机器学习算法_knn(福利)
这两天翻了一下机器学习实战这本书,算法是不错,只是代码不够友好,作者是个搞算法的,这点从代码上就能看出来。可是有些地方使用numpy搞数组,搞矩阵,总是感觉怪怪的,一个是需要使用三方包numpy,虽然这个包基本可以说必备了,可是对于一些新手,连pip都用不好,装的numpy也是各种问题,所以说能不用还是尽量不用,第二个就是毕竟是数据,代码样例里面写的只有几个case,可是实际应用起来,一定是要上数据库的,如果是array是不适合从数据库中读写数据的。因此综合以上两点,我就把这段代码改成list形式了,当然,也可能有人会说我对numpy很熟悉啊,而且作为专业的数学包,矩阵的运算方面也很方便,我不否定,那我这段代码恐怕对你不适合,你可以参考书上的代码,直接照打并理解就好了。
knn,不多说了,网上书上讲这个的一大堆,简单说就是利用新样本new_case的各维度的数值与已有old_case各维度数值的欧式距离计算
欧式距离这里也不说了,有兴趣可以去翻我那篇python_距离测量,里面写的很详细,并用符号展示说明,你也可以改成棋盘距离或街区距离试试,速度可能会比欧式距离快,但还是安利欧式距离。
有一点没搞明白的就是,对坐标进行精度化计算这块,实测后确定使用直接计算无论是错误率还是精度,处理前都要比处理后更准确,可能原代码使用小数点的概率更高些吧,也许这个计算对于小数计算精度更有帮助
闲话一些,不多也不少,下面上代码,代码中配有伪代码,方便阅读,如果还看不太明白可以留言,我把详细注释加上
以下是代码中使用颜色,选用html的16进制RGB颜色,在应用时将其转换为10进制数字计算,old_case选取红色圈,new_case选取橙色圈
紫色(茄子颜色)

绿色(黄瓜颜色)
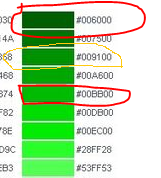
黄色(香蕉颜色)

淡绿(西葫芦颜色)

代码见下
#!/usr/bin//python
# coding: utf-8 '''
1、获取key和coord_values,样例使用的是list,但是如果真正用在训练上的话list就不适合了,建议改为使用数据库进行读取
2、对坐标进行精度化计算,这个其实我没理解是为什么,可能为了防止错误匹配吧,书上是这样写的
3、指定两个参数,参数一是新加入case的坐标,参数二是需要匹配距离最近的周边点的个数n,这里赢指定单数
4、距离计算,使用欧式距离
新加入case的坐标与每一个已有坐标计算,这里还有优化空间,以后更新
计算好的距离与key做成新的key-value
依据距离排序
取前n个case
5、取得key
对前n个case的key进行统计
取统计量结果最多的key即是新加入case所对应的分组
6、将新加入的values与分组写成key-value加入已有的key-value列队
输入新的case坐标,返回第一步......递归
''' import operator def create_case_list():
# 1代表黄瓜,2代表香蕉,3代表茄子,4代表西葫芦
case_list = [[25,3,73732],[27.5,8,127492],[13,6,127492],[16,13,50331049],[17,4,18874516],[22,8,13762774],[14,1,30473482],[18,3,38338108]]
case_type = [1,1,2,2,3,3,4,4]
return case_list,case_type def knn_fun(user_coord,case_coord_list,case_type,take_num):
case_len = len(case_coord_list)
coord_len = len(user_coord)
eu_distance = []
for coord in case_coord_list:
coord_range = [(user_coord[i] - coord[i]) ** 2 for i in range(coord_len)]
coord_range = sum(coord_range) ** 0.5
eu_distance.append(coord_range)
merage_distance_and_type = zip(eu_distance,case_type)
merage_distance_and_type.sort()
type_list = [merage_distance_and_type[i][1] for i in range(take_num)]
class_count = {}
for type_case in type_list:
type_temp = {type_case:1}
if class_count.get(type_case) == None:
class_count.update(type_temp)
else: class_count[type_case] += 1
sorted_class_count = sorted(class_count.iteritems(), key = operator.itemgetter(1), reverse = True)
return sorted_class_count[0][0] def auto_norm(case_list):
case_len = len(case_list[0])
min_vals = [0] * case_len
max_vals = [0] * case_len
ranges = [0] * case_len
for i in range(case_len):
min_list = [case[i] for case in case_list]
min_vals[i] = min(min_list)
max_vals[i] = max([case[i] for case in case_list])
ranges[i] = max_vals[i] - min_vals[i]
norm_data_list = []
for case in case_list:
norm_data_list.append([(case[i] - min_vals[i])/ranges[i] for i in range(case_len)])
return norm_data_list,ranges,min_vals def main():
result_list = ['黄瓜','香蕉','茄子','西葫芦']
dimension1 = float(input('长度是: '))
dimension2 = float(input('弯曲度是: '))
dimension3 = float(input('颜色是: '))
case_list,type_list = create_case_list()
#norm_data_list,ranges,min_vals = auto_norm(case_list)
in_coord = [dimension1,dimension2,dimension3]
#in_coord_len = len(in_coord)
#in_coord = [in_coord[i]/ranges[i] for i in range(in_coord_len)]
#class_sel_result = knn_fun(in_coord,norm_data_list,type_list,3)
class_sel_result = knn_fun(in_coord,case_list,type_list,3)
class_sel_result = class_sel_result - 1
return result_list[class_sel_result] if __name__ == '__main__':
a = main()
print '这货是: %s' %a
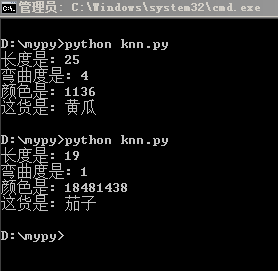
测试结果,效果还不赖
机器学习算法_knn(福利)的更多相关文章
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- 【R】如何确定最适合数据集的机器学习算法 - 雪晴数据网
[R]如何确定最适合数据集的机器学习算法 [R]如何确定最适合数据集的机器学习算法 抽查(Spot checking)机器学习算法是指如何找出最适合于给定数据集的算法模型.本文中我将介绍八 ...
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- paper 19 :机器学习算法(简介)
本来看了一天的分类器方面的代码,乱乱的,索性再把最基础的概念拿过来,现总结一下机器学习的算法吧! 1.机器学习算法简述 按照不同的分类标准,可以把机器学习的算法做不同的分类. 1.1 从机器学习问题角 ...
- paper 17 : 机器学习算法思想简单梳理
前言: 本文总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想. 朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- Computer Science Theory for the Information Age-4: 一些机器学习算法的简介
一些机器学习算法的简介 本节开始,介绍<Computer Science Theory for the Information Age>一书中第六章(这里先暂时跳过第三章),主要涉及学习以 ...
随机推荐
- linux中sed命令的使用
sed命令是linux或者shell编程中常用的筛选.替换命令,如果能熟练使用sed则对经常使用的人来说在工作上是非常有帮助的 下面把sed主要的用法列出来(有错误的地方大家可以指正): p命令只打印 ...
- Python -- queue队列模块
一 简单使用 --内置模块哦 import Queuemyqueue = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现.队列长度可为无限或者有限. ...
- rest规范是什么?
请参考这篇文章,每一个回答者侧重点不同,但都十分精彩 https://www.zhihu.com/question/28557115
- 带分页功能的SSH整合,DAO层经典封装
任何一个封装讲究的是,使用,多状态.Action: 任何一个Action继承分页有关参数类PageManage,自然考虑的到分页效果,我们必须定义下几个分页的参数.并根据这个参数进行查值. 然 ...
- 分布式锁之redisson
redisson是redis官网推荐的java语言实现分布式锁的项目.当然,redisson远不止分布式锁,还包括其他一些分布式结构.详情请移步:https://github.com/mrniko/r ...
- [深度学习]CNN--卷积神经网络中用1*1 卷积有什么作用
1*1卷积过滤器 和正常的过滤器一样,唯一不同的是它的大小是1*1,没有考虑在前一层局部信息之间的关系.最早出现在 Network In Network的论文中 ,使用1*1卷积是想加深加宽网络结构 ...
- 史上最详细nodejs版本管理器nvm的安装与使用(附注意事项和优化方案)
使用场景 在Node版本快速更新迭代的今天,新老项目使用的node版本号可能已经不相同了,node版本更新越来越快,项目越做越多,node切换版本号的需求越来越迫切,传统卸载一个版本在安装另一个版本的 ...
- 开发php的扩展模块(centos环境下)
首先下载一份PHP的源码,并上传到centos服务器上 源码下载地址:https://github.com/php/php-src 然后在命令行进入到源码路径下的ext目录 然后创建扩展项目 [r ...
- [JZOJ5987] 仙人掌毒题
Description Solution 套路题... 全他娘的是套路... 首先如何处理仙人掌,可以在线拿 \(lct\) 维护,或者离线之后树剖.(\(lct\) 维护太毒了写不来,就离线树剖了又 ...
- sql特殊语法
MYSQL --判断非空select ifnull(null,'666');--666select ifnull(null,null);--null--合并字段select CONCAT('666', ...