flink的watermark机制你学会了吗?
大家好,今天我们来聊一聊flink的Watermark机制。
这也是flink系列的的第一篇文章,如果对flink、大数据感兴趣的小伙伴,记得点个关注呀。
背景
flink作为先进的流水计算引擎,提供了三种时间概念,这对基于时间的流处理应用提供了多种可能。
Event time 指生产设备中每个独立的事件发生的时间,比如用户点击产生的时间。
Process time 指正在执行相关进程的机器的系统时间。
IngestionTime 指事件进入flink的时间。
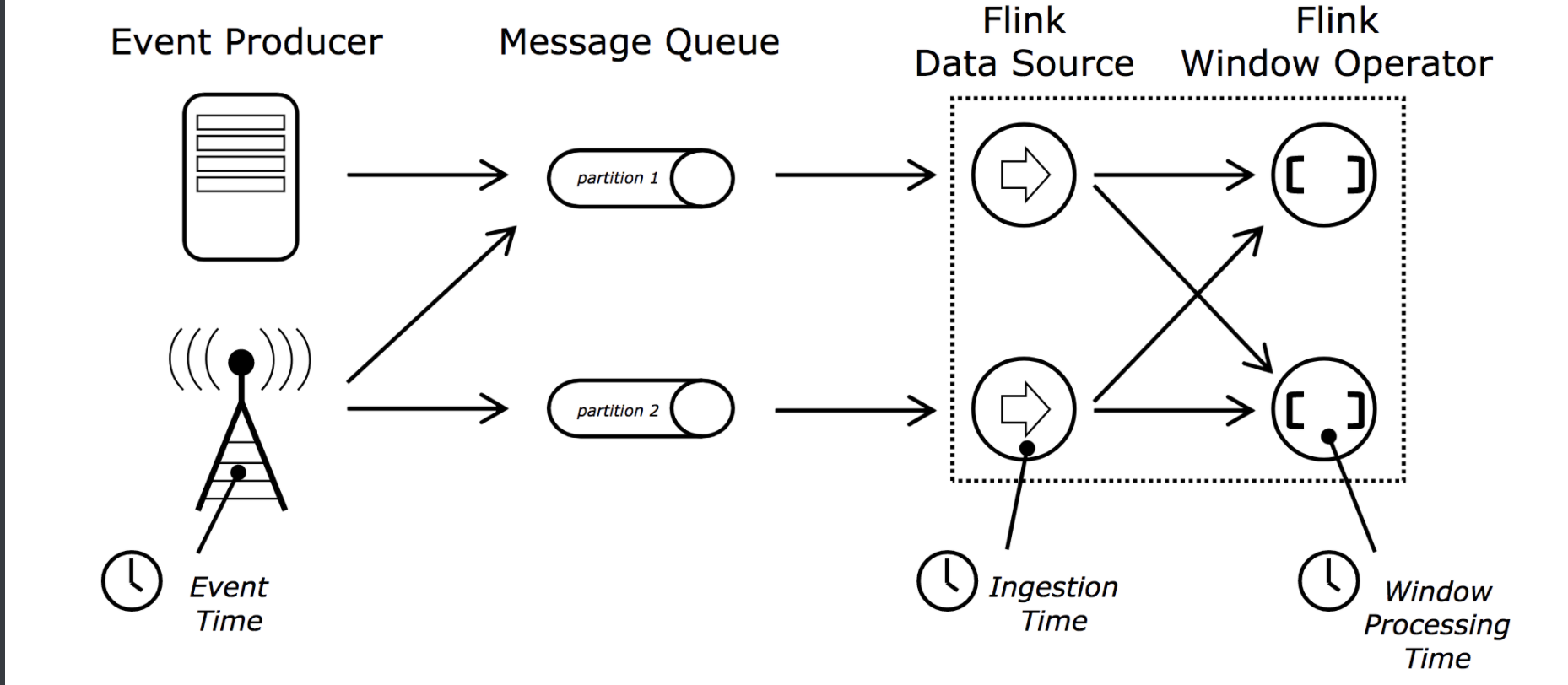
WaterMark机制主要是用来解决EventTime乱序的情况。从事件的产生、到经过消息中间件、然后经过data source和Operator,在传输的过程中,由于网络传输等原因,会导致EventTime出现乱序,如果只是根据EventTime来决定window的运行,我们不能明确数据是否已经全部到位,所以我们需要有一个机制来保证特定的时间后,必须触发window去执行计算了,这个机制就是Watermark。
定义
WaterMark是一种特殊的时间戳,它会被插入到数据流中,用于表示EventTime小于Watermark的事件全部落入到了相应的窗口中。
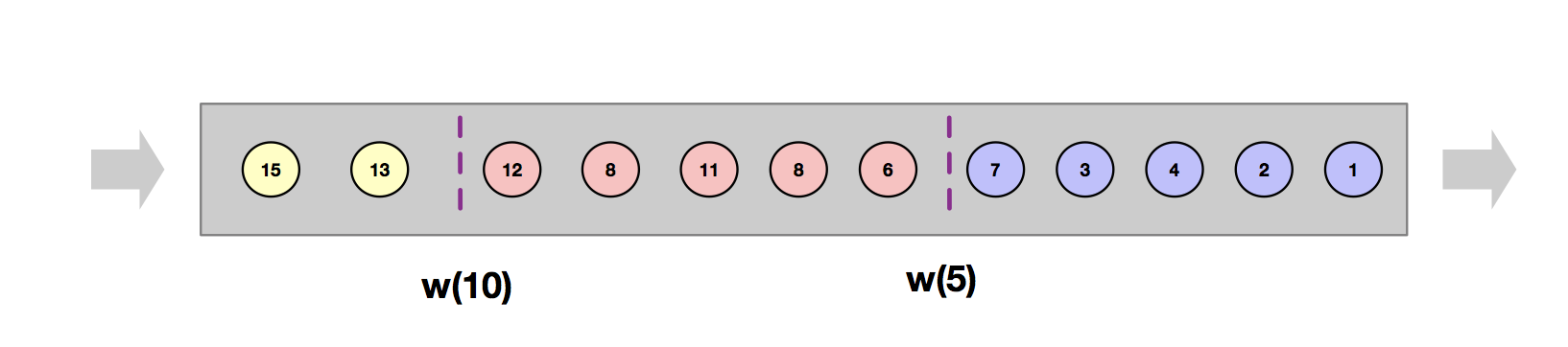
如图所示,这是一个窗口大小为5的乱序流。w(5)表示EventTime小于5的数据已经落入相应的窗口。当Watermark大于等于窗口的最大时间戳(即窗口的endTime),就会触发相应窗口的计算。比如W(5)大于等于5,会触发窗口[0,5)的计算。
生成
WaterMark有两种生成方式,分别是Punctuated Watermark(标点水位线)和Periodic Watermark(周期性水位线)。
标点水位线
标点水位线(Punctuated Watermark)是通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下,窗口的触发与时间无关,而是决定于何时收到标记事件。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
周期性水位线
周期性的(允许一定时间间隔或者达到一定的记录条数)产生一个Watermark。水位线提升的时间间隔是由用户设置的,在两次水位线提升时隔内会有一部分消息流入,用户可以根据这部分数据来计算出新的水位线。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
案例
在实际的项目中,主要是使用周期性的水位线,我们可以通过env.getConfig().setAutoWatermarkInterval()设置,默认是200ms。
public class test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<String> inputStream = env.socketTextStream("localhost", 8888);
SerializableTimestampAssigner<String> timestampAssigner =
new SerializableTimestampAssigner<String>(){
@Override
public long extractTimestamp(String element, long recordTimestamp) {
String[] fields = element.split(" ");
Long aLong = new Long(fields[0]);
return aLong * 1000L;
}
};
SingleOutputStreamOperator<Tuple2<String,Long>> result=inputStream.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(timestampAssigner)
).map(new MapFunction<String, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(String s) {
return Tuple2.of(s.split(" ")[1],1L);
}
}).keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> stringLongTuple2, Tuple2<String, Long> t1) throws Exception {
return new Tuple2<>(stringLongTuple2.f0,stringLongTuple2.f1+t1.f1);
}
});
result.print();
env.execute("warter mark test");
}
}
当通过nc -l 8888输入数据
1630312530 java
1630312533 java
1630312536 java
1630312540 java
1630312543 java
1630312538 java
1630312545 java
1630312539 java
1630312550 java
1630312549 java
1630312555 java
输出为:
1> (java,5)
1> (java,4)
当事件“1630312545 java”进入流处理后,生成的Watermark为“W(1630312540)”,大于等于窗口[1630312530,1630312540)的endTime,触发窗口的计算,此时延迟数据“1630312538 java”也会被计算在内,所以会输出“(java,5)”,而事件“1630312539 java”是在Watermark已经触发相应的窗口计算后,才进入流处理中,延迟太久,会被忽略掉。当事件“163031255 java”进入流处理后,生成的Wartermark为W(163031250),触发窗口[163031240,163031250)的计算。
最后
到此为止,我们已经把Watermark机制聊完了,如果喜欢,请点个关注吧。
更多有趣知识,请关注公众号【程序员学长】。我给你准备了上百本学习资料,包括python、java、数据结构和算法等。如果需要,请关注公众号【程序员学长】,回复【资料】,即可得。
你知道的越多,你的思维也就越开阔,我们下期再见。

flink的watermark机制你学会了吗?的更多相关文章
- [白话解析] Flink的Watermark机制
[白话解析] Flink的Watermark机制 0x00 摘要 对于Flink来说,Watermark是个很难绕过去的概念.本文将从整体的思路上来说,运用感性直觉的思考来帮大家梳理Watermark ...
- Flink的时间类型和watermark机制
一FlinkTime类型 有3类时间,分别是数据本身的产生时间.进入Flink系统的时间和被处理的时间,在Flink系统中的数据可以有三种时间属性: Event Time 是每条数据在其生产设备上发生 ...
- [源码解析] 从TimeoutException看Flink的心跳机制
[源码解析] 从TimeoutException看Flink的心跳机制 目录 [源码解析] 从TimeoutException看Flink的心跳机制 0x00 摘要 0x01 缘由 0x02 背景概念 ...
- Flink(八)【Flink的窗口机制】
目录 Flink的窗口机制 1.窗口概述 2.窗口分类 基于时间的窗口 滚动窗口(Tumbling Windows) 滑动窗口(Sliding Windows) 会话窗口(Session Window ...
- Flink Runtime核心机制剖析(转)
本文主要介绍 Flink Runtime 的作业执行的核心机制.本文将首先介绍 Flink Runtime 的整体架构以及 Job 的基本执行流程,然后介绍在这个过程,Flink 是怎么进行资源管理. ...
- Apache Flink - 数据流容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态.该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次). 从容错和消息处理的语义上(at leas ...
- Flink Window窗口机制
总览 Window 是flink处理无限流的核心,Windows将流拆分为有限大小的"桶",我们可以在其上应用计算. Flink 认为 Batch 是 Streaming 的一个特 ...
- [Flink] Flink的waterMark的通俗理解
导读 Flink 为实时计算提供了三种时间,即事件时间(event time).摄入时间(ingestion time)和处理时间(processing time). 遇到的问题: 假设在一个5秒的T ...
- Flink – process watermark
WindowOperator.processElement 主要的工作,将当前的element的value加到对应的window中, windowState.setCurrentNamespace(w ...
随机推荐
- FiddlerEverywhere 的配置和基本应用
一.下载大家自行在官网下载即可,这个可以当做是fiddler的升级版本,里面加了postman的功能,个人感觉界面比较清晰简约,比较喜欢. 二.下载完成之后大家可以自行注册登录,主页面的基本使用如下: ...
- 【排序+模拟】谁拿了最多奖学金 luogu-1051
题目描述 某校的惯例是在每学期的期末考试之后发放奖学金.发放的奖学金共有五种,获取的条件各自不同: 院士奖学金,每人$ 8000 $元,期末平均成绩高于\(80\)分(\(>80\)),并且在本 ...
- Linux系统进入redis并查询值
1.进入redisredis-cli -h ip -p port2.查看具体信息info 3.得到redis中存储的所有key值KEYS *4.获取指定key值的value值get "key ...
- anyRTC视频连麦demo上线啦!
音频连麦demo一经问世就得到开发者的一致好评,有很多开发者咨询视频连麦的demo该怎么去实现,本着让"视频交付更简单"的理念,我们推出了视频连麦demo! 音视频技术不仅局限用于 ...
- JIT in MegEngine
作者:王彪 | 旷视框架部异构计算组工程师 一.背景 什么是天元 旷视天元(MegEngine)是一个深度学习框架,它主要包含训练和推理两方面内容.训练侧一般使用 Python 搭建网络:而推理侧考虑 ...
- AndroidStudio 插件总结
工作中常用的插件备注如下: Alibaba Java Coding GuidelinesCheckStyle-IDEAAndroid Drawable PreviewGsonFormatTransla ...
- 强烈IDEA这些插件,让你的开发速度飞起来!
大家好,我是大彬~ 俗话说:工欲善其事必先利其器.今天给大家介绍几款我自己经常用的 IDEA 插件,很强大,助力大家开发. 插件安装 以IDEA为例,进入settings->Plugins-&g ...
- 《手把手教你》系列技巧篇(十七)-java+ selenium自动化测试-元素定位大法之By css上卷(详细教程)
1.简介 CSS定位方式和xpath定位方式基本相同,只是CSS定位表达式有其自己的格式.CSS定位方式拥有比xpath定位速度快,且比CSS稳定的特性.下面详细介绍CSS定位方式的使用方法.xpat ...
- 4、关于numpy.random.seed()的使用说明
定义:seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差 ...
- MySQL慢查询及开启慢查询
一.简介 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能. 二.参数说明 slow_query_log 慢查询开启状态 slow_ ...