearman']>0.45) & (dict_corr['kendall']>0.29)]['columns'].values)
包含下面的用来画图:
import matplotlib.pyplot as plt
lr_plt=[]
ridge_plt=[]
svr_plt=[]
RF_plt=[]
正常的计算mse(label没有移动):
from sklearn.linear_model import LinearRegression,Lasso,Ridge
from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler
from sklearn.metrics import mean_squared_error as mse
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
#最大最小归一化
mm = MinMaxScaler() lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(sort_data2[new_fea]))
lr_mse=mse(lr_ans,sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(sort_data2[new_fea]))
svr_mse=mse(svr_ans,sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea]))
RF_mse=mse(predict_RF,sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=, max_depth=, min_child_weight=, seed=,
subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=, reg_lambda=)
bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
bst_ans = bst.predict(mm.transform(sort_data2[new_fea]))
print('bst:',mse(bst_ans,sort_target2))
先让label移动5个:
change_sort_data2 = sort_data2.shift(periods=,axis=)
change_sort_target2 = sort_target2.shift(periods=-,axis=)
change_sort_data2.dropna(inplace=True)
change_sort_target2.dropna(inplace=True)
让label以5的倍数移动:
mm = MinMaxScaler() for i in range(,,):
print(i)
lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea]))
lr_mse=mse(lr_ans,change_sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,change_sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea]))
svr_mse=mse(svr_ans,change_sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea]))
RF_mse=mse(predict_RF,change_sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=, max_depth=, min_child_weight=, seed=,
# subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=, reg_lambda=)
# bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
# bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea]))
# print('bst:',mse(bst_ans,change_sort_target2)) change_sort_target2=change_sort_target2.shift(periods=-,axis=)
change_sort_target2.dropna(inplace=True)
change_sort_data2 = change_sort_data2.shift(periods=,axis=)
change_sort_data2.dropna(inplace=True)
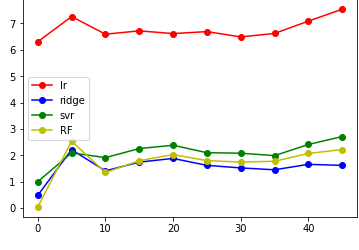
结果如图:
然后就是画图了;
plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='ridge',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
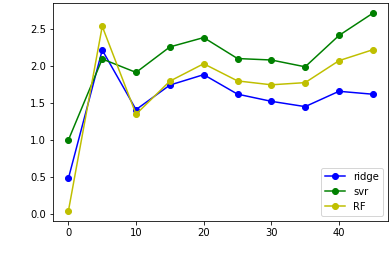
舍去lr,并扩大纵坐标:
#plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='ridge',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
其他模型只需将MinMaxScaler改为MaxAbsScaler,standarScaler即可;
总的来说,label的移动会使得mse增加,大约在label=10时候差异最小,结果最理想;
机器学习预测时label错位对未来数据做预测的更多相关文章
- 机器学习数据处理时label错位对未来数据做预测
这篇文章继上篇机器学习经典模型简单使用及归一化(标准化)影响,通过将测试集label(行)错位,将部分数据作为对未来的预测,观察其效果. 实验方式 以不同方式划分数据集和测试集 使用不同的归一化(标准 ...
- 好未来数据中台 Node.js BFF实践(一):基础篇
好未来数据中台 Node.js BFF实践系列文章列表: 基础篇 实战篇(TODO) 进阶篇(TODO) 好未来数据中台的Node.js中间层从7月份开始讨论可行性,截止到9月已经支持了4个平台,其中 ...
- kaggle——分销商产品未来销售情况预测
分销商产品未来销售情况预测 介绍 前面的几个实验中,都是根据提供的数据特征来构建模型,也就是说,数据集中会含有许多的特征列.本次将会介绍如何去处理另一种常见的数据,即时间序列数据.具体来说就是如何根据 ...
- 用$.getJSON() 和$.post()获取第三方数据做页面 ——惠品折页面(1)
用$.getJSON() 和$.post()获取第三方数据做页面 首页 index.html 页面 需要jquery 和 template-web js文件 可以直接在官网下载 中间导航条的固 ...
- 使用FormData数据做图片上传: new FormData() canvas实现图片压缩
使用FormData数据做图片上传: new FormData() canvas实现图片压缩 ps: 千万要使用append不要用set 苹果ios有兼容问题导致数据获取不到,需要后台 ...
- 【机器学习PAI实战】—— 玩转人工智能之商品价格预测
摘要: 我们经常思考机器学习,深度学习,以至于人工智能给我们带来什么?在数据相对充足,足够真实的情况下,好的学习模型可以发现事件本身的内在规则,内在联系.我们去除冗余的信息,可以通过最少的特征构建最简 ...
- 机器学习实战笔记(一)- 使用SciKit-Learn做回归分析
一.简介 这次学习的书籍主要是Hands-on Machine Learning with Scikit-Learn and TensorFlow(豆瓣:https://book.douban.com ...
- 机器学习可解释性系列 - 是什么&为什么&怎么做
机器学习可解释性分析 可解释性通常是指使用人类可以理解的方式,基于当前的业务,针对模型的结果进行总结分析: 一般来说,计算机通常无法解释它自身的预测结果,此时就需要一定的人工参与来完成可解释性工作: ...
- 背水一战 Windows 10 (20) - 绑定: DataContextChanged, UpdateSourceTrigger, 对绑定的数据做自定义转换
[源码下载] 背水一战 Windows 10 (20) - 绑定: DataContextChanged, UpdateSourceTrigger, 对绑定的数据做自定义转换 作者:webabcd 介 ...
随机推荐
- Linux软件包管理和磁盘管理实践
一.自建yum仓库,分别为网络源和本地源 本地yum仓库的搭建就是以下三个步骤: 创建仓库目录结构 上传相应的包到目录下,或者直接挂载光盘也行,如果挂载光盘,第三步就可以省略,因为光盘默认里有repo ...
- 大数据HDFS相关的一些运维题
1.在 HDFS 文件系统的根目录下创建递归目录“1daoyun/file”,将附件中的BigDataSkills.txt 文件,上传到 1daoyun/file 目录中,使用相关命令查看文件系统中 ...
- 网站搭建-2-本地网站搭建-安装Linux虚拟机/ 安装IIS Windows
搭建网站-1-域名申请参见公众号 生物信息系统(swxxxt) 首先,已经拥有了一个可以正常使用的域名. 之前买了两年的阿里的服务器,由于是Windows的,最后不了了之了(因为当时找的代码都是lin ...
- phpStudy中MySQL版本升级到5.7.17方法
本文主要给大家介绍了关于phpStudy中升级MySQL版本到5.7.17的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起看看吧.希望能帮 ...
- nyoj 63-小猴子下落 (模拟)
63-小猴子下落 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:2 submit:5 题目描述: 有一颗二叉树,最大深度为D,且所有叶子的深度都相同 ...
- Tarjan-割点
割点——tarjan #include <bits/stdc++.h> using namespace std; ; ; int n, m; int ans;//个数 * MAXM], n ...
- Mac下载ChromeDriver
ChromeDriver下载地址: https://npm.taobao.org/mirrors/chromedriver 如何查看chrome版本与ChromeDriver版本对应 查看chrome ...
- 网络图片的获取以及二级缓存策略(Volley框架+内存LruCache+磁盘DiskLruCache)
在开发安卓应用中避免不了要使用到网络图片,获取网络图片很简单,但是需要付出一定的代价——流量.对于少数的图片而言问题不大,但如果手机应用中包含大量的图片,这势必会耗费用户的一定流量,如果我们不加以处理 ...
- scala学习系列二
一 scala语言开发注意事项: 1 Scala程序的执行入口是main()函数 2 Scala语言严格区分大小写. 3 Scala方法由一条条语句构成,每个语句后不需要分号(Scala语言会在每行后 ...
- No provider available for the service com.xxx.xxx 错误解决
HTTP Status 500 - Servlet.init() for servlet springmvc threw exception type Exception report message ...