hadoop备战:yarn框架的搭建(mapreduce2)
昨天没有写好了没有更新,今天一起更新,yarn框架也是刚搭建好的。
我这里把hadoop放在了我的个人用户hadoop下了,你也能够尝试把它放在/usr/local,考虑的问题就相对多点。
主要的软硬件配置:
x86台式机。window7 64位系统
wmware虚拟机(x86的台式机至少是4G内存。才干开2台虚机)
centos6.4操作系统
hadoop-2.2.0.tar.gz
jdk-6u24-linux-i586.bin
WinScp 远程文件传输工具,非常好用。能够用于windows和虚拟机Linux之间文件相互拷贝。
一、root下的配置
a) 改动主机名:vi /etc/sysconfig/network
Master, slave1,b) 解析Ip: vi /etc/hosts
由于採用的是Host-only连接网络,主机上Vmnet1的ip:192.168.137.1
192.168.137.50 master192.168.137.55 slave1
c) 调试网络:
採用自定的vmnet1,默认是host-only这样的方式,连接网络,配置网络。
改动后记得调用 service network restart
确保三台虚拟机能够相互ping通。
(非常好弄的,我如今的问题怎样让虚拟机连接外网,我会在近期的博客中,弄清楚,继续关注我的博客)
d) 关闭防火墙
查看:service iptables status
关闭:service iptables stop
查看防火墙有无自启动:
Chkconfig –-list | grep iptables
关闭自启动:
Chkconfig iptables off
二、hadoop用户下的配置
a) 创建用户hadoop,设置password,进入用户
useradd hadoop
passwd hadoop
b) master创建公私秘钥
分别在两台虚拟机上生成:ssh-keygen –t rsa.
.ssh是一个隐藏的文件 #cd .ssh可进入
1)将id_rsa.pub复制给authorized_keys
Cp id_rsa.pub authorized_keys
2)将master中的authorized_keys复制给slave1的/home/hadoop/.ssh下
scp authorized_keys root@192.168.137.55:/home/hadoop/.ssh/
3)将master拷贝过来的authorized_keys拷贝到slave1本身所创的authorized_keys下
4)验证ssh的免password生效:
a)能够尝试发个小文件给对方机器,假设没有提示要求password,那么你的免password就生效了。
b)也能够直接ssh+对方机器名(hostname改过之后),能够进入对方用户环境则说明生效。
c) 将hadoop拷贝拷贝到相应的master机子中/home/hadoop/
配置hadoop用户的环境变量 vi /etc/profile,加入例如以下内容:
#set java enviroment
export JAVA_HOME=/usr/local/jdk
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
# Hadoop
export HADOOP_PREFIX="/home/hadoop/hadoop"
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
注:su + username实现切换用户。
d) 编辑/home/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
e) 编辑/home/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/local/jdk
f) 编辑/home/hadoop/etc/hadoop/core-site.xml
<!-- 新变量f:s.defaultFS 取代旧的:fs.default.name -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 注意创建相关的文件夹结构,这里的tmp是自己创建的 -->
<value>/home/hadoop/hadoop/tmp</value>
</property>
g) 编辑/home/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<!-- 值须要与实际的DataNode节点数要一致,本文为3 -->
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- 注意创建相关的文件夹结构 -->
<value>file:/home/hadoop/hadoop/dfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- 注意创建相关的文件夹结构 -->
<value>file:/home/hadoop/hadoop/dfs/datanode</value>
</property>
h) 编辑/home/hadoop/hadoop/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- resourcemanager hostname或ip地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
h) 编辑/home/hadoop/hadoop/etc/hadoop/mapred-site.xml
注:默认没有mapred-site.xml文件,copy mapred-site.xml.template 一份为 mapred-site.xml就可以
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
三、启动和測试
1、启动Hadoop
1.1、第一次启动须要在Master.Hadoop 运行format : hdfs namenode -format :
格式化成功,你能找到一句话:

1.2、在Master.Hadoop运行 start-dfs.sh :
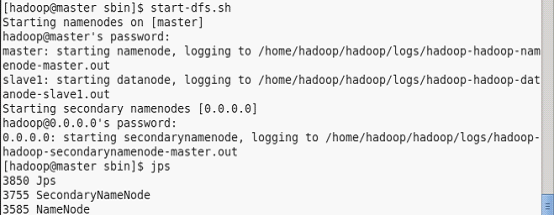
验证启动进程例如以下:
1.3、在Master运行 start-yarn.sh :

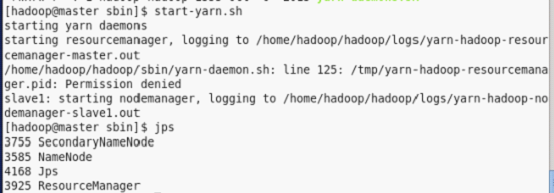
验证启动进程例如以下:
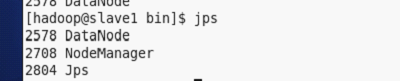
四、演示案例:(单词计数)
1)先实现以下的生成文件夹命令:

)本地创建三个文件 micmiu-01.txt、micmiu-03.txt、micmiu-03.txt, 分别写入例如以下内容:
micmiu-01.txt:
Hi Michael welcome to Hadoop
more see micmiu.com
micmiu-02.txt:
Hi Michael welcome to BigData
more see micmiu.com
micmiu-03.txt:
Hi Michael welcome to Spark
more see micmiu.com
3)然后cd 切换到Hadoop的share/hadoop/mapreduce下运行
[hadoop@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount /user/micmiu/wordcount/in /user/micmiu/wordcount/out
ps: hdfs 中 /user/micmiu/wordcount/out 文件夹不能存在 否则运行报错。
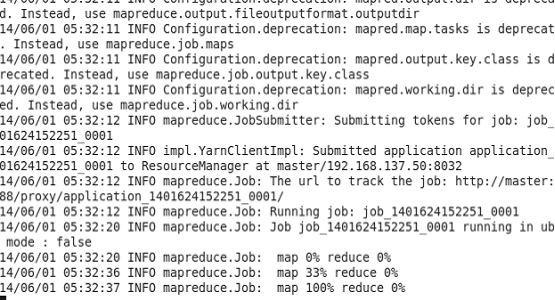
5)到此 wordcount的job已经运行完毕,运行例如以下命令能够查看刚才job的运行结果:
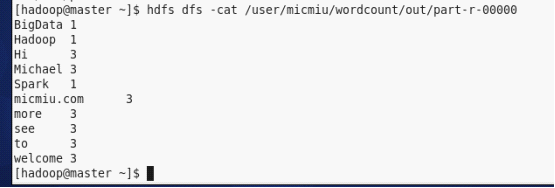
hadoop的童鞋们,有问题加关注,评价中说明问题。
hadoop备战:yarn框架的搭建(mapreduce2)的更多相关文章
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
- Hadoop MapReduceV2(Yarn) 框架简介
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ 对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详 ...
- hadoop备战:yarn框架的简单介绍(mapreduce2)
新 Hadoop Yarn 框架原理及运作机制 重构根本的思想是将 JobTracker 两个基本的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控.新的资源管理器全局管理全部应用程序计 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- Hadoop学习之YARN框架
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/,非常感谢分享! 对于业界的大数据存储及分布式处理系统来说,H ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Hadoop Yarn框架详细解析
在说Hadoop Yarn之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTracker ...
- hadoop之yarn详解(框架进阶篇)
前面在hadoop之yarn详解(基础架构篇)这篇文章提到了yarn的重要组件有ResourceManager,NodeManager,ApplicationMaster等,以及yarn调度作业的运行 ...
随机推荐
- 当堆遇到STL 代码焕发光芒
来自度娘的释义,堆的含义大概是这样的: 感性理解: 堆(英语:heap)是计算机科学中一类特殊的数据结构的统称.堆通常是一个可以被看做一棵树的数组对象.堆总是满足下列性质: 堆中某个节点的值总是不大于 ...
- CSS学习笔记04 CSS文字排版常用属性
字体样式属性 font-size:字号大小 font-size属性用于设置字号,该属性的值可以使用相对长度单位,也可以使用绝对长度单位.其中,相对长度单位比较常用,推荐使用像素单位px,绝对长度单位使 ...
- vue 教程
1.安装 nodejs,检测 nodejs 环境(node -v). 2.安装vue-cli脚手架npm install vue-cli -g 3.在电脑的某个盘中创建项目,之后进入该项目. 4.初始 ...
- Redraw Beautiful Drawings(hdu4888)网络流+最大流
Redraw Beautiful Drawings Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/O ...
- Java基础知识你知道多少?
Java虚拟机基础知识你知道多少? Java并发基础知识你知道多少? Java数据结构基础知识你知道多少? java序列化与反序列化 https://github.com/zhantong/inter ...
- 如何在SpringMVC中使用REST风格的url
如何在SpringMVC中使用REST风格的url 1.url写法: get:/restUrl/{id} post:/restUrl delete:/restUrl/{id} put:/restUrl ...
- jdk源码->并发->Unsafe&Atomic
synchronized关键字类似于java中的悲观锁机制,接下来介绍一种java的乐观锁机制Unsafe类 CAS CAS简介 CAS全称是Compare And Swap,即比较交换,它是在并发执 ...
- HDU2157(SummerTrainingDay05-F dp)
How many ways?? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)T ...
- 第二十九天- socketserver模块 ftp上传
1.socketserver模块: socketserver,它提供了服务器中心类,可简化网络服务器的开发,内部使用IO多路复用以及“多线程”和“多进程”,从而实现并发处理多个客户端请求的socket ...
- page、request、session和application有什么区别?
转自:http://liuyuru.iteye.com/blog/773367 1.简单说 page指当前页面.在一个jsp页面里有效 2.request 指从http请求到服务器处理结束,返回响应的 ...