Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐
首先我们需要进入到这个界面
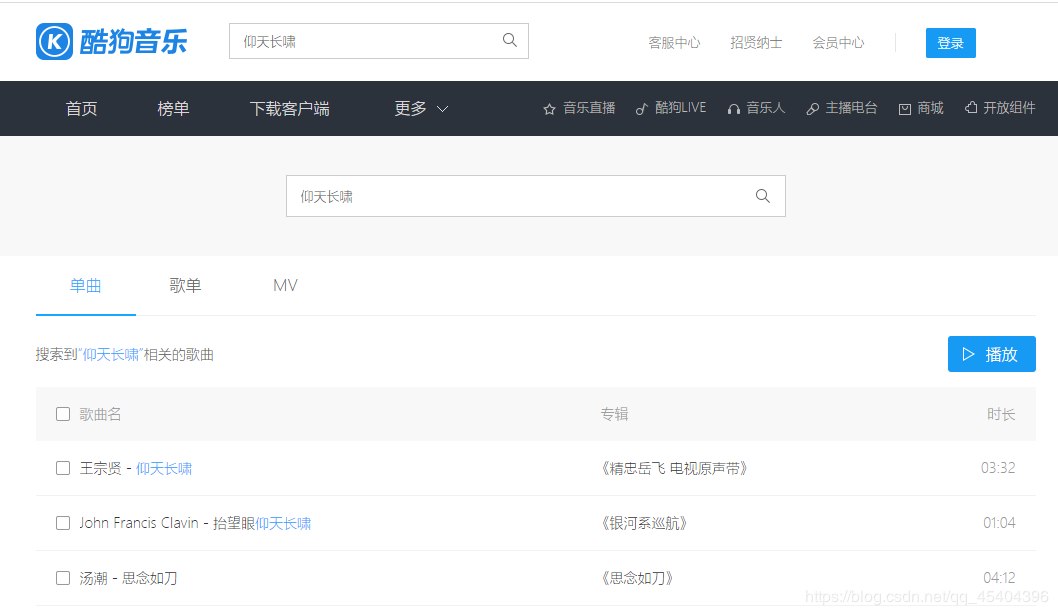
想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息。
这个时候我们就应该换一种思路了,点击Network下的JS,如果没有什么信息,可按F5进行刷新。之后我们点击如下:
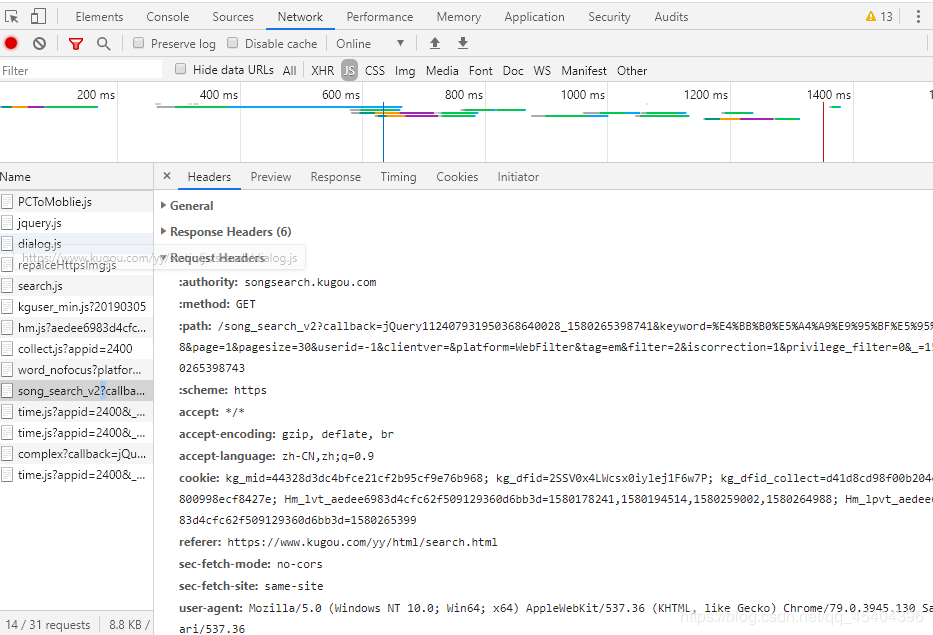
然后我们在点击Preview,可发现:

lists下面有我们需要的信息,可以通过这些信息重新组成一个网址:
https://www.kugou.com/song/#hash=(FileHash)&album_id=(AlbumID)
FileHash和AlbumID的值能在lists下面找到。
完成这个操作,点击进入这个组合的网址,就可以进入到这个界面了。
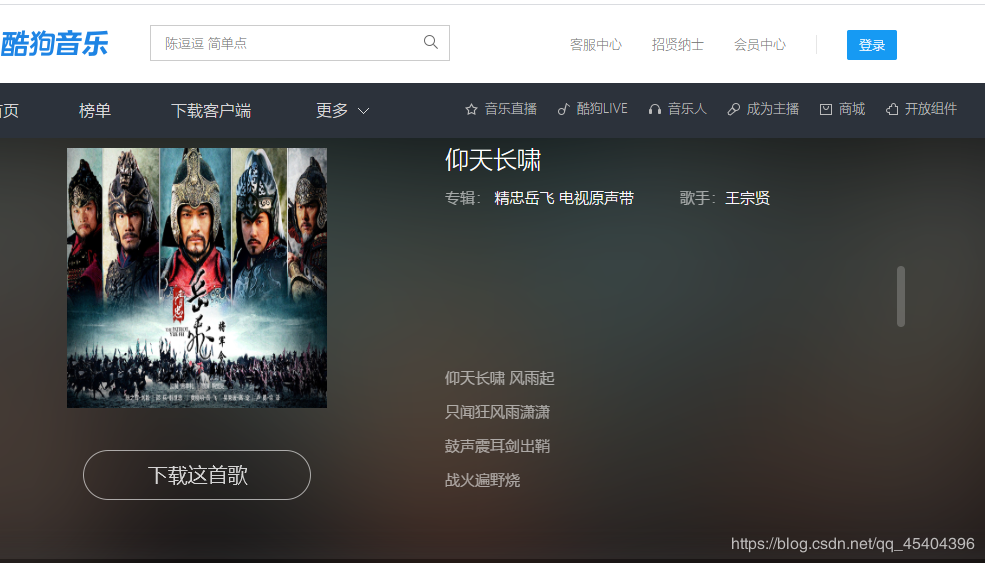
再单击右键进行检查,发现这里有这首歌的下载链接
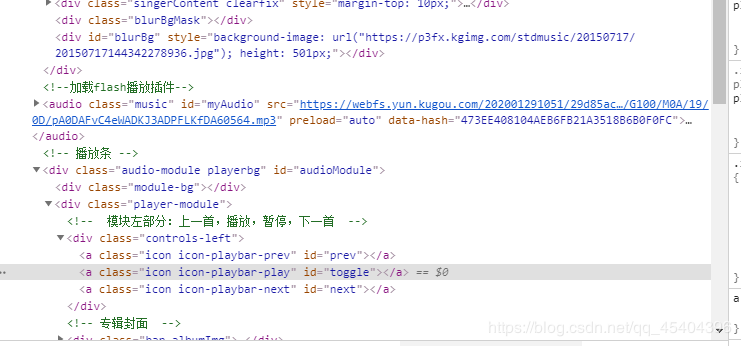
这个时候再进行爬取,发现其他信息都有,唯独没有这个下载链接,点击Network下面的JS,刷新发现有一个JS文件上有这个链接
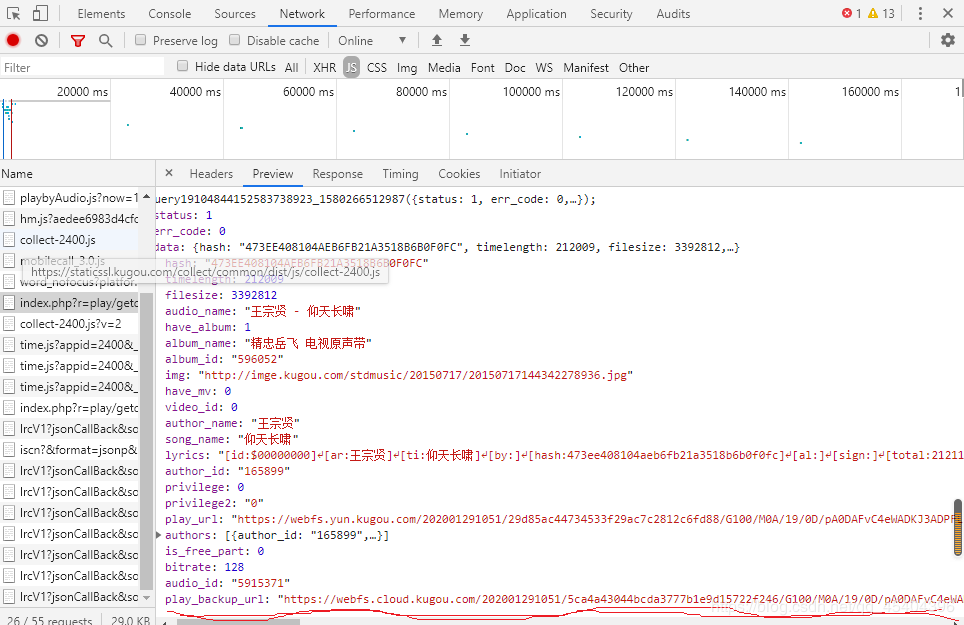
然后我们只需将这个网址进行组合即可https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104844152583738923_1580266512987&hash=473EE408104AEB6FB21A3518B6B0F0FC&album_id=596052&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4&_=1580266512988
通过多次组合发现,这个网址只需hash、album_id、dfid、mid和platid就可以得到所需要的信息了,且dfif、mid和platid的值是不变的,而前面的两个变量的值在我说的第四幅图中可以找到。
完成这个之后,点击进入,就可以得到想要的信息了。、
代码代码如下:
from urllib.request import urlopen
import urllib.parse
import json # 导入json模块,为了使下载的js文件更容易得到所需的信息
import time
import sys
import os # 导入sys和time模块是为了显示进度条 def Time_1(): # 进度条函数
for i in range(1,51):
sys.stdout.write('\r')
sys.stdout.write('{0}% |{1}'.format(int(i%51)*2,int(i%51)*'■'))
sys.stdout.flush()
time.sleep(0.125)
sys.stdout.write('\n') def KuGou_music(): keyword=urllib.parse.urlencode({'keyword':input('请输入歌名:')})
keyword=keyword[keyword.find('=')+1:]
url='https://songsearch.kugou.com/song_search_v2?callback=jQuery1124042761514747027074_1580194546707&keyword='+keyword+'&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1580194546709'
content=urlopen(url=url)
content=content.read().decode('utf-8')
str_1=content[content.find('(')+1:-2]
str_2=json.loads(str_1)
Music_Hash={}
Music_id={}
for dict_1 in str_2['data']['lists']:
Music_Hash[dict_1['FileName']]=dict_1['FileHash']
Music_id[dict_1['FileName']]=dict_1['AlbumID']
# print(dict_1) list_music_1=[music for music in Music_Hash] # 匹配到的所有歌曲名 列表
list_music=[music for music in Music_Hash] for i in range(len(list_music)):
if '- <em>' in list_music[i]:
list_music[i]=list_music[i].replace('- <em>','-')
if '</em>' in list_music[i]:
list_music[i]=list_music[i].replace('</em>','')
if '<em>' in list_music[i]:
list_music[i]=list_music[i].replace('<em>','') # 使歌曲名称更加美观
# 如: < em > 战狼 < / em > - 断情笔 经过这个处理之后 战狼 - 断情笔 for i in range(len(list_music)):
print("{}-:{}".format(i+1,list_music[i])) music_id_1=int(input('请输入你想下载的歌曲序号:')) # 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=E77548A33D7AF84F727C32A786C107D0&album_id=542163&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
# 一个加载js文件的标椎式样网址 url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash='+Music_Hash[list_music_1[music_id_1-1]]+'&album_id='+Music_id[list_music_1[music_id_1-1]]+'&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
js_content=urlopen(url=url)
str_3=js_content.read().decode('utf-8') #所加载的js中的内容
dict_2=json.loads(str_3) # 将这个js格式转换成为字典格式 try:
music_href=dict_2['data']['play_backup_url'] #下载的歌曲网址 music_content=urlopen(url=music_href).read()
try:
os.mkdir('D:\酷狗音乐下载')
except Exception as e:
print(e,'但不要紧,程序仍然执行')
finally:
music_path='D:\酷狗音乐下载\\'+list_music[music_id_1-1]+'.mp3' # 歌曲下载路径
with open(music_path,'wb') as f:
print('正在下载当中...')
f.write(music_content)
Time_1()
print('{}.mp3下载成功!'.format(list_music[music_id_1-1])) except:
print('对不起,没有该歌曲的版权!') if __name__=='__main__':
print('------声明:本小程序仅供娱乐,切莫用于商业活动,一经发现,概不负责!-------')
KuGou_music()
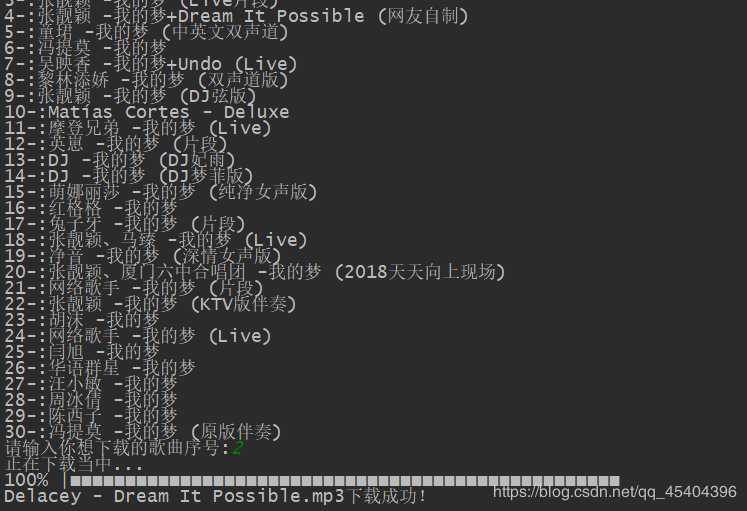
注意:代码中的那个下载路径必须是已经存在了的,否则会报错。
一些歌曲是下载不了的,如 你的名字 ,这个是付费歌曲,这个程序只能下载 酷狗音乐在网页上能播放的。
注意:这个代码仅供娱乐和学习,切莫用于商业目的,一经发现,概不负责!
Python 应用爬虫下载酷狗音乐的更多相关文章
- Python爬虫下载酷狗音乐
目录 1.Python下载酷狗音乐 1.1.前期准备 1.2.分析 1.2.1.第一步 1.2.2.第二步 1.2.3.第三步 1.2.4.第四步 1.3.代码实现 1.4.运行结果 1.Python ...
- 【Python3爬虫】下载酷狗音乐上的歌曲
经过测试,可以下载要付费下载的歌曲(n_n) 准备工作:Python3.5+Pycharm 使用到的库:requests,re,json,time,fakeuseragent 步骤: 打开酷狗音乐的官 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Python实例---爬去酷狗音乐
项目一:获取酷狗TOP 100 http://www.kugou.com/yy/rank/home/1-8888.html 排名 文件&&歌手 时长 效果: 附源码: import t ...
- Python代码搜索并下载酷狗音乐
运行环境: Python3.5+Pycharm 实例代码: import requests,re keyword = input("请输入想要听的歌曲:") url = " ...
- Python爬虫:通过做项目,小编了解了酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 【python3】酷狗音乐及评论回复下载
新年快乐,上班第一天分享一个python源码,功能比较简单,就是实现酷狗音乐的音乐文件(包含付费音乐)和所有评论回复的下载. 以 米津玄師 - Lemon 为例, 以下为效果图: 1.根据关键词搜索指 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
随机推荐
- 在CentOS7上面部署项目,报出找不到表的错误
最近在linux服务器上面部署一个javaweb的项目,报出一些奇怪的错误,拉到报错信息的最下面显示mysql数据库的某个表找不到,可以在windows上面是能正常运行的. 最后发现原来是linux服 ...
- 2020 DJBCTF RE wp
1.anniu 吐槽:浓浓一股杂项的味道,妈的,用xspy和resource har加ida死活搜不到回调函数,淦 下一个灰色按钮克星,直接把灰色的按钮点亮,直接点击就可以出了,软件下载链接:http ...
- 家庭账本开发day08
对查询到额数据进行相关的操作,删除.对删除按钮绑定事件 点击后发送ajax请求到servlet,删除相关的数据后,返回flag到前端 若后台删除成功,则前台进行相应的.close():输出点击行的数据 ...
- 线性回归与梯度下降(ML作业)
Loss函数 题目一:完成computeCost.m function J = computeCost(X, y, theta) %COMPUTECOST Compute cost for linea ...
- 网络损伤仪WANsim中的乱序功能
乱序 乱序功能需要指定每个帧 发生乱序的概率,以及新的帧的位置相较于原来位置的时间范围. 乱序的概率范围是0%~20%,颗粒度是0.001%.Delay的设置范围为 0s~10s,颗粒度为0.1 ms ...
- POJ3190 - 优先队列 贪心
POJ3190 将所有牛从小到大排序然后用优先队列(小根堆)依次记录插入的牛的结束时间,如果插入牛时起始时间大于首元素,ans不增加并弹出首元素. 挺简单的.那么为什么我会写(水)这篇博客呢? #in ...
- java内存模型——重排序
线程安全问题概括来说表现为三个方面:原子性,可见性和有序性. 在多核处理器的环境下:编译器可能改变两个操作的先后顺序:处理器可能不是完全依照程序的目标代码所指定的顺序执行命令:一个处理器执行的多个操作 ...
- 通过Xlib枚举指定进程下所有窗体
在windows系统下如果想要枚举指定进程的窗体,我们可以通过EnumWindows加上自己实现的回调函数进行实现,那么在linux下该如何做呢? 其实也很简单,在linux下,我们可以通过xlib中 ...
- (python函数04)zip(*sorted(zip()))
zip(*sorted(zip())) 用这个玩意儿可以以对两个迭代对象进行排序. 示例代码01 cnts = [2, 4, 3, 6, 5] boundingBoxes = [(730, 20, ...
- ajax()返回Array
后台查询的数据为数组$arr,需要将数组 echo json_encode($arr);前台ajax拿到数据 然后用 eval("(+data+)"); 来将json转为json对 ...