论文阅读:Videos as Space-Time Region Graphs
Videos as Space-Time Region Graphs
ECCV 2018 Xiaolong Wang
2018-08-03 11:16:01
Paper:arXiv
本文利用视频中时空上的 proposal 之间的关系,来进行行为识别的建模。

如上图所示,本文将 video 看做是 a graph of objects,然后在该 graph 上进行行为识别的推理。整体的模型如图 2 所示,该方法将视频连续 5 秒的视频作为输入,传递给 3D-CNN。3D CNN 的输出是一个四维的特征图,维度为:T*H*W*d,其中,T 代表时间维度,H*W 代表了空间维度,d 代表了 channel number。
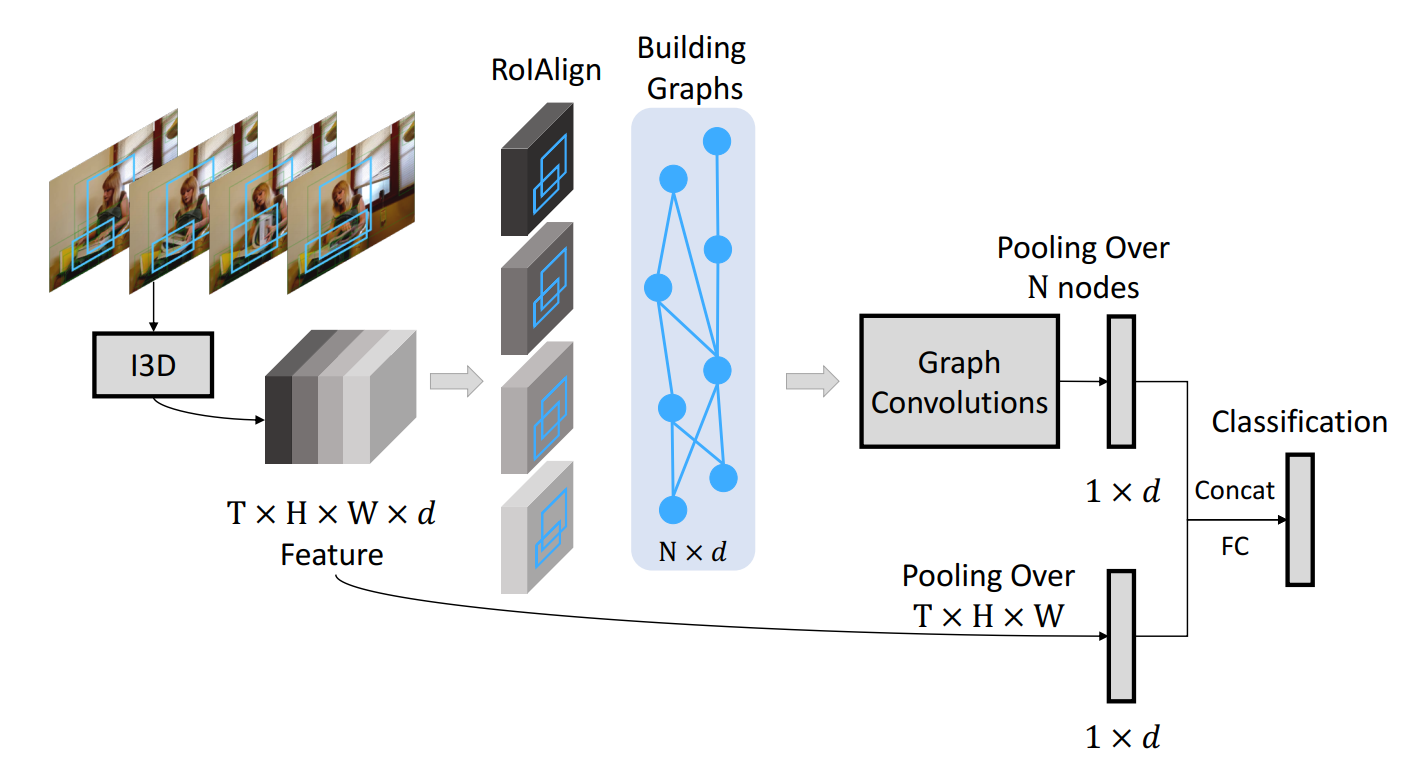
除了提取视频的特征之外,我们采用 RPN 来提取物体的 proposals。给定 T feature frames 的每一个 BBox,我们采用 RoIAlign 来提取每一个 BBox 的 feature。RoIAlign 是独立的在每一个 feature map 上进行特征提取的。有了 graph representations, 我们采用 GCN 来进行推理。我们执行 average pooling 来获取 d-dimensional feature。除了 GCN features,我们也采用 average pooling 来获得 the same d-dimension feature as a global feature。这两个特征被 concatenate 到一起,进行 video level classification。
Graph Representations in Videos:
1). Video representation:
Video Backbone Model:(略)
Region Proposal Network:(略)
2). Similarity Graph:
我们通过在特征空间衡量 objects 之间的相似性,来构建 similarity graph。在这个 graph 当中,我们构建语义上相关的物体对。具体来说,我们会给予下面两种 instances 较高的 edge:
(1)the same object in different states in different video frames ;
(2)highly correlated for recognizing the actions.
注意到:相似的 edges,在任何两对 objects 之间都会进行计算。
正式的来说,假设我们已经有了所有的 object proposals 的 feature,那么,两个 proposal 之间的相似性可以表达为:
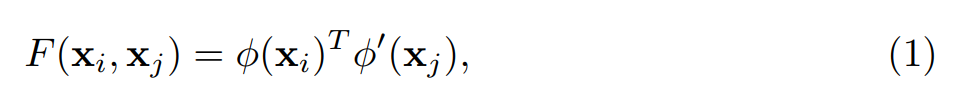
其中,这两个函数分别代表了原始 features 的不同转换。特别的,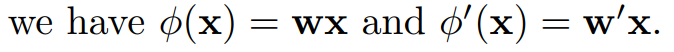 其中参数 W 和 W' 都是 d * d 维的 weights,并且都是可以通过反向传播进行学习的。通过添加转换权重 W 和 W’,这允许我们不但可以学习到 the correlations between different states of the same object instance across frame,也可以学习到 不同 objects 之间的关系。
其中参数 W 和 W' 都是 d * d 维的 weights,并且都是可以通过反向传播进行学习的。通过添加转换权重 W 和 W’,这允许我们不但可以学习到 the correlations between different states of the same object instance across frame,也可以学习到 不同 objects 之间的关系。
在计算出 affinity matrix 之后,我们在矩阵的每一行执行 normalization,使得:the sum of all the edge values connected to one proposal i will be 1. 我们利用 softmax 来执行这个 normalization:
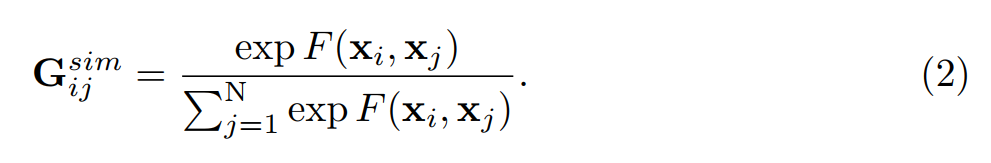
归一化之后的 G,被认为是 the adjacency matrix 代表 similarity graph。
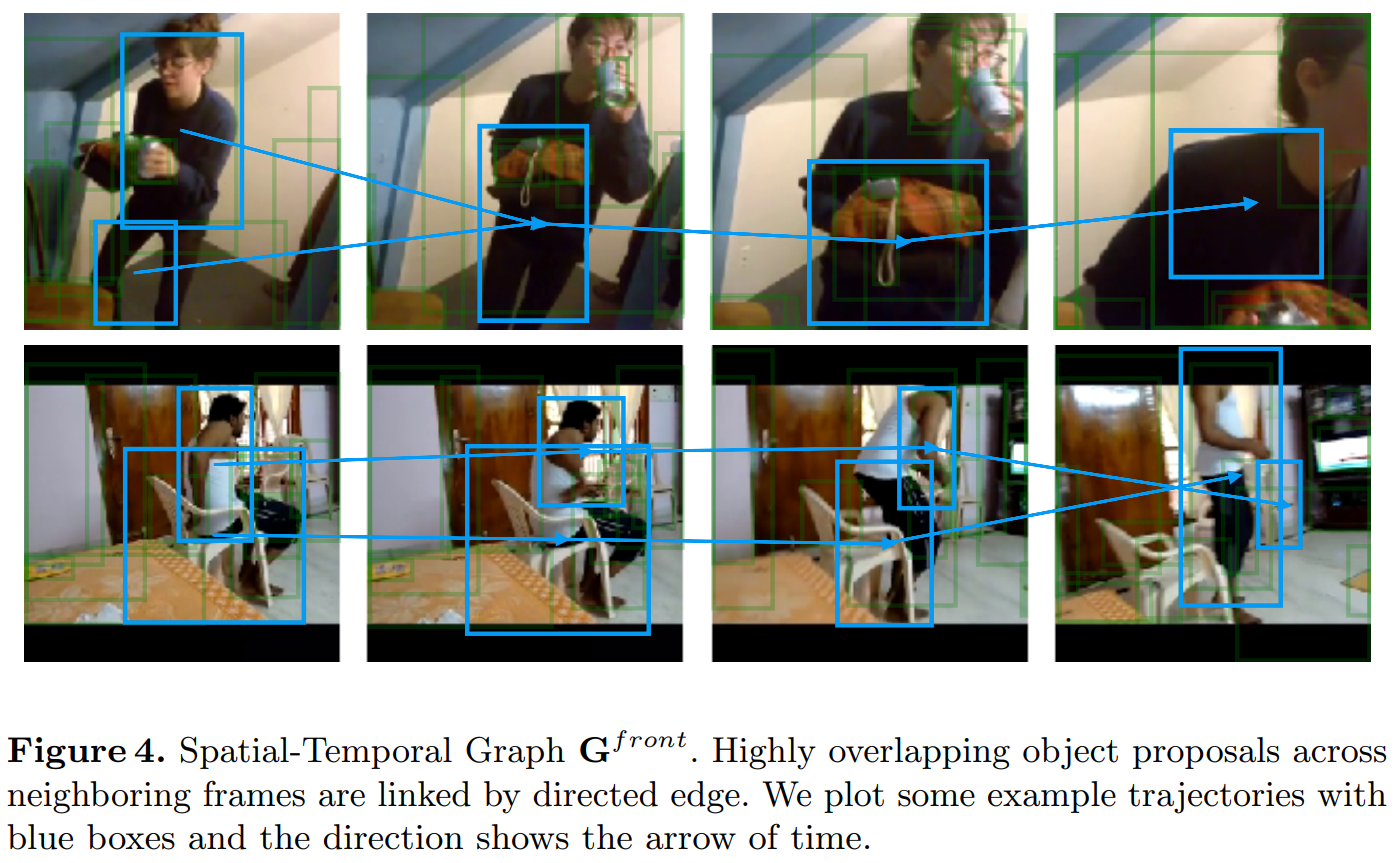
3). Spatial-Temporal Graph:
虽然,similarity graph 捕获了 the long term dependencies between any two object proposals,但是它依然没有捕获到 object 和 the ordering of the state change 之间的 the relative spatial relation。为了编码 objects 之间 spatial 和 temporal relations,我们提出利用 spatial-temporal graphs,来将时间和空间位置附近的 proposal 也联系起来。
给定第 t 帧的 object proposals,我们计算 当前 BBox 跟下一帧 BBox 的 IoUs。如果重合度大于 0,那么,我们将这两个 object 用有向边 i -> j 连接起来。在赋予 edge values 之后,我们也对这个 graph 进行归一化:

注意到,这里仅仅是 front 的 graph,作者还构建了 backward 的 graph,以得到更多有有效的结构上的信息。
Convolutions on Graphs:
本文采用 gcn 的图卷积网络:Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: International Conference on Learning Representations (ICLR). (2017)
为了在 graph 上进行推理,我们采用了 GCN 模型。与传统标准的 convolutional network 不同,他们是在 局部规则的网格数据上进行操作(which operates on a local regular grid),而 graph convolutions 允许我们通过 graph relations,根据其近邻的情况,计算一个 node 的响应(allow us to compute the response of a node based on its neighbors defined by the graph relations)。所以,执行图卷积就等价于执行 graph 内部的信息传递。GCNs 的输出是每一个节点更新之后的 feature,这个 feature 可以被整合起来用于视频分类。正式的,我们将 graph convolutional layer 可以定义为:
Z = GXW, (4)
其中,G 代表近邻 graph (the adjacency graph),维度为:N*N,X 是 graph 中每一个节点的 feature,大小为 N * d,W 是权重矩阵(weight matrix,大小为 d*d)。所以,一个 graph convolutional layer 的输出 Z 仍然是 N * d 维的。而且,这种 graph convolutional layers 可以被堆叠多层。在每一层 GC 之后,在将 Z 正式传输到下一层之前,我们采用两个非线性激活函数(the Layer Normalization and ReLU)。
为了结合 GCNs 的多个 graphs,我们简单的将公式(4)进行拓展,即:

其中,Gi 代表不同种类的 graph,而不同的图,权重是不共享的。但是,作者发现:直接通过公式(5)组合三个 graph($G^{sim}, G^{front}, G^{back}$)缺让精度降低了(相对于 单个 similarity graph 的情况)。
作者分析了原因:我们的 similarity graph $G^{sim}$ 包含需要学习的参数,在更新的时候是需要反向传播的,但是另外两个 graps 是不需要学习的。在每一个 GCN layer 上融合这些 feature,优化起来是非常困难的。所以,我们构建了 GCN 的两个分支,然后仅仅在最后将这两个 GCNs 进行融合。这两支 GCNs 分别进行卷积操作(L layers),卷积的最后一层,叠加起来,行成 N*d 维度的输出。
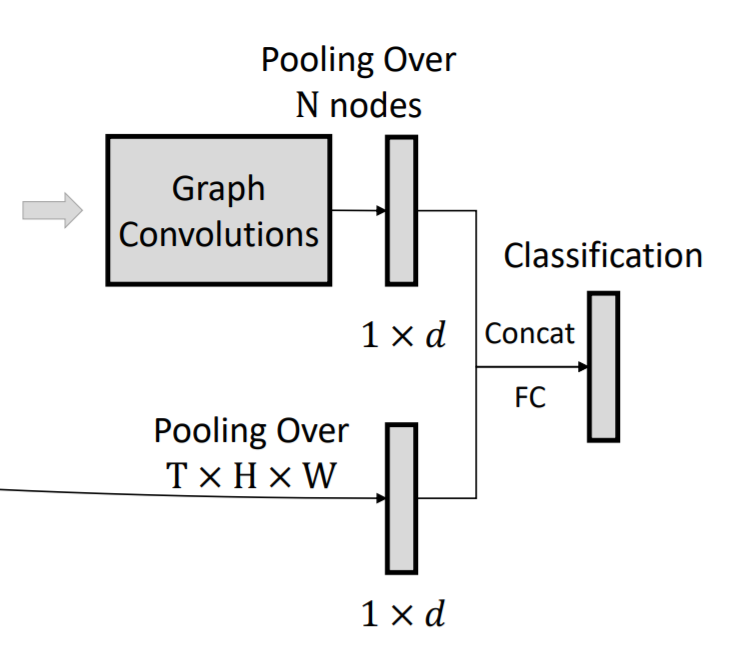
Video Classification.
作者将 GCNs 的输出和未进行图卷积的特征,进行 concatenate,然后输入给分类器,进行分类,如图所示:
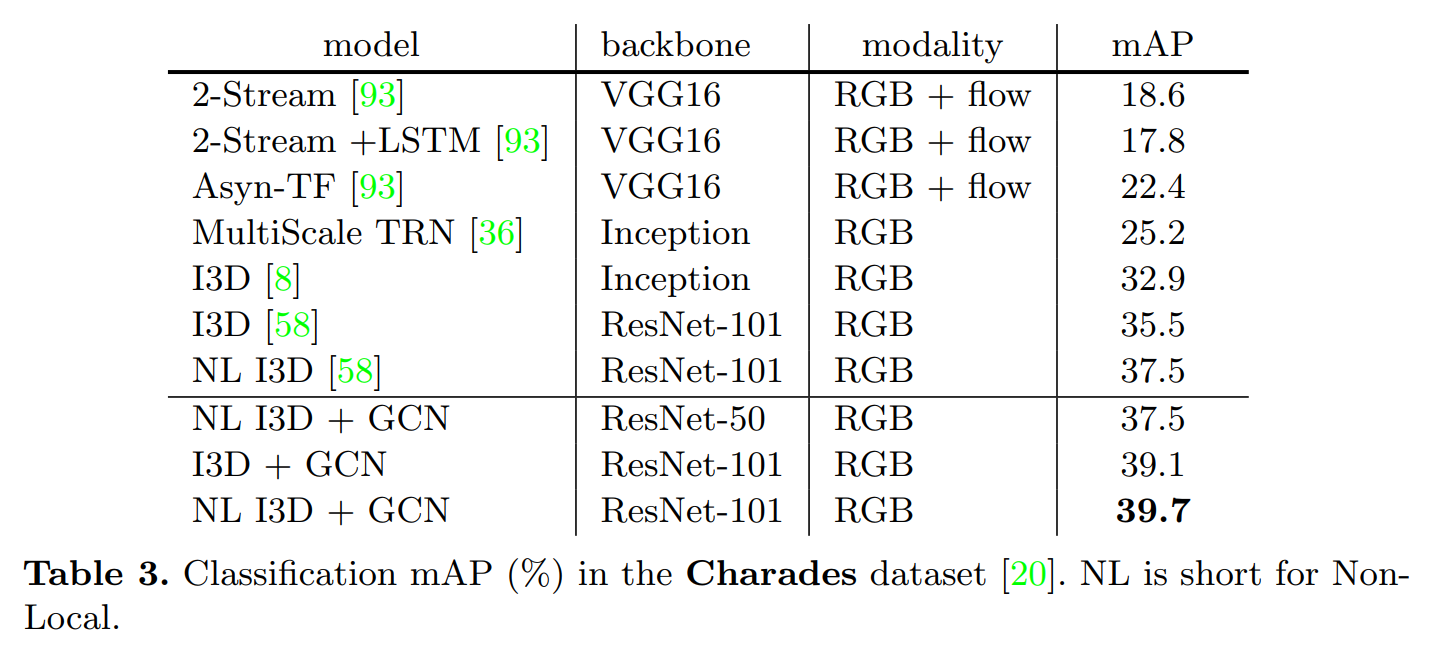
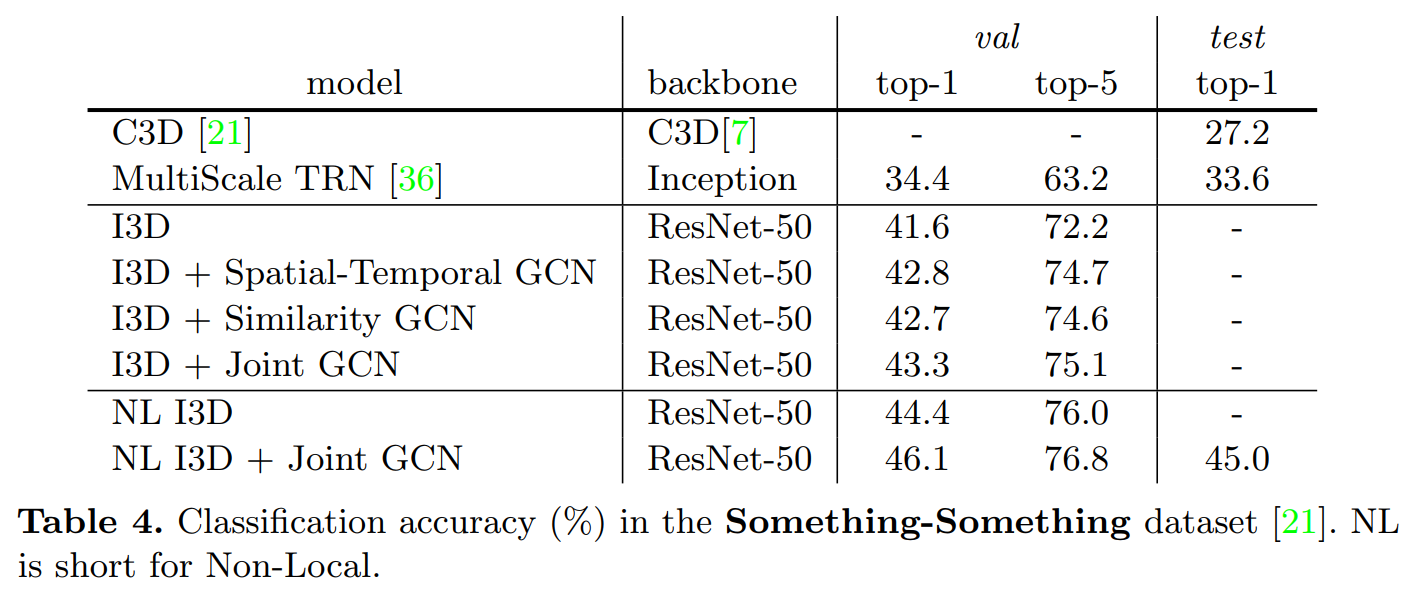
Experiments:
论文阅读:Videos as Space-Time Region Graphs的更多相关文章
- 论文阅读 DyREP:Learning Representations Over Dynamic Graphs
5 DyREP:Learning Representations Over Dynamic Graphs link:https://scholar.google.com/scholar_url?url ...
- 论文阅读 Inductive Representation Learning on Temporal Graphs
12 Inductive Representation Learning on Temporal Graphs link:https://arxiv.org/abs/2002.07962 本文提出了时 ...
- 论文阅读 | Region Proposal by Guided Anchoring
论文阅读 | Region Proposal by Guided Anchoring 相关链接 论文地址:https://arxiv.org/abs/1901.03278 概述 众所周知,anchor ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- 【论文阅读】Motion Planning through policy search
想着CSDN还是不适合做论文类的笔记,那里就当做技术/系统笔记区,博客园就专心搞看论文的笔记和一些想法好了,[]以后中框号中间的都算作是自己的内心OS 有时候可能是问题,有时候可能是自问自答,毕竟是笔 ...
- AlphaTensor论文阅读分析
AlphaTensor论文阅读分析 目前只是大概了解了AlphaTensor的思路和效果,完善ing deepmind博客在 https://www.deepmind.com/blog/discove ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
随机推荐
- Python读取excel数据类型处理
一.python xlrd读取datetime类型数据:https://blog.csdn.net/y1535766478/article/details/78128574 (1)使用xlrd读取出来 ...
- Python 3 -- 数据结构(list, dict, set,tuple )
看了<Head First Python>后,觉得写的很不错,适合新手.此处为读书笔记,方便日后查看. Python 提供了4中数据结构:list,dict,set,tuple. 每种结构 ...
- Java多线程-----实现生产者消费者模式的几种方式
1 生产者消费者模式概述 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题.生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理 ...
- Linux基础命令---显示登录用户logname
logname 显示当前登录的用户名称.此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 1.语法 logname 2 ...
- 高性能NIO框架Netty入门篇
http://cxytiandi.com/blog/detail/17345 Netty介绍 Netty是由JBOSS提供的一个java开源框架.Netty提供异步的.事件驱动的网络应用程序框架和工具 ...
- Spring Boot 中使用 @ConfigurationProperties 注解
@ConfigurationProperties 主要作用:绑定 application.properties 中的属性 例如: @Configuration public class DataSou ...
- 全球最大的3D数据集公开了!标记好的10800张全景图
Middlebury数据集 http://vision.middlebury.edu/stereo/data/ KITTI数据集简介与使用 https://blog.csdn.net/solomon1 ...
- Maven笔记 #01# 入门
索引 Maven是干什么的? 用Maven的好处 Maven与命令行 Maven与IntelliJ IDEA 一.Maven是干什么的? 我相信只要你写过足够多的代码,就... 肯定有思考过写一个脚本 ...
- Hbuilder安装
---恢复内容开始--- ---恢复内容结束---
- Python-OpenCV基本操作cv2
1.图片加载.显示和保存 import cv2 # 生成图片 img = cv2.imread("1.jpg") # 生成灰色图片 imgGrey = cv2.imread(&qu ...