Python 应用爬虫下载QQ音乐
Python应用爬虫下载QQ音乐
目录:
1.简介怎样实现下载QQ音乐的过程;
2.代码
1.下载QQ音乐的过程
首先我们先来到QQ音乐的官网: https://y.qq.com/,在搜索栏上输入一首歌曲的名称;
如我在上输入最美的期待,按回车来到这个画面
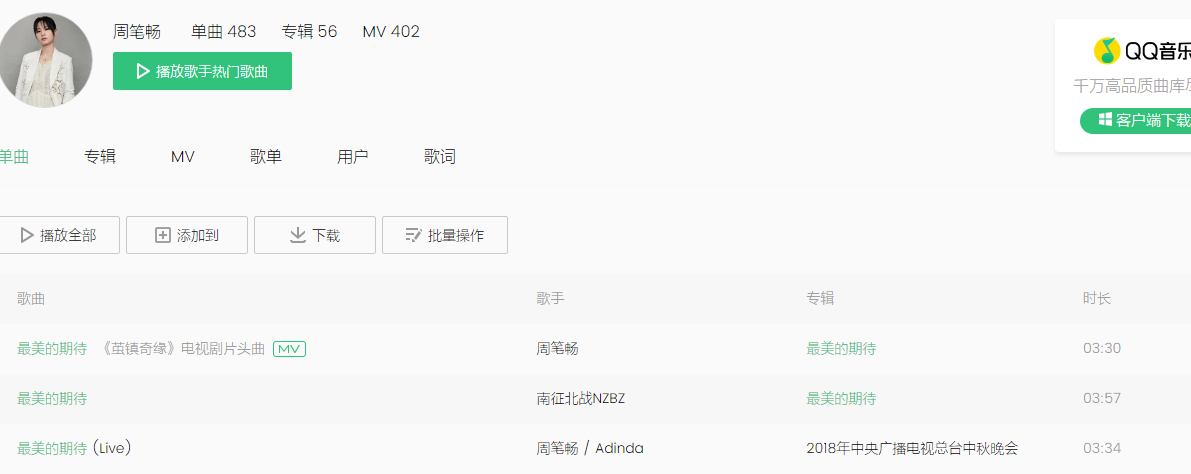
我们首先要得到这些歌曲名称和其他一些信息
鼠标右键查看源代码发现这些数据应该应用了反爬虫
鼠标右键点击检查,点击NetWork,然后点击XHR,按F5刷新,然后点击 https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=66920929169890801&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E6%9C%80%E7%BE%8E%E7%9A%84%E6%9C%9F%E5%BE%85&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0这个网址,如下图:

发现这里好像有我们需要的数据

那么这个网址要怎样才能得到呢!其实也不难发现,就下面的那个w=不同而已,对于不同歌曲。
而这个w=后面的那个数据好像就是我输入的歌曲名,最美的期待,只不过这里对于这个进行了编码罢了。
我们只要这样输入就可以了
from urllib import parse
w=parse.urlencode({'w':input('输入歌名:')})
url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=63229658163010696&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&%s&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'%(w)
print(url)
这样我们就得到了这个url
这样得到的数据是一个字符串,这个字符串类似‘{'key':{'key_1':1}}’,我们可以导入json模块,来处理它,这样我们得到的数据就是一个字典了。
我们点击其中的一首歌试听,来到这个界面
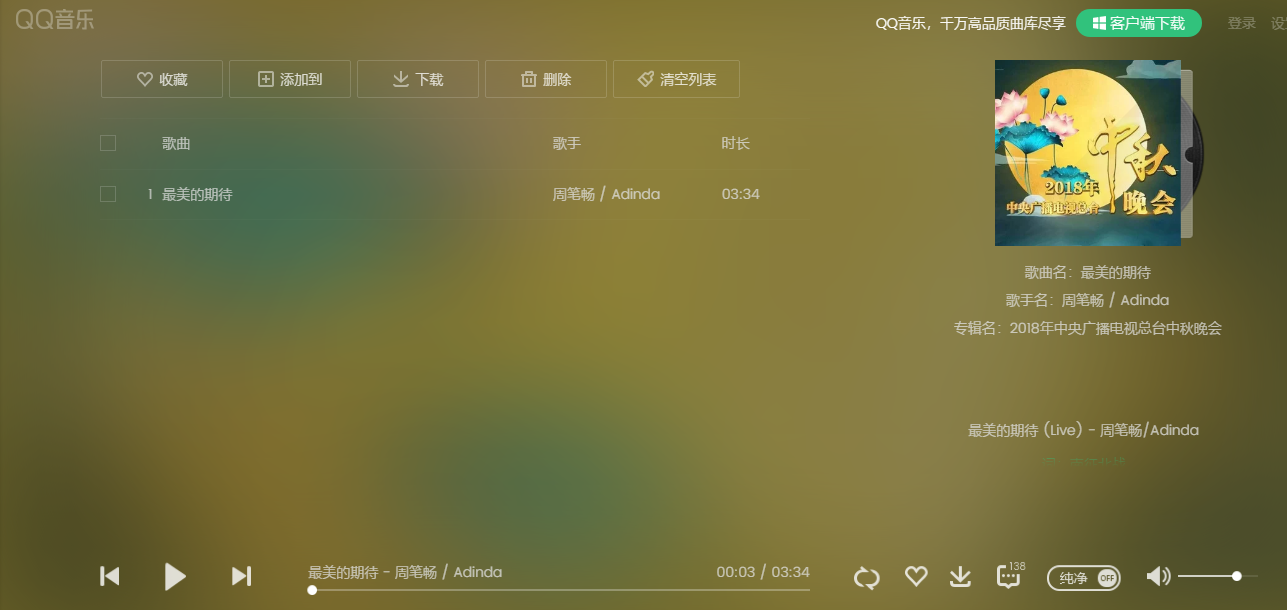
右击鼠标,点击检查,点击NetWork,点击XHR,找到下面这个网址发现
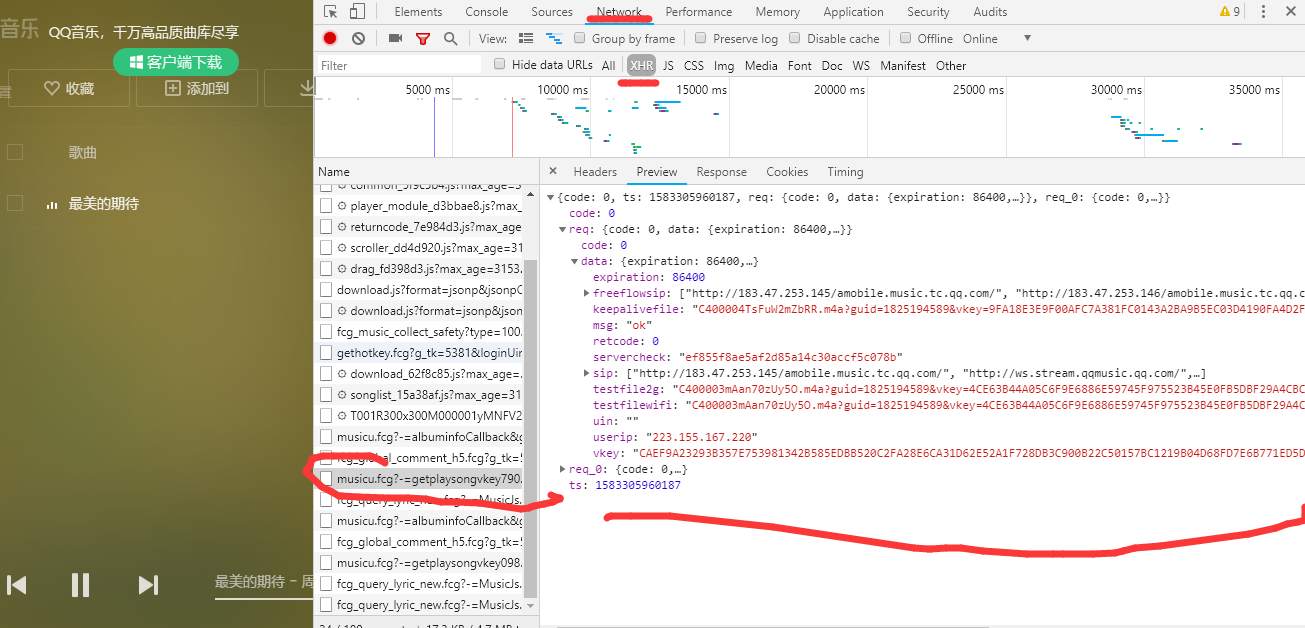
在这里我们可以发现有这首歌曲的下载地址,发现purl下面的一个参数是上面得到的那个数据中的’mid‘,只要将两者结合起来,就可以下载这首歌曲了。
代码如下:
import urllib.parse as parse
from urllib.request import urlretrieve
import requests
import json
import os
import time
import sys def Time_1(): # 进度条函数
for i in range(1,51):
sys.stdout.write('\r')
sys.stdout.write('{0}% |{1}'.format(int(i%51)*2,int(i%51)*'■'))
sys.stdout.flush()
time.sleep(0.125)
sys.stdout.write('\n') print('''
声明:本小程序仅供娱乐和学习,切莫用于商业用途,一经发现,概不负责!
''')
w=parse.urlencode({'w':input('输入歌名:')}) url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=63229658163010696&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&%s&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'%(w) content=requests.get(url=url) str_1=content.text dict_1=json.loads(str_1) song_list=dict_1['data']['song']['list'] str_3='''https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey5559460738919986&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1825194589","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1825194589","songmid":["%s"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}''' url_list=[]
music_name=[] for i in range(len(song_list)):
music_name.append(song_list[i]['name']+'-'+song_list[i]['singer'][0]['name']) print('{}.{}-{}'.format(i+1,song_list[i]['name'],song_list[i]['singer'][0]['name']))
url_list.append(str_3 % (song_list[i]['mid'])) id=int(input('请输入你想下载的音乐序号:')) content_json=requests.get(url=url_list[id-1]) dict_2=json.loads(content_json.text) url_ip=dict_2['req']['data']['freeflowsip'][1] purl=dict_2['req_0']['data']['midurlinfo'][0]['purl'] downlad=url_ip+purl try:
os.mkdir('./QQ音乐') except:
pass finally:
try:
print('开始下载...')
urlretrieve(url=downlad,filename='./QQ音乐/{}.mp3'.format(music_name[id-1]))
Time_1()
print('{}.mp3下载完成!'.format(music_name[id-1]))
except Exception as e:
print(e,'对不起,你没有该歌曲的版权!')
运行结果:
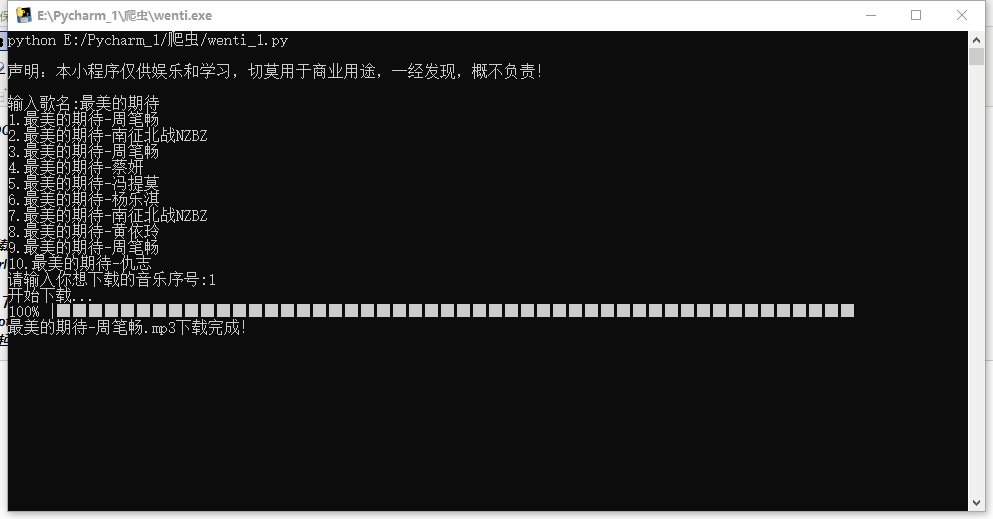
下载完成后,会在同一个文件下面多了一个QQ音乐的文件夹,所下载的歌曲就在这里面。
Python 应用爬虫下载QQ音乐的更多相关文章
- 爬虫下载QQ音乐:获取所有歌手-每个歌手的专辑-每个专辑里的歌曲
# coding=utf-8 # !/usr/bin/env python ''' author: dangxusheng desc : 稍微有点难度,需要多次请求获取key date : 2018- ...
- 亲测可用!免费下载QQ音乐大部分资源!
优化后亲测可用!免费下载QQ音乐大部分资源 通知 时间问题 博客园这边暂时停更要下载的去GitHub或者90盘 GitHub项目地址 https://github.com/TotoWang-hhh/m ...
- go 下载qq音乐
//go下载qq音乐 package main import ( _ "fmt" jsoniter "github.com/json-iterator/go" ...
- Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐 首先我们需要进入到这个界面 想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息. 这个时候我们就应该换一种思 ...
- Python采集VIP收费QQ音乐,一起来听周董最新的《说好不哭》,省3块不香吗?
环境: windows python3.6.5 模块: requests selenium json re urllib 环境与模块介绍完毕后,就可以来实行我们的操作了. 第1步: 通过一个解析网站: ...
- python 站点爬虫 下载在线盗墓笔记小说到本地的脚本
近期闲着没事想看小说,找到一个全是南派三叔的小说的站点,决定都下载下来看看,于是动手,在非常多QQ群里高手的帮助下(本人正則表達式非常烂.程序复杂的正则都是一些高手指导的),花了三四天写了一个脚本 须 ...
- Python网络爬虫 - 下载图片
下载博客园的logo from urllib.request import urlretrieve from urllib.request import urlopen from bs4 import ...
- Appium + Python 测试 QQ 音乐 APP的一段简单脚本
1. 大致流程 + 程序(Python):打开 QQ 音乐,点击一系列接收按键,进入搜索音乐界面,输入『Paradise』,播放第一首音乐. 2. Python 脚本如下 from appium im ...
- JY播放器【QQ音乐破解下载】
今天给大家带来一款神器----JY播放器.可以直接下载QQ音乐的歌曲. 目前已经支持平台(蜻蜓FM.喜马拉雅FM.网易云音乐.QQ音乐) 使用方法: 在网页打开QQ音乐网站找到你要听的歌曲或歌单.复制 ...
随机推荐
- RabbitMq脑裂问题
现象 部署在阿里云上的2台RabbitMQ主从,访问management页面时出现如下所示的内容: 查看其中一个mq的日志,发现如下内容: 00:06:32.423 [warning] <0.5 ...
- linux 中只显示目录的几种方法
ls 参数 -a 表示显示所有文件,包含隐藏文件-d 表示显示目录自身的属性,而不是目录中的内容-F 选项会在显示目录条目时,在目录后加一个/ ls -l total 8 drwxrwxr-x 2 r ...
- (学习心路历程)Vue过渡/动画 VS. 过渡/动画
[此篇为本人的个人见解和哔哔赖赖,如果有观点不对的地方,还请大家指出来哇!!] 最近实习在做一个项目,里面应用的动画效果还蛮复杂的,因为本身对Vue框架比较熟悉,所以最终选择了Vue框架. 自己之前从 ...
- windows下flutter2.2.3环境搭建
先上几个必上的网站: 官网: https://flutter.cn/docs/get-started/install/windows 中文资源网(毕竟中文母语,看着轻松): https://flutt ...
- 【分布式】CAP理论及其应用
CAP Theorem CAP 指的就是 "consistency 一致性","availability 可用性" "partition-tolera ...
- 「CF568C」 New Language
「CF568C」 New Language 一眼 \(\texttt{2-SAT}\) . 然后不会了. 又看了一会儿,然后发现只要我们确定每个位置大于字典序的两种最小的字母是啥,然后按位贪心,这个问 ...
- C++ 标准模板库(STL)——算法(Algorithms)的用法及理解
C++ STL中的算法(Algorithms)作用于容器.它们提供了执行各种操作的方式,包括对容器内容执行初始化.排序.搜索和转换等操作.按照对容器内容的操作可将STL 中的算法大致分为四类: (1) ...
- C语言:总结
1除法运算:两整数相除,结果为整数: 任意浮点数参与的除法运算结果为浮点型.所以pow(16,1/2)=1 pow(16,1.0/2)=4.00 pow(64,1.0/3)=4.00 球的体积v ...
- C语言:虚拟地址 和编译模式
所谓虚拟地址空间,就是程序可以使用的虚拟地址的有效范围.虚拟地址和物理地址的映射关系由操作系统决定,相应地,虚拟地址空间的大小也由操作系统决定,但还会受到编译模式的影响.这节我们先讲解CPU,再讲解编 ...
- Java异常情况
从网上了解了这些Java异常,遇到过一些,大部分还没遇到: 1. SQLException:操作数据库异常类. 2. ClassCastException:数据类型转换异常. 3. NumberFor ...