论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 问题讨论
- 总结与收获点
- 参考文献
作者和相关链接
- 作者
- Zhuoyao Zhong, z.zhuoyao@mail.scut.sdu.cn
Lianwen Jin, lianwen.jin@gmail.com
Shuye Zhang, shuye.cheung@gmail.com
Ziyong Feng, feng.ziyong@mail.scut.edu.cn - School of Electronic and Information Engineering South China University of Technology Guangzhou, China
- Zhuoyao Zhong, z.zhuoyao@mail.scut.sdu.cn
- 论文下载
- 作者
方法概括
- 方法称为DeepText(此方法不是Google的DeepText哦),先用Inception-RPN提取候选的单词区域,再利用一个text-detection网络过滤候选区域中的噪声区域,最后对重叠的box进行投票和非极大值抑制
创新点和贡献
- 对fasterRCNN进行改进用在文字检测上
- Inception-RPN:RPN后接Inception,来提取候选单词区域(包括2类classification和box regression)
- anchor的大小更加适合检测单词:4scales(32, 48, 64, 80)*6 aspect ratio(0.2, 0.5, 0.8, 1.0, 1.2, 1.5) = 24种prior bounding box
- Inception:3*3 conv, 5*5 conv, 3*3 max-pooling
- Multi-level region-of-interest pooling(MLRP): ROI pooling从原来只用Conv5变成了Conv5+Conv4的两层(MLRP)
- Ambiguous Text Category(ATC): 把文字和非文字的两类变成了三类,文字(IOU>0.5),非文字(IOU<0.2),有歧义的文字(IOU在0.2~0.5之间),原理是加入了更多的监督信息,使得分类效果更好
- Inception-RPN:RPN后接Inception,来提取候选单词区域(包括2类classification和box regression)
- 对重叠box的去重方法(亮点不多)
- 实验结果(F值)很高,ICDAR2011-0.83,ICDAR2013-0.85,速度约是平均每张图像1.7s(gpu k40)
- 对fasterRCNN进行改进用在文字检测上
方法细节
- 网络框架图(Inception-RPN+text detection):两个网络,Inception-RPN和text detection网络共享了conv1~conv5(来自于VGG16)。
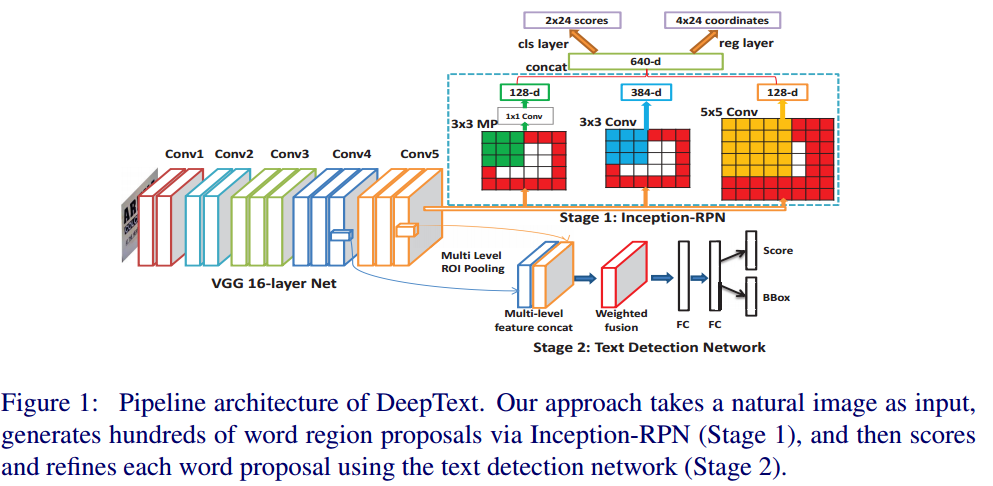
- 实际测试时流程:
- 输入一张图像,经过Conv1~Conv5生成卷积后的feature map
- feature map输入到Inception-RPN得到候选区域(score, bounding box)
- 候选区域经过非极大值抑制,选择前k个proposals
- 把k个proposals对应的在1.中Conv5生成的feature map上提取每个proposal的卷积特征,输入到text detection网络中得到每个proposal的score和Bounding box(regression调整过的)
- 对得到的检测结果(重复,互相包含)进行迭代投票和过滤,找到分数最高的最优检测结果
- Ambiguous Text Category(ATC)的出发点
- 如下图,按照一般的IOU>0.5为正样本,IOU<0.5为负样本,会导致单词串的某一段本该属于正样本的被当做负样本,对分类造成干扰,因此,更好的方法是把IOU>0.5的当正样本,IOU<0.2的当负样本,IOU处在中间的这部分单独成一类,表示歧义的一类,这样会使得分类准确率更高
- 实际测试时流程:

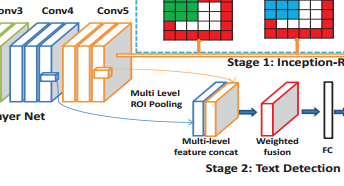
- Multi-level region-of-interest pooling(MLRP)的修改
- VGG-16的模型配置
- Multi-level region-of-interest pooling(MLRP)的修改

- ROI Pooling的修改:将Conv4_3和Conv5_3(即Conv4的第三层卷积和Conv5的第三层卷积)的feature map单独进行ROI pooling,再把这两层Pooling后的feature map用一个1*1的卷积进行融合,这里1*1的卷积除了融合多通道(两层)信息,还有一个作用,就是降维,为下一步的FC做准备。
- 训练过程
- 多任务损失函数
- 总的损失(p和p*表示测试和gt的label, t和t*是测试和gt的bounding box,t = {tx, ty,tw, th}
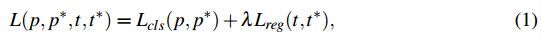
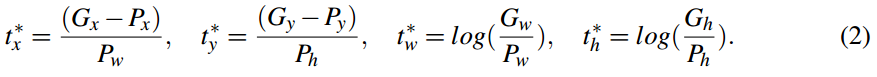
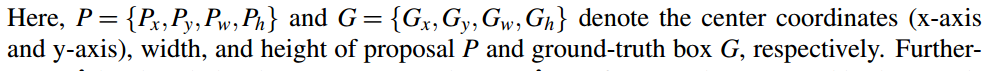
- Lcls是softmax loss,分类误差(下图参考softmax回归)

- Lreg是smooth-L1 loss,回归误差(下图来自论文参考文献1)
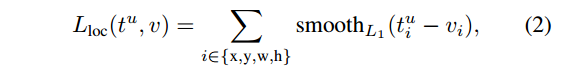
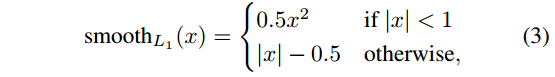
- 详细算法过程(讲真,太详细了有点)

- 算法思路简述:同一个样本,先用Inception-RPN训练,再训练text detection网络,detection网络要从Inception-RPN网络中选择,最后的时候更新整个网络权值,共享的部分要把两个模块的权值更新都加上。
- 启发式后处理
- 包括迭代bounding box的投票(参考文献2)和过滤两个部分,实际上就是个去重的过程,文章细节也没怎么讲
实验结果
- 值得一提的是文中的模型训练数据竟然只有4072个样本!!!
- 证明Inception-RPN比原始RPN,SS,Edgebox等方法好

- 证明MLRP和ATC的作用
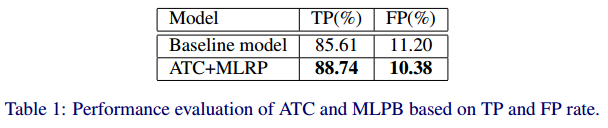
- ICDAR2011

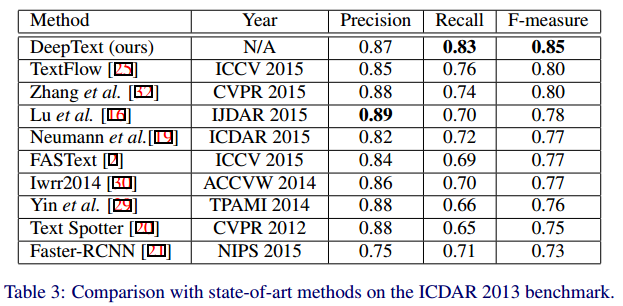
- ICDAR2013
- 效果示例图

问题讨论
- 文中没有给出中间结果的示例图,比如inception-RPN之后得到的结果
总结与收获点
- 文中比较好的参考点是作者对fasterRCNN做的几个改进(在创新点中总结了)
- 从实验结果上看,无论是F值还是速度,都确实挺好的,学习了~~
- 一直想看的几篇文章,先mark一下
- M. Busta, L. Neumann, and J. Matas. Fastext: Efficient unconstrained scene text detector. In Proc. ICCV, 2015.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proc. CVPR, 2015.
- A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arxiv preprint arXiv:1601.07140, 2016.
- X. Yin, X. Yin, K. Huang, and H. Hao. Robust text detection in natural scene images. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 36(5):970– 983, 2014.
- S. Zhang, M. Lin, T. Chen, L. Jin, and L. Lin. Character proposal network for robust text extraction. In Proc. ICASSP, 2016.
参考文献
- R. Girshick. Fast r-cnn. In Proc. ICCV, 2015.
- S. Gidaris and N. Komodakis. Object detection via a multiregion & semantic segmentation-aware cnn model. In Proc. ICCV, 2015.
论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)的更多相关文章
- 论文阅读笔记三:R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection(CVPR2017)
进行文本的检测的学习,开始使用的是ctpn网络,由于ctpn只能检测水平的文字,而对场景图片中倾斜的文本无法进行很好的检测,故将网络换为RRCNN(全称如题).小白一枚,这里就将RRCNN的论文拿来拜 ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)
论文源址:https://arxiv.org/abs/1506.02640 tensorflow代码:https://github.com/nilboy/tensorflow-yolo 摘要 该文提出 ...
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- 论文阅读:CNN-RNN: A Unified Framework for Multi-label Image Classification
CNN-RNN: A Unified Framework for Multi-label Image Classification Updated on 2018-08-07 22:30:41 Pap ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- ANSI_NULLS和QUOTED_IDENTIFIER
这些是 SQL-92 设置语句,使 SQL Server 2000/2005 遵从 SQL-92 规则. 当 SET QUOTED_IDENTIFIER 为 ON 时,标识符可以由双引号分隔,而文字必 ...
- python中常用的一些字符串
capitalize() 把字符串的第一个字符改为大写 casefold() 把整个字符串的所有字符改为小写 center(width) 将字符串居中,并使用空格填充至长度 width 的新字符串 c ...
- 移动端lCalendar纯原生js日期时间选择器
网上找过很多的移动端基于zepto或jquery的日期选择器,在实际产品中也用过一两种,觉得都不太尽如人意,后来果断选择了H5自己的日期input表单,觉得还可以,至少不用引用第三方插件了,性能也不错 ...
- jQuery触发a标签点击事件-为什么不跳转
今天开发发现 使用jQuery触发a标签的点击事件,当前的样式发生了变化,可是没有跳转,为什么? 百度后找到的解决方案: <a onclick="hanle()" href= ...
- Swift与OC混编
OC调用Swift的方法:添加 import "xxxx-Swift.h" 头文件即可 Swift调用OC的方法:需要建立桥接: xxxx-Bridging-Header.h 头文 ...
- XSS攻击
什么是XSS? http://www.cnblogs.com/bangerlee/archive/2013/04/06/3002142.html XSS攻击及防御? http://blog.csdn. ...
- canvas中的rotate的使用方法
今天在绘制一个足球滚动的时候,想使用rotate方法,之前看到这个方法的时候,并没有引起任何重视,无非就是和CSS3里的rotate一样的用么... 遗憾的是,事实并非如此,由于代码在公司,我也就不去 ...
- mockito使用心得
前提:pom引用<dependency> <groupId>junit</groupId> <artifactId>junit</artifact ...
- PHP 正则表达式匹配中文字符
例如在 MySQL 的 bin-log 文件中选取特定的数据库语句来恢复数据时,只要选出某个库的 INSERT INTO 操作(去掉了多余信息,只列出 SQL 语句) INSERT INTO `crm ...
- php数字索引数组去重及恢复索引
$tmp = array('a','b','c','a'); $tmp = array_values(array_unique($tmp)); print_r($tmp);exit; //输出 Arr ...