[MySQL数据库之记录的详细操作:增、改、删、单表查询、多表查询]
[MySQL数据库之记录的详细操作:增、改、删、单表查询、多表查询]
记录详细操作
增、删、改
增:
insert t1(字段1,字段2,字段3) values
(值1,值2,值3),
(值1,值2,值3),
(值1,值2,值3);
改:
update t1 set
字段1 = 值1,
字段2 = 值2,
where 条件;
删:
delete from 表 where 条件;
truncate 表; -- 清空表用它
查:单表查询
单表查询语法
select distinct 字段1,字段2,字段3 from 库.表
where 条件
group by 分组字段
having 条件
order by 排序字段
limit 限制条数
关键字的执行优先级
重点中的重点:
from
where
group by
having
select
distinct
order by
limit
1.找到表:from 2.拿着where指定的约束条件,去文件/表中取出一条条记录 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 4.将分组的结果进行having过滤 5.执行select 6.去重 7.将结果按条件排序:order by 8.限制结果的显示条数
SQL逻辑查询语句执行顺序参考博客: https://www.cnblogs.com/linhaifeng/articles/7372774.html
1、简单查询
准备表和记录
简单查询:
# 查看employee表所有的字段
SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id
FROM employee;
select * from employee; -- *代表所有字段
# 查看employee表name,post的字段(名字和岗位)
select name,post from employee;
# 查看employee表去重后的post的字段。distinct对记录去重
select distinct post from employee;
# 查看employee表name,salary的字段(名字和薪资)
select name,salary from employee;
# 查看employee表name和salary*12。as对字段取别名(名字和年薪)
select name as 名字,salary*12 as annual_salary from employee;
# concat()函数:对字符串进行拼接
select concat("名字",":",name) as new_name,concat("薪资",":",salary) as new_salary from employee;
# concat_ws() 第一个参数为分隔符
select concat_ws(":",name,post,salary) from employee;
# 结合CASE语句:case就是一种多分枝的if判断(了解)
SELECT
(
CASE
WHEN NAME = 'egon' THEN
NAME
WHEN NAME = 'alex' THEN
CONCAT(name,'_BIGSB')
ELSE
concat(NAME, 'SB')
END
) as new_name
FROM
employee;
2、关键字where约束
拿着where指定的约束条件,去文件/表中取出一条条记录
注意:没有where条件相当于所有条件永远都为真
where字句中可以使用: 1. 比较运算符:> < >= <= != 2. between 80 and 100 值在10到20之间 3. in(80,90,100) 值是10或20或30 4. like 'egon%'
pattern可以是%或_,
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
wheret条件筛选:
# 查看employee表id大于等于10的字段
select * from employee where id >= 10;
# 查看employee表id大于等于10和小于等于13的字段
select * from employee where id >= 10 and id <= 13;
select * from employee where id between 10 and 13;
# 查看employee表id等于10或id等于13或id等于15的字段
select * from employee where id = 10 or id = 13 or id = 15;
select * from employee where id in (10,13,15);
# 查看employee表post_comment是空的字段(ps:空字符串不代表空)
select * from employee where post_comment is null;
# 关键字LIKE模糊查询
# 查看employee表name是ji开头的字段
select * from employee where name like "ji%";
# 查看employee表name是ji开头且为三个字符的字段
select * from employee where name like "ji_"; -- 报错,没有该字段
3、关键字group by分组
group by分组字段与聚合函数
group by就是对where条件筛选出来的一条条记录进行分组,分组后可以以组为单位进行统计
下面五个函数叫聚合函数:
max 最大值
min 最小值
avg 平均值
sum 求和
count 统计个数
在分完组之后,可以以组为单位统一出一个结果,也就是说一个组出一个结果
只要分组你想要的拿到的一定是聚合结果。但凡分组你的需求就不再是取某一条记录,而是通过分组拿到什么结果,并不是追求某一条记录长什么样
# 查看employee表每个部门的最大薪资,按岗位分组(将所有记录分为4个组)
select post,max(salary) from employee group by post;
# 查看employee表每个部门的最小薪资
select post,min(salary) from employee group by post;
# 查看employee表每个部门的平均薪资
select post,avg(salary) from employee group by post;
# 查看employee表每个部门的薪资总和
select post,sum(salary) from employee group by post;
# 查看employee表每个部门有多少名员工
select post,count(id) from employee group by post;
# 查看employee表有多少名男性,多少名女性
select sex,count(id) from employee group by sex;
# 查看每个部门男员工的平均薪资
select post,avg(salary) from employee where sex = "male" group by post;
# 查看每个部门年龄小于20岁的员工的平均薪资
select post,avg(salary) from employee where age > 20 group by post;
了解知识点:
select * from employee group by post; -- 查看只能取到每个组的第一条记录
# 设置或者在sql严格模式下:查看取值只能取分组字段
set sql_mode="only_full_group_by";
select * from employee group by post; --报错
# 对于group by聚合操作,如果在select中的列没有在group by中出现,那么这个SQL是不合法的,因为列不在
# group by从句中,所以设置了sql_mode=only_full_group_by的数据库,在使用group by时就会报错。
注:不在该模式下即使取到值也只能取到每个组的第一条记录,这样毫无意义,这是由于sql默认宽松模式的影响,
所以分组完之后应该取的是分组字段以及聚合结果。无论在什么sql模式下,这条sql语句肯定不会报错,并且这条
sql语句符合以后的查询需求的。
4、关键字having过滤
在分组之后将分组的结果进行having过滤
===》where与having不一样的地方! ! !
!!!执行优先级从高到低:where > group by > having 1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
# 查看男员工的平均薪资大于10000的部门
select post,avg(salary) from employee
where sex = "male" group by post having avg(salary)>10000;
# 查看所有人的最高薪资(是在分组之后运行的聚合函数)
select max(salary) from employee;
根据sql语句关键字的执行优先级:先运行from》》没有where条件相当于条件永远为真
》》没有group by相当于整体为一组》》没有having过滤条件相当于永远为真》》再运
行聚合函数相当于把所有记录当成一个大组
5、关键字order by排序
将结果按条件排序
按单列排序
# 查看employee表所有人按薪资升序排序
select * from employee order by salary; --默认升序排序
select * from employee order by salary asc;
# 查看employee表所有人按薪资降序排序
select * from employee order by salary desc;
# 查看按多列排序:先按照age升序排序,如果年纪相同,则按照薪资降序排序
select * from employee order by age asc,salary desc;
# 查看按多列排序:先按照age升序排序,如果年纪相同,则按照id降序排序
select * from employee order by age asc,id desc;
# 查看男员工的平均薪资大于10000的部门,并且按照平均薪资降序排序
select post,avg(salary) from employee
where sex = "male" group by post having avg(salary)>10000
order by avg(salary) desc;
6、关键字limit限制
限制结果的显示条数
# 对所有记录显示前3条(默认初始位置为0)
select * from employee limit 3;
# 从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
select * from employee limit 0,5;
# 从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
select * from employee limit 5,5;
# 从第10开始,即先查询出第11条,然后包含这一条在内往后查5条
select * from employee limit 10,5;
7、使用正则表达式查询regexp
# 查看employee表名字以ale开头的字段
select * from employee where name regexp '^ale';
# 查看employee表名字以on结尾的字段
select * from employee where name regexp 'on$';
小结:对字符串匹配的方式
where name = 'egon';
where name like 'yua%';
where name regexp 'on$';
多表查询
准备表department与employee
department部门表:有id、名字
employee员工表:有id、名字、性别、年龄、部门id
多表连接查询
多表连接关键字:
inner join 内连接
left join 左连接
right join 右连接 重点:外链接语法
select 字段列表
from 表1 inner|left|right join 表2
on 表1.字段 = 表2.字段;
# on表示连接条件: 条件字段就是代表相同的记录含义
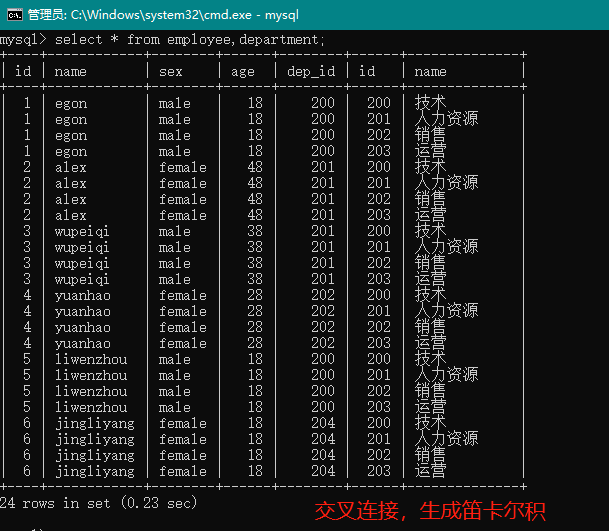
交叉连接
交叉连接:不适用任何匹配条件。生成笛卡尔积
select * from employee,department;
内连接:inner join
内连接:inner join,只保留有对应关系的记录
# 找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果
select * from employee,department where employee.dep_id = department.id;
# 虽然结果跟上面一样但以后连表用这种方法,专门的语法干专门的事,on表示连接条件
select * from employee inner join department on employee.dep_id = department.id;

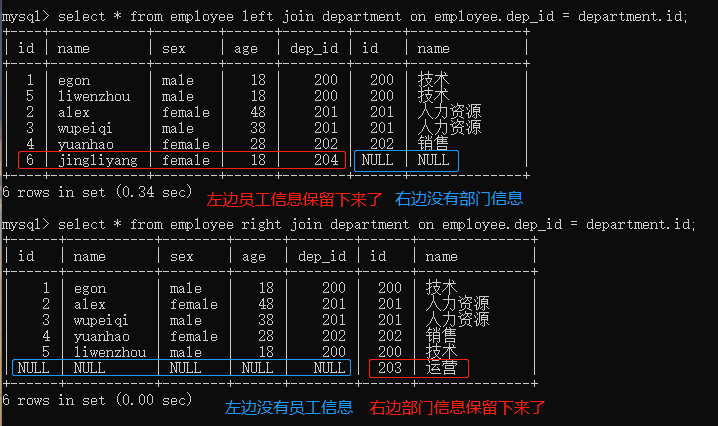
外链接之左连接:left join
外链接之左连接:left join,在内连接的基础上保留左表的记录
# 以左表为准,即找出所有员工信息,当然包括没有部门的员工
# 在内连接的基础上保留左边有右边没有的记录(保留左表多余的记录)
select * from employee left join department on employee.dep_id = department.id;
外链接之右连接:right join
外链接之右连接:right join,在内连接的基础上保留右表的记录
# 以右表为准,即找出所有部门信息,包括没有员工的部门
# 在内连接的基础上保留右边有左边没有的记录(保留右表多余的记录)
select * from employee right join department on employee.dep_id = department.id;
全外连接:full join
全外连接:full join,在内连接的基础上,保留左右两表没有对应关系的记录
# MySQL不支持全外连接full join这个关键字
# 强调:mysql可以使用此种方式间接实现全外连接(拿到左连接和右连接)
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id;
# 注意:union会去掉相同的纪录
union 操作符用于合并两个或多个 select 语句的结果集。
注释:默认地,union 操作符选取不同的值。如果允许重复的值,请使用 union allL。
示例:找出每个部门名对应的平均年龄
select department.name,avg(age) from employee inner join department
on employee.dep_id = department.id group by department.name;
+--------------+----------+
| name | avg(age) |
+--------------+----------+
| 人力资源 | 43.0000 |
| 技术 | 18.0000 |
| 销售 | 28.0000 |
+--------------+----------+
# 这个示例说明:在连表之后完全可以把它当做一张表来用,这时就能用单表查询的语法来操作了

子查询
1:子查询是将一个查询语句嵌套在另一个查询语句中。
2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3:子查询中可以包含:in、not in、any、all、exists 和 not exists等关键字
4:还可以包含比较运算符:= 、!=、> 、<、>=、<=
子查询就是把一个查询语句的结果用括号括起来当做另一个查询语句的条件去用
select * from employee where dep_id =(select id from department where name="技术");
1、带in关键字的子查询
# 查看平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
# 查看技术和销售部门里面的员工(结果集:技术和销售部门的id)
select * from employee where dep_id in
(select id from department where name="技术" or name ="销售");
# not in 取反
select * from employee where dep_id not in
(select id from department where name="技术" or name ="销售");

2、带any关键字的子查询
# any:任何一个
# 在 SQL 中any 和 some是同义词,some的用法和功能和 any一模一样。
# any 和 in 运算符不同之处
1.any 必须和其他的比较运算符共同使用,而且any必须将比较运算符放在any关键字之前,
所比较的值需要匹配子查询中的任意一个值,这也就是any在英文中所表示的意义
例如:使用in和使用any运算符得到的结果是一致的
select * from employee where salary = any (
select max(salary) from employee group by depart_id);
select * from employee where salary in (
select max(salary) from employee group by depart_id);
结论:也就是说“= any”等价于in运算符
# 查看比任何一个部门员工平均年龄都大的员工(结果集:每个部门员工的平均年龄)
select * from employee where age > any(
select avg(age) from employee group by dep_id);
# 查看比任意一个部门员工平均年龄小的员工(结果集:每个部门员工的平均年龄)
select * from employee where age < any(
select avg(age) from employee group by dep_id);
注:小于any,小于任何一个都可以,只要比一个小就行,只要不是最大值就成立

3、带all关键字的子查询
# all:所有
# all同any类似,只不过all表示的是所有,any表示任一
# 查看比所有部门员工平均年龄都大的员工(结果集:每个部门员工的平均年龄)
select * from employee where age > all(
select avg(age) from employee group by dep_id);
# 查看比所有部门员工平均年龄都小的员工(结果集:每个部门员工的平均年龄)
select * from employee where age < all(
select avg(age) from employee group by dep_id);
# 此表里面没有比平均年龄都小的员工

4、带exists关键字的子查询
# exists关字键字表示存在
# 查看有员工的部门
select * from department
where exists (
select * from employee where employee.dep_id = department.id);
使用exists运算符来查看员工表里是否存在符合这个条件的行
所以当MySQL执行这段查询的时候对于部门表里的每一位员工它都会
检查是否存在一条符合这个条件的记录
当使用exists运算符,子查询并没有给外查询返回一个结果,它会返回一个指令
说明这个子查询中是否有符合这个搜索条件的行,员工表里没有这个id的员工,只要
它找到这个表中有一条匹配这个条件的记录它就会返回True给exists,然后这个exists
运算符就会在最终结果里添加当前记录,也就是当前员工
# 查看没有员工的部门
select * from department
where not exists (
select * from employee where employee.dep_id = department.id);

单表查询参考博客:http://www.cnblogs.com/linhaifeng/articles/7267592.html
[多表查询参考博客:http://www.cnblogs.com/linhaifeng/articles/7267596.html](
[MySQL数据库之记录的详细操作:增、改、删、单表查询、多表查询]的更多相关文章
- MySql之行记录的详细操作,创建用户以及库表的授权
一 介绍 MySQL数据操作: DML ======================================================== 在MySQL管理软件中,可以通过SQL语句中的 ...
- mysql之行(记录)的详细操作
在Mysql管理软件中, 可以通过sql语句中的dml语言来实现数据的操作, 包括 使用INSERT实现数据的插入 UPDATE实现数据的更新 使用DELETE实现数据的删除 使用SELECT查询数据 ...
- MySQL行(记录)的详细操作一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理
MySQL行(记录)的详细操作 阅读目录 一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理 一 介绍 MySQL数据操作: ...
- day 37 MySQL行(记录)的详细操作
MySQL行(记录)的详细操作 阅读目录 一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理 一 介绍 MySQL数据操 ...
- Mysql基础(四):库、表、记录的详细操作、单表查询
目录 数据库03 /库.表.记录的详细操作.单表查询 1. 库的详细操作 3. 表的详细操作 4. 行(记录)的详细操作 5. 单表查询 数据库03 /库.表.记录的详细操作.单表查询 1. 库的详细 ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- 在Jena框架下基于MySQL数据库实现本体的存取操作
在Jena框架下基于MySQL数据库实现本体的存取操作 转自:http://blog.csdn.net/jtz_mpp/article/details/6224311 最近在做一个基于本体的管理系统. ...
- js 属性增改删操作
js 属性增改删操作,可参看菜鸟教程,这里记录一个小问题:disabled属性 使用setAttribute操作无法 禁用disabled属性,需使用removeAttribute操作,原因是只要有d ...
- XML简单的增改删操作
XML文件的简单增改删,每一个都可以单独拿出来使用. 新创建XML文件,<?xmlversion="1.0"encoding="utf-8"?> & ...
随机推荐
- PTA 将数组中的数逆序存放
7-1 将数组中的数逆序存放 (20 分) 本题要求编写程序,将给定的n个整数存入数组中,将数组中的这n个数逆序存放,再按顺序输出数组中的元素. 输入格式: 输入在第一行中给出一个正整数n(1). ...
- [Azure Devops] 使用 Azure Repos 管理代码
1. 什么是 Azure Repos Azure Repos 是一组版本控制工具,可用于管理代码.无论您的软件项目是大型项目还是小型项目,都应尽快使用版本控制. 版本控制系统是可帮助您跟踪随时间变化对 ...
- Istio 实践 之 Circuit breakers 断路器 (请求熔断)
参考: https://blog.51cto.com/14625168/2499406 https://istio.io/latest/zh/docs/tasks/traffic-management ...
- [Fundamental of Power Electronics]-PART II-9. 控制器设计-9.3 关键项1/(1+T)和T/(1+T)以及闭环传递函数的构建
9.3 关键项\(1/(1+T)\)和\(T/(1+T)\)以及闭环传递函数的构建 从式(9.4)到(9.9)的传递函数可以很容易的由图形代数方法进行构建.假设我们已经分析了反馈系统模块,并且已经画出 ...
- 03_利用pytorch解决线性回归问题
03_利用pytorch解决线性回归问题 目录 一.引言 二.利用torch解决线性回归问题 2.1 定义x和y 2.2 自定制线性回归模型类 2.3 指定gpu或者cpu 2.4 设置参数 2.5 ...
- Java高级【Junit、反射、注解】
1.Junit单元测试 * 测试分类: 1. 黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值. 2. 白盒测试:需要写代码的.关注程序具体的执行流程. * Junit使用 ...
- 2.EL表达式&JSTL标签库常用方法
1.EL表达式 Expression Language表达式语言,主要是代替jsp页面中的表达式脚本在jsp页面中进行数据的输出. 格式为${表达式} EL表达式输出Bean的普通属性.数组属性.Li ...
- SecureCRT 连接Win10内置ubuntu问题及解决办法
1: 输入hostname, username 后连接提示: ubuntu The remote system refused the connection. 因为没有安装或启动 ssh. 使用命令 ...
- prometheus入门介绍及相关组件、原理讲解
1:介绍 Prometheus 是由 SoundCloud 开源监控告警解决方案. prometheus是由谷歌研发的一款开源的监控软件,目前已经被云计算本地基金会托管,是继k8s托管的第二个项目. ...
- (数据科学学习手札118)Python+Dash快速web应用开发——特殊部件篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...