MapReduce01 概述
MapReduce 概述
放假回家了,笔记本没有环境,后面的图片源于网络
1.定义
MapReduce是一个分布式运算程序的编程框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
2.优缺点
优点
1.MapReduce 易于编程
它简单的实现一些接口, 就可以完成一个分布式程序, 这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。
2.良好的扩展性
可以动态增加服务器,解决计算资源不够的问题
3.高容错性
任何一台机器挂掉,可以将任务转移到其他节点, 而且这个过程不需要人工参与, 而完全是由Hadoop内部完成的。
4.适合 PB 级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点
1.不擅长实时计算
MapReduce 无法像 MySQL 一样,在毫秒或者秒级内返回结果。不擅长快速响应。
2.不擅长流式计算
流式计算的输入数据是动态的, 而 MapReduce 的输入数据集是静态的, 不能动态变化。
Sparkstreaming和flink擅长流式计算
3.不擅长DAG有向无环图计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。MapReduce可以做,但是中间的结果会存于磁盘,会造成大量的磁盘 IO,效率很低。
Spark擅长,中间结果基于内存。
3.MapReduce核心思想
MapReduce将计算过程分为两个阶段:Map和Reduce
1.Map阶段并行处理输入数据 –> 负责大任务分小任务
2.Reduce阶段对Map结果进行汇总 –> 负责汇总结果
需求
统计输入数据中每一个单词出现的次数,统计结果a-p一个文件,q-z一个文件。
核心思想
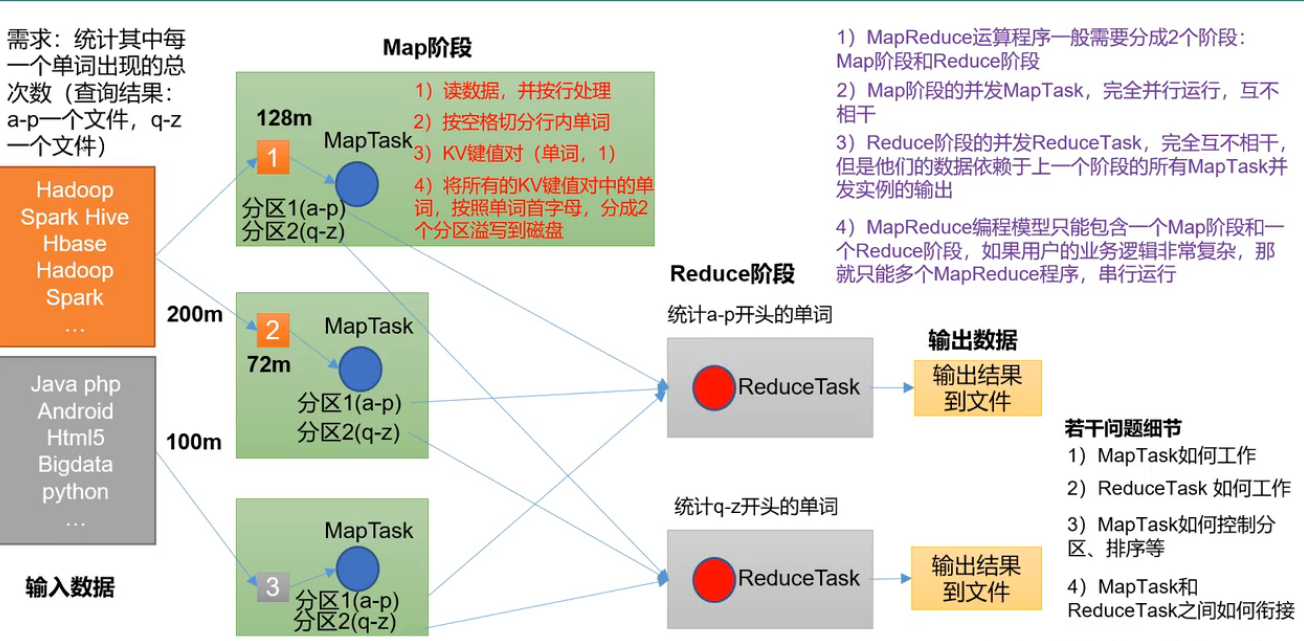
说明
1.Map阶段统计单词的时候,只会记录ranan:1,不会记录ranan:2,相同单词统计次数由Reduce阶段完成
2.MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段。如果逻辑很复杂,只能多个MapReduce程序串行运行。也就是中间结果也会写入磁盘,所以说不擅长DAG有向无环图。
4.MapReduce进程
一个完整的MapReduce程序再分布式运行时有三类实例进程。
(1)MrAppMaster(是ApplicationMaster的子进程):负责整个程序的过程调度及状态协调。是运行一个job/任务/mr的老大
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
5.官方 WordCount 源码
案例的存储位置:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce
下下来是个jar包,把jar包拖进编译工具里,通过反编译工具反编译源码。

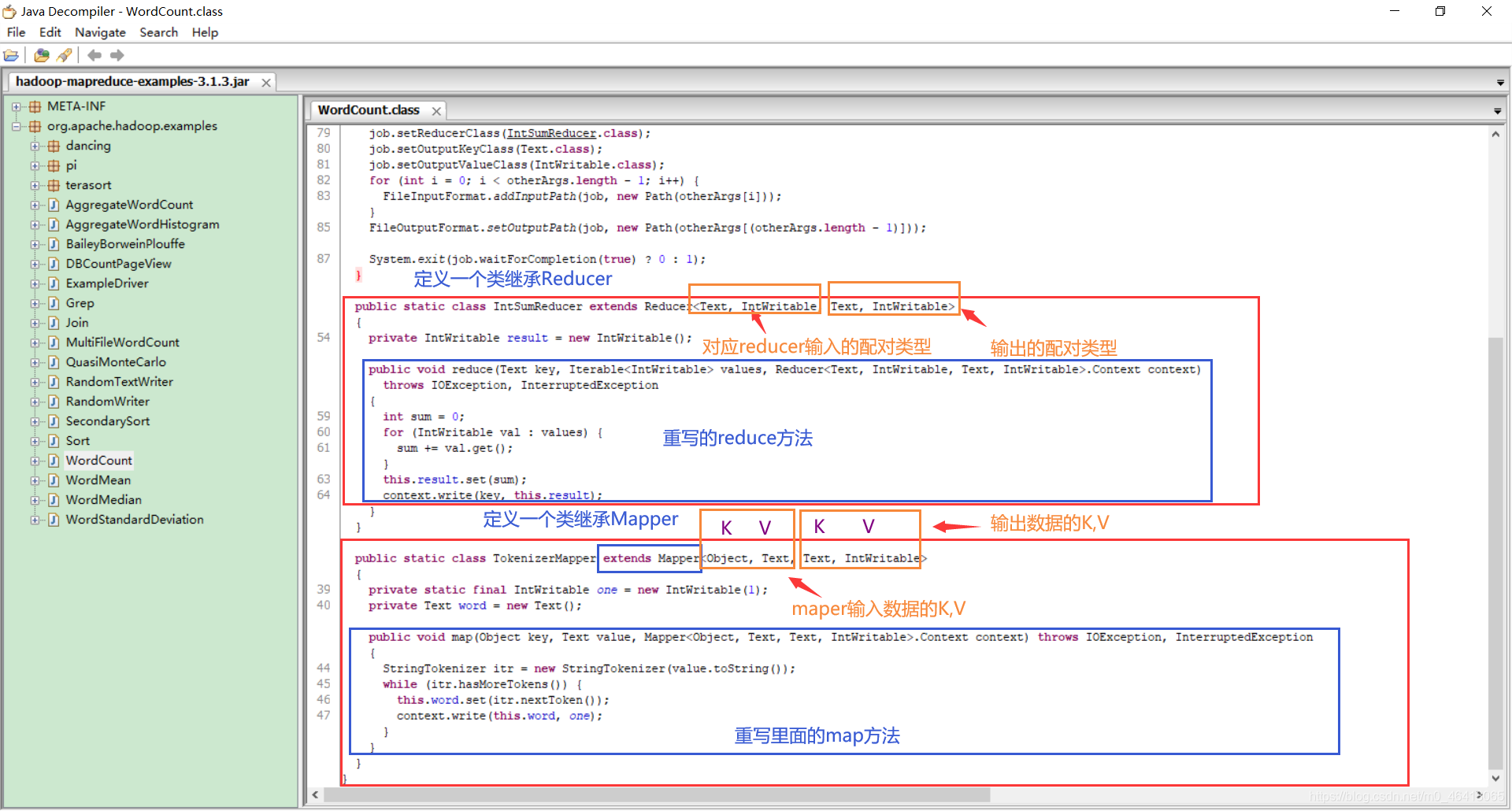
发现 WordCount 案例
1.写在main方法里的叫driver
2.有 Map 类
3.Reduce 类
数据的类型是 Hadoop 自身封装的序列化类型。
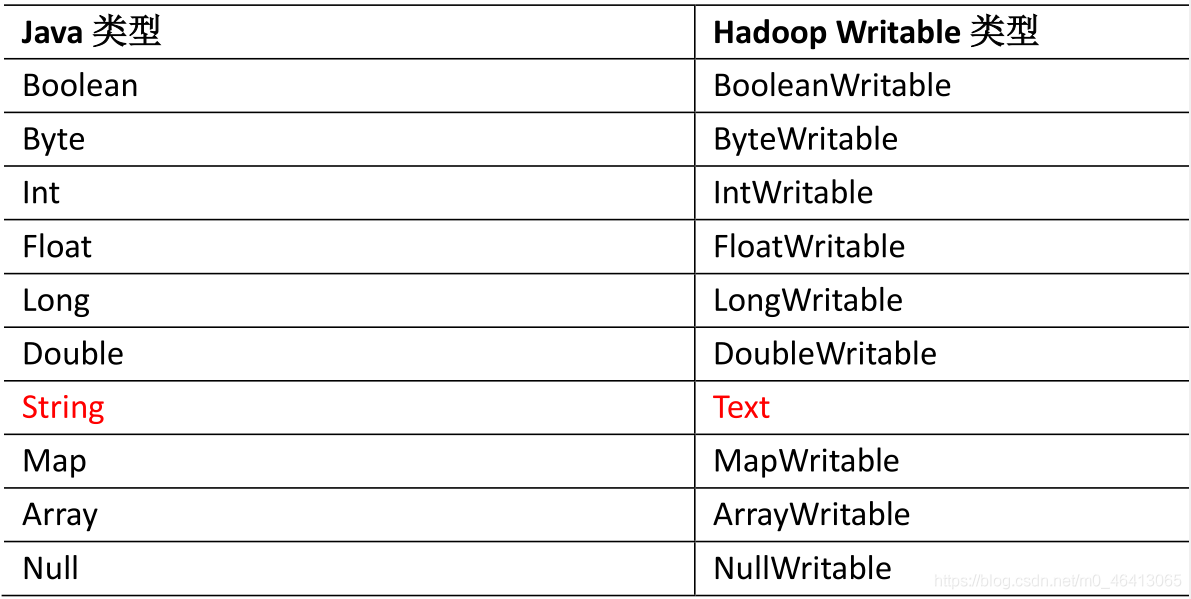
6.常用数据序列化类型
7.MapReduce编程规范
用户编写的程序分为三部分:Mapper、Reducer和Driver
7.1 Mapper阶段
1.用户自定义的Mapper要继承系统的Mapper类

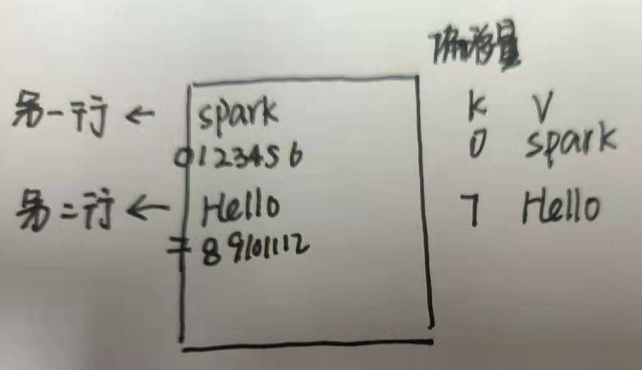
2.Mapper的输入数据是KV对的形式(KV的类型可自定义)
K是这一行的偏移量,V是这一行的内容。
3.Mapper中的业务逻辑写在map()方法中
4.Mapper的输出数据是KV对的形式(KV的类型可自定义)
5.MapTask进程对每一个<K,V>调用一次map()方法
7.2 Reduce阶段
1.用户自定义的Reducer要继承自己的父类
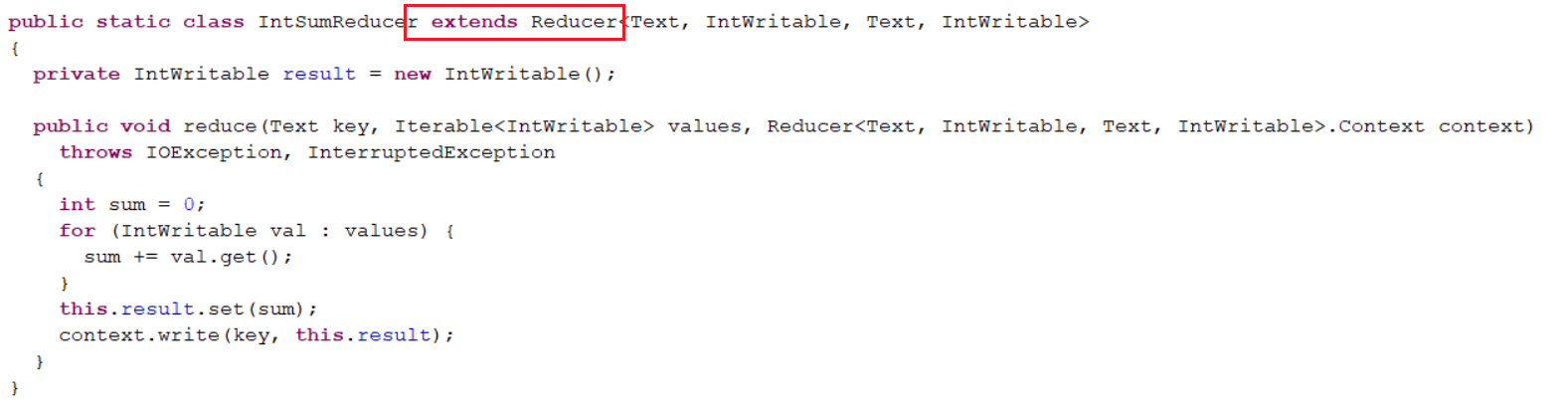
2.Reducer的输入类型对应Mapper的输出数据类型,也是KV。
3.Reduce的业务逻辑写在reduce()方法中
4.ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法。
有多少个不同k,调用多少次reduce。

7.3 Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
8.WordCount 案例实操
本地测试
1.需求
再给定的文本文件中统计输出每一个单词出现的总次数
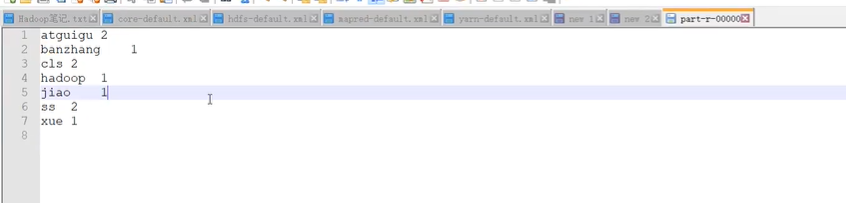
1).给定的输入数据 Hello.txt

2).期望输出数据(按首字母排序)
atguigu 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
2.需求分析

Mapper阶段说明
1.转换成String的原因是,Text的API少,Java中对字符串处理的API多。
Driver阶段说明
1.指定job的输出结果路径,输出的文件不能提前存在
3.环境准备
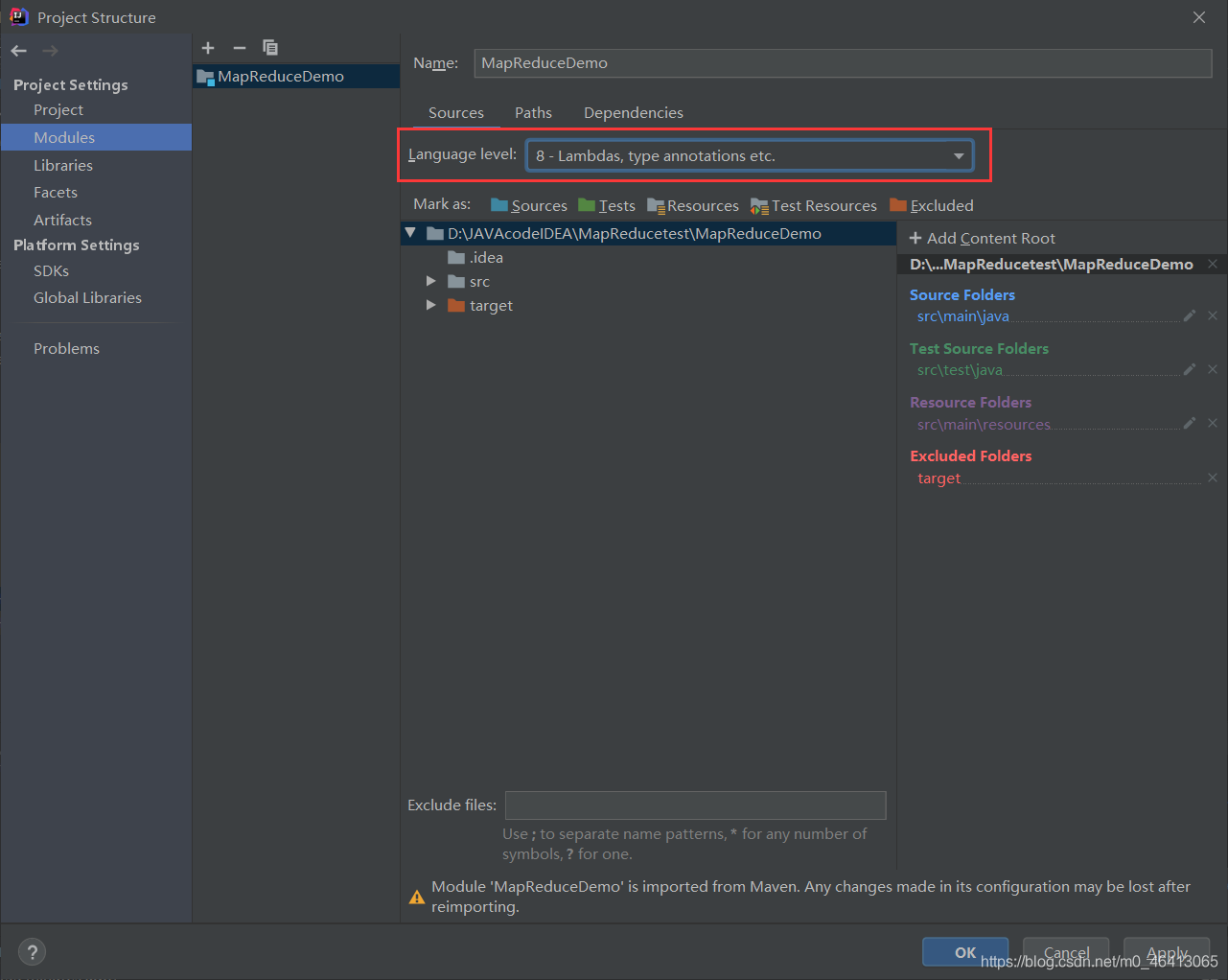
1)创建maven工程MaoReduceDemo,修改成自己的Maven仓库.
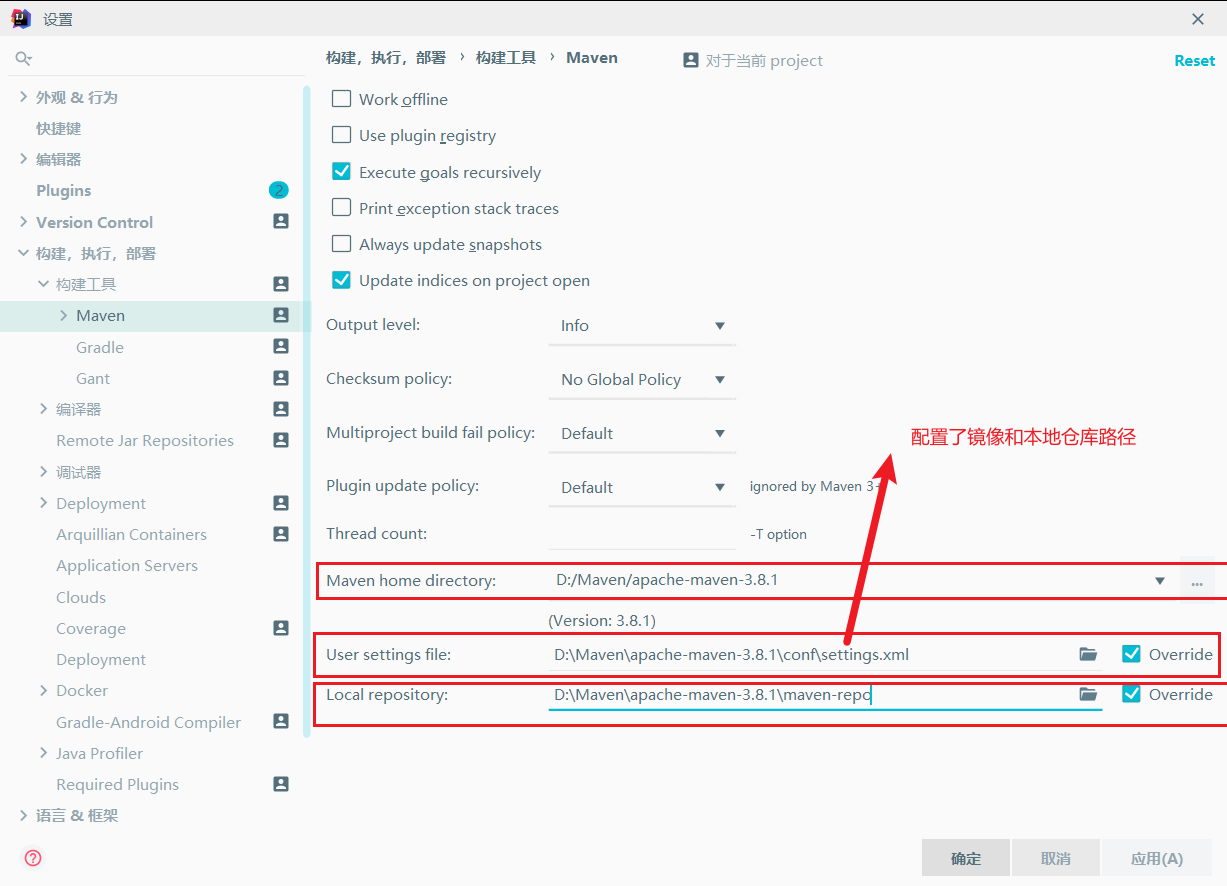
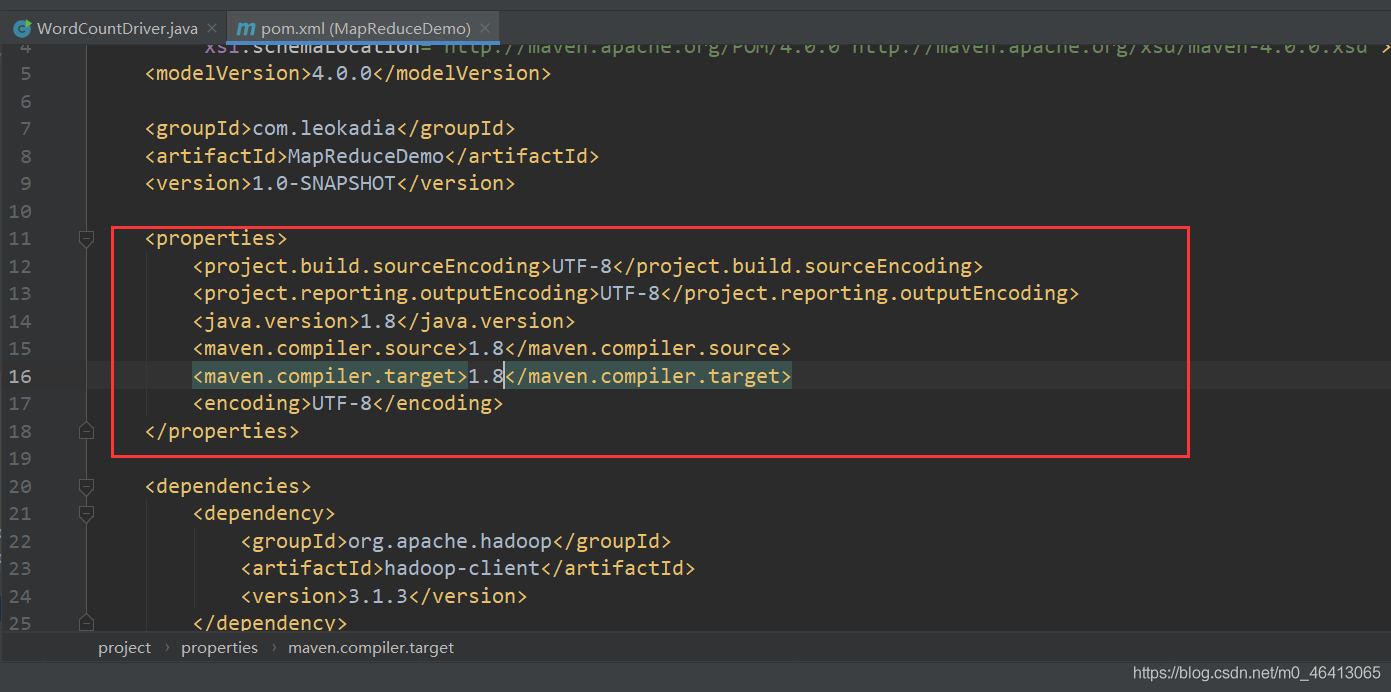
2)在pom.xml文件中添加版本信息和依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
3)在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”(打印相关日志)
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4)创建包名 com.ranan.mapreduce.wordcount
在本包下创建三个类WordCountMapper、WordCountReducer、WordCountDriver
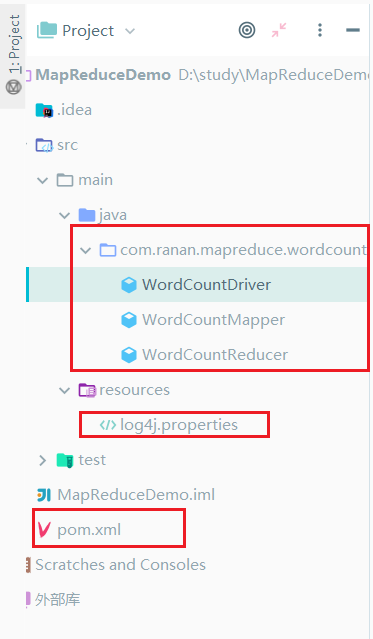
4.编写程序
始终关注输入与输出
编写Mapper类
说明
1.继承的类导入import org.apache.hadoop.mapreduce.Mapper;
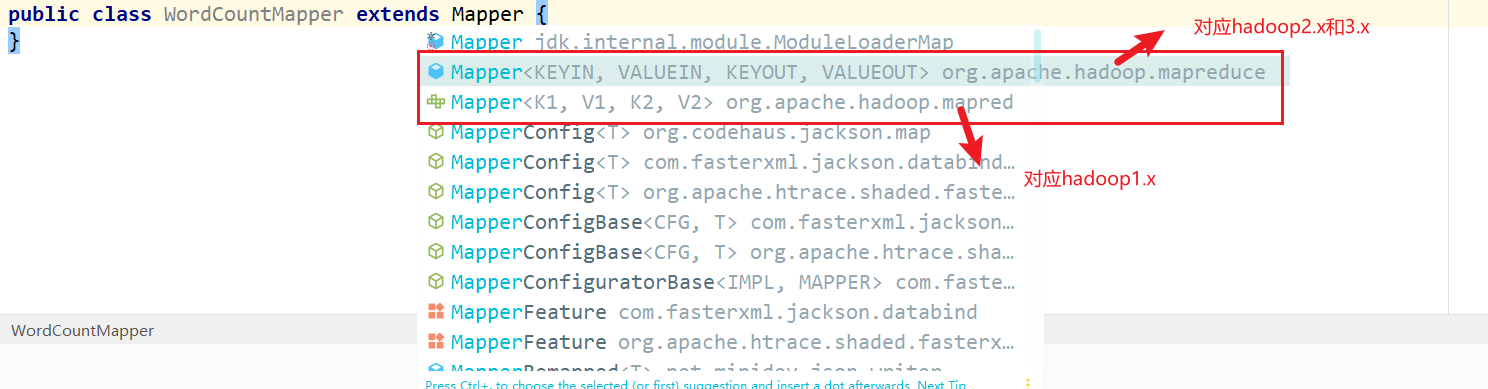
2.Text导入的包是org.apache.hadoop.io
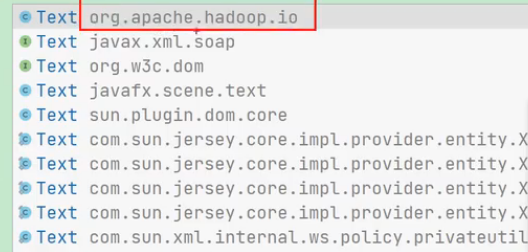
3.Mapper类
package com.ranan.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key的类型:LongWritable
* VALUEIN,map阶段输入value类型:Text
* KEYOUT,map阶段输出的Key类型:Text
* VALUEOUT,map阶段输出的value类型:IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//定义输出类型 会反复使用到,定义为成员变量。
private Text outK = new Text();
private IntWritable outV = new IntWritable(1); //map阶段不进行聚合,所以记为1
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行 转化为string类型使用其api进行分割
// xxxxxx xxxxxx
String line = value.toString();
// 2 切割(取决于原始数据的中间分隔符)
// xxxxxxx
// xxxxxxx
String[] words = line.split(" ");
// 3 循环写出
for (String word : words) {
//输出的类型需要时Text,但是当循环次数大时,不断创建态浪费资源。同理map的是每行调用,所以这里把该语句放在最外面。
//Text outk = new Text();
// 封装outk
outK.set(word);
// context信息传递,把结果传递出去
context.write(outK, outV);
}
}
}
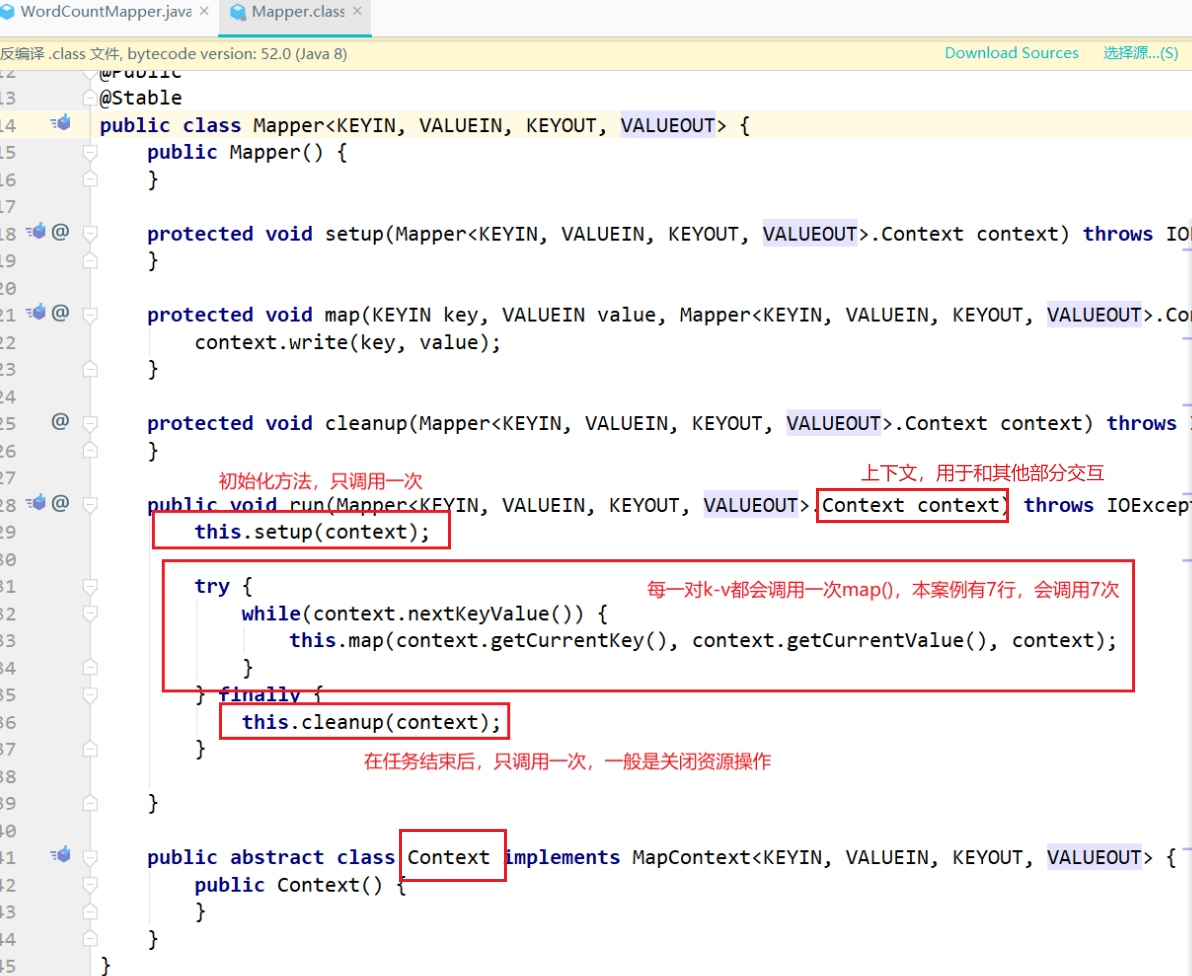
编写reducer类
类的结构同mapper方法相似。
抽象类 Context 用于与map和系统交互
run方法里{
setup:任务开始的初始化
核心方法reduce:每一种key会被调用一次
cleanup:任务结束后的收尾
}
reduce方法的重写。
map的输出是reduce的输入。
package com.ranan.mapreduce.wordcount;
//注意导入的包
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN, reduce阶段输入的key的类型:Text
* VALUEIN,reduce阶段输入value类型:IntWritable
* KEYOUT,reduce阶段输出的Key类型:Text
* VALUEOUT,reduce阶段输出的value类型:IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
//values不是迭代器,类似与集合,values.iterator()获取其迭代器
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// xxxxxxx, (1,1)
// 将values进行累加
for (IntWritable value : values) {
//value.get() 将IntWritable转换成int类型
sum += value.get();
}
outV.set(sum);
// context信息传递,把结果传递出去
context.write(key,outV);
}
}
编写 Driver 驱动类
1.获取job
2.设置jar包路径
3.关联mapper和reducer
4.设置map输出的kv类型
5.设置最终输出的kV类型,有些程序没有reduce阶段,所以这里设置的是最终输出而不是reduce输出类型
6.设置输入路径和输出路径
7.提交job
package com.ranan.mapreduce.wordcount;
//注意导入的包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output"));
// 7 提交job
//正常提交job.submit()
boolean result = job.waitForCompletion(true); //可以监控并打印job信息
System.exit(result ? 0 : 1);
}
}
补充类型转换
String与Text转换
//Text转换成String
text.toString()
//String转换成Text
new Text outK = new Text();
outK.set(string)
Int与IntWritable转换
//IntWritable转换成int
text.get()
//Int转换成IntWritable
new IntWritable outK = new IntWritable();
outK.set(int)
5.本地测试
注意:此时如果再运行一遍,会报错。在mapreduce中,如果输出路径存在会报错
Debug
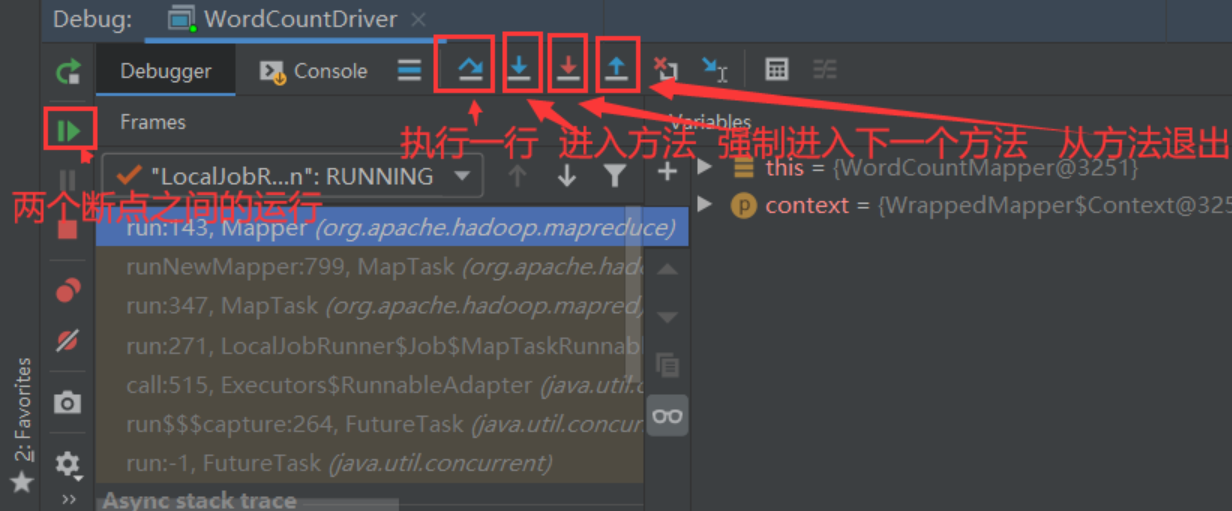
先执行WordCountDriver类的main方法,之后跳转到mapper类的run方法。
run方法里先执行setup初始化,在执行重写的map方法,最后执行cleanup方法。
进入到reducer类的run方法。
run方法里先执行setup初始化,在执行重写的reduce方法,最后执行cleanup方法。
提交到集群测试
本地运行是通过下载了hadoop相关的依赖,运行的代码。但是在生产环境中,是需要在linux虚拟机上的集群运行的。
如何在linux上运行,打包上传到虚拟机上。
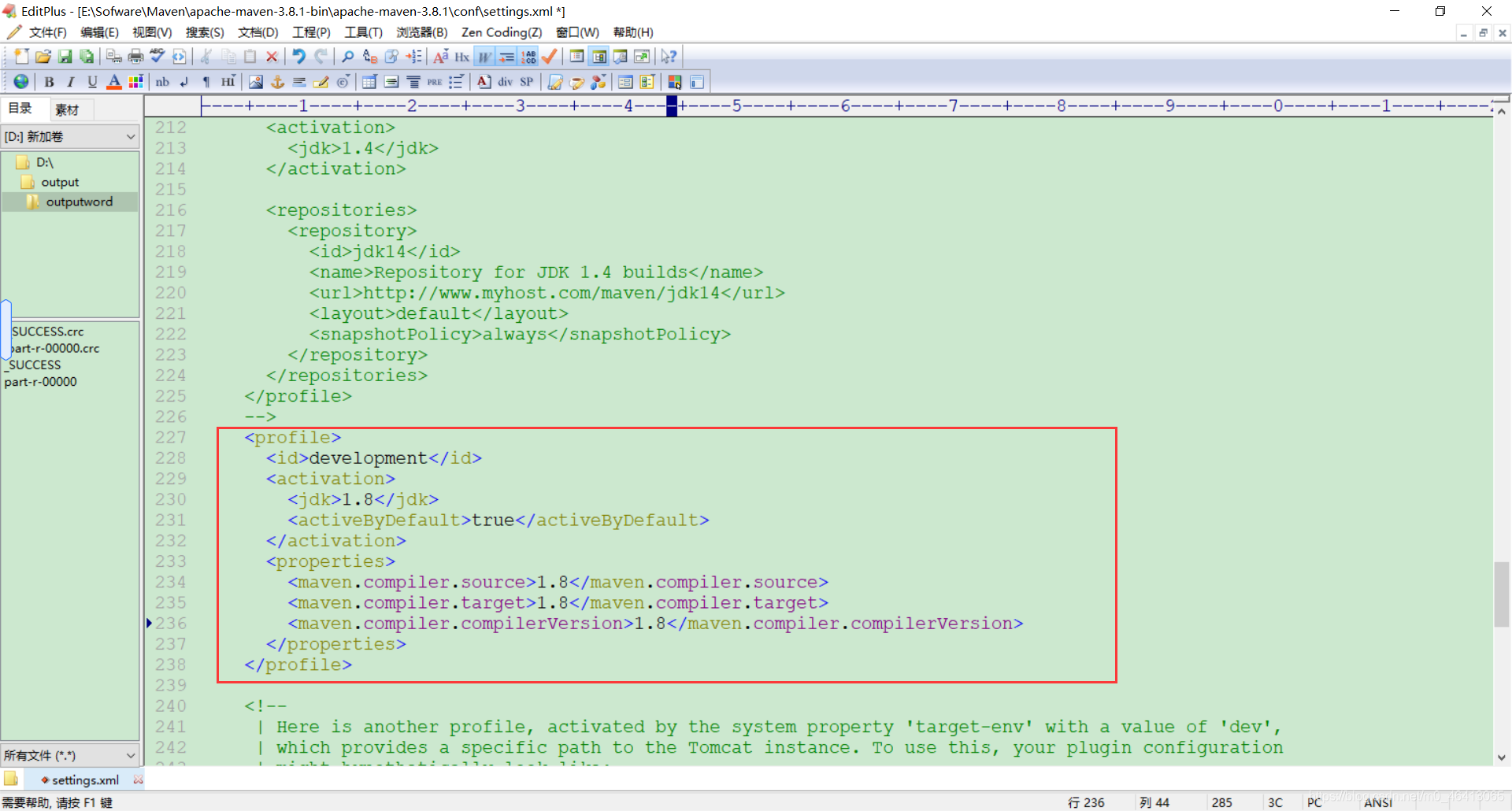
1.用 maven 打 jar 包,需要添加的打包插件依赖
将以下代码添加到pom.xml配置文件种
<project>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
//使用jdk1.8编译因为虚拟机上装的jdk是1.8版本的 <source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
//把依赖也打包进去如pom.xml里的junit,org.apche.hadoop..等
//正常情况是不需要的,集群里已经有了
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.将程序打成 jar 包
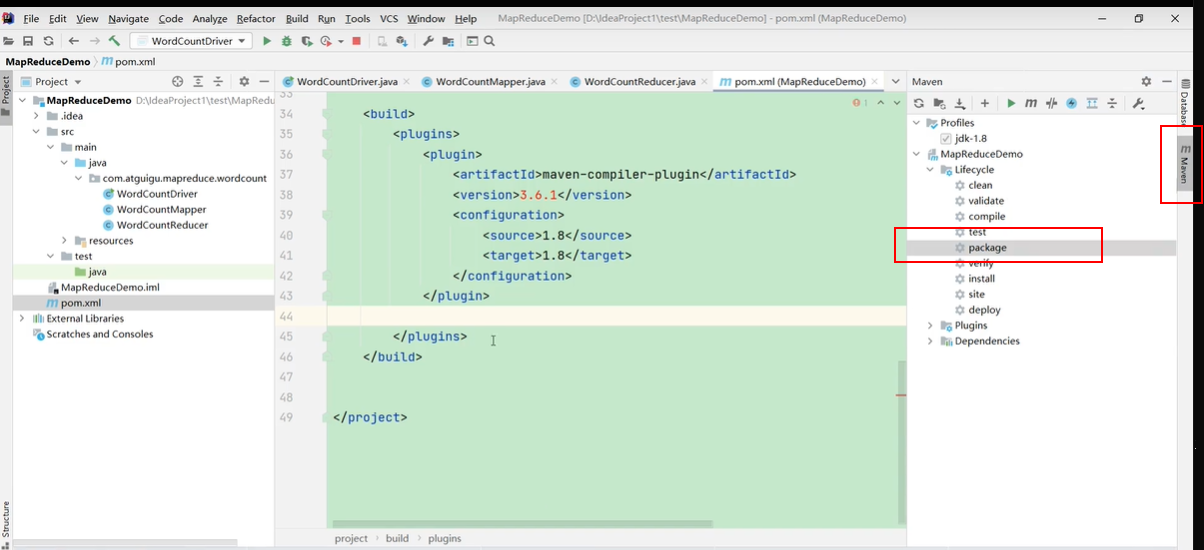
打包完毕,生成jar包
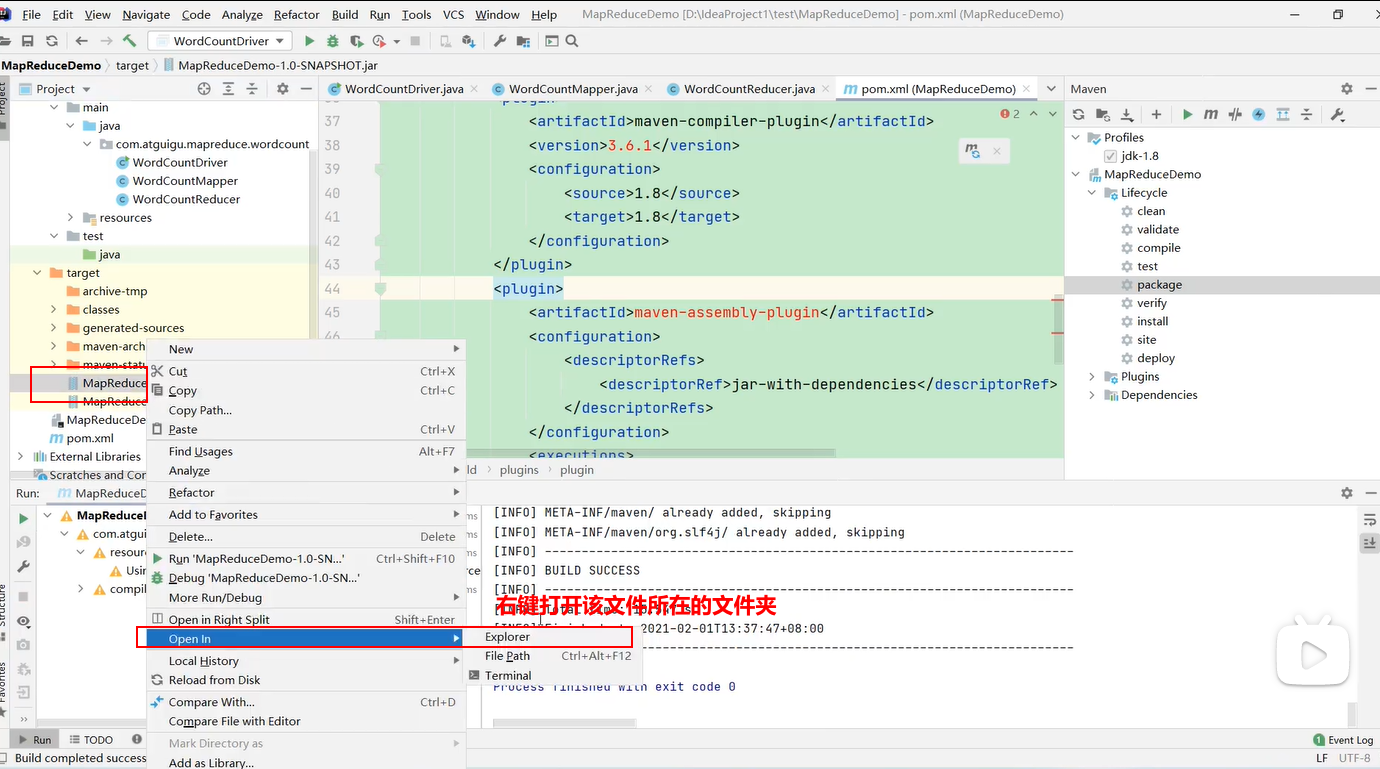
3.上传jar包到Hadoop 集群的/opt/module/hadoop-3.1.3 路径
注意
刚刚的程序中,我们写的路径是本地windows的路径,那么上传到集群该路径是肯定不存在的,所以还需要修改程序。
之前在集群中使用的命令,输入的路径和输出的路径是不确定的,是依靠命令行动态输入的。
[ranan@hadoop102]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
修改程序,对于新改的程序,先点clean把前面的删掉,再点package进行导包。
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
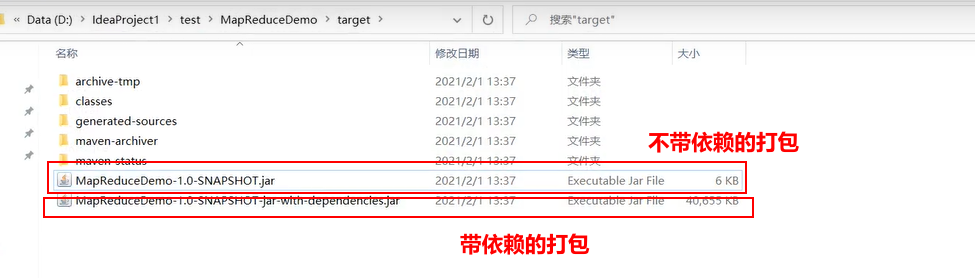
将6kb(不带依赖)的复制到桌面并改名wc.jar。
linux上先切换到jar包要上传的路径
cd /opt/Software/hadopp-3.1.3
拖拽上传
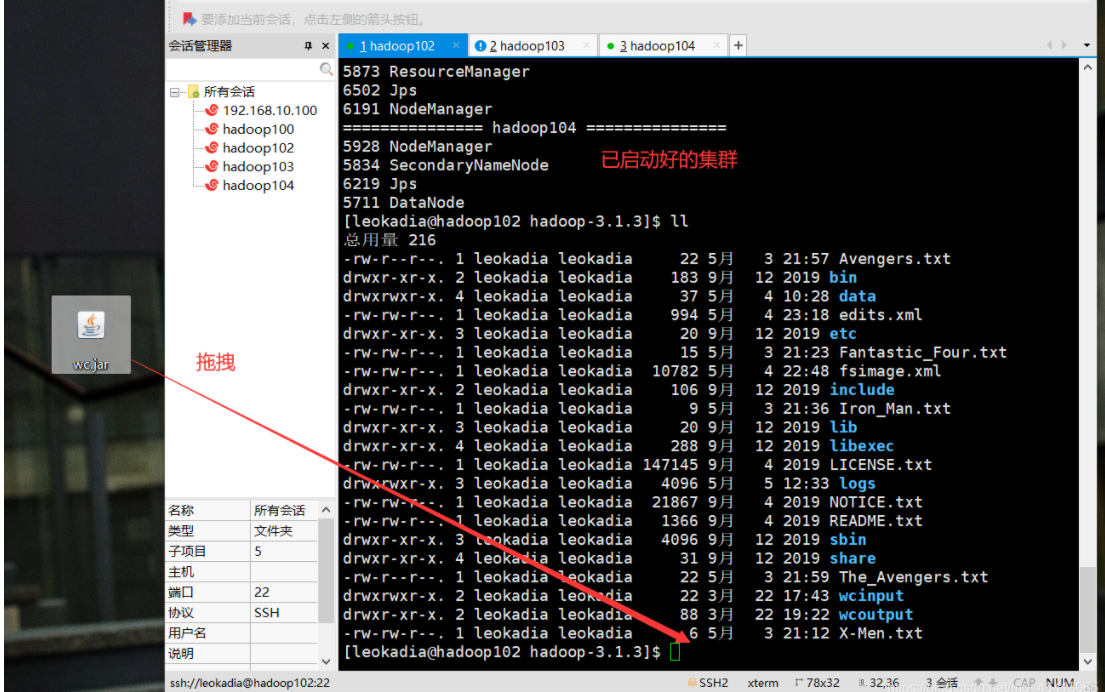
4.执行wc.jar包
首先需要输入的源文件
启动集群后,发现/input/word.txt可以作为输入文件
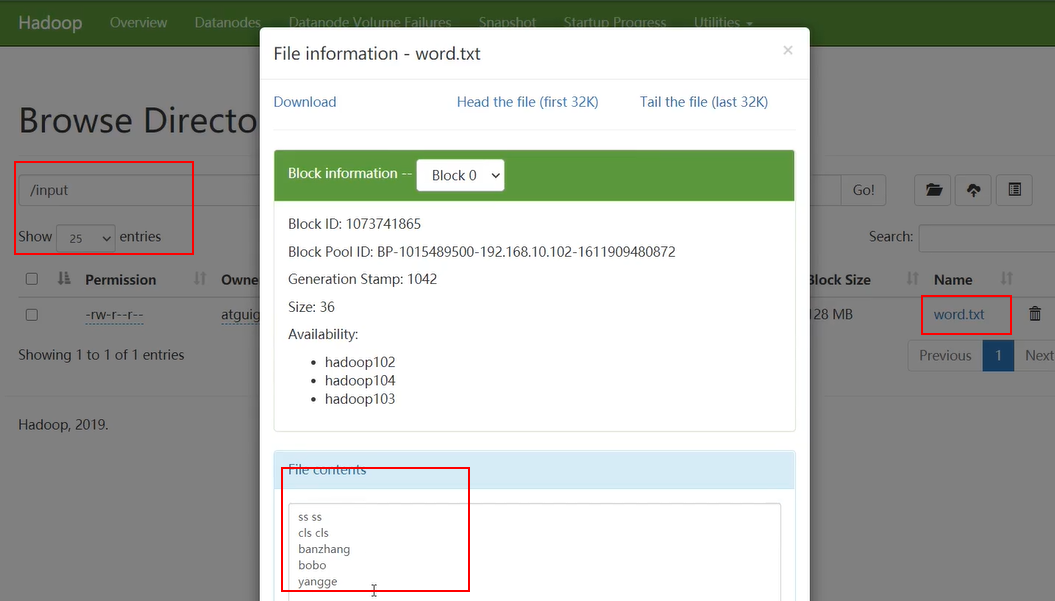
执行wc.jar程序

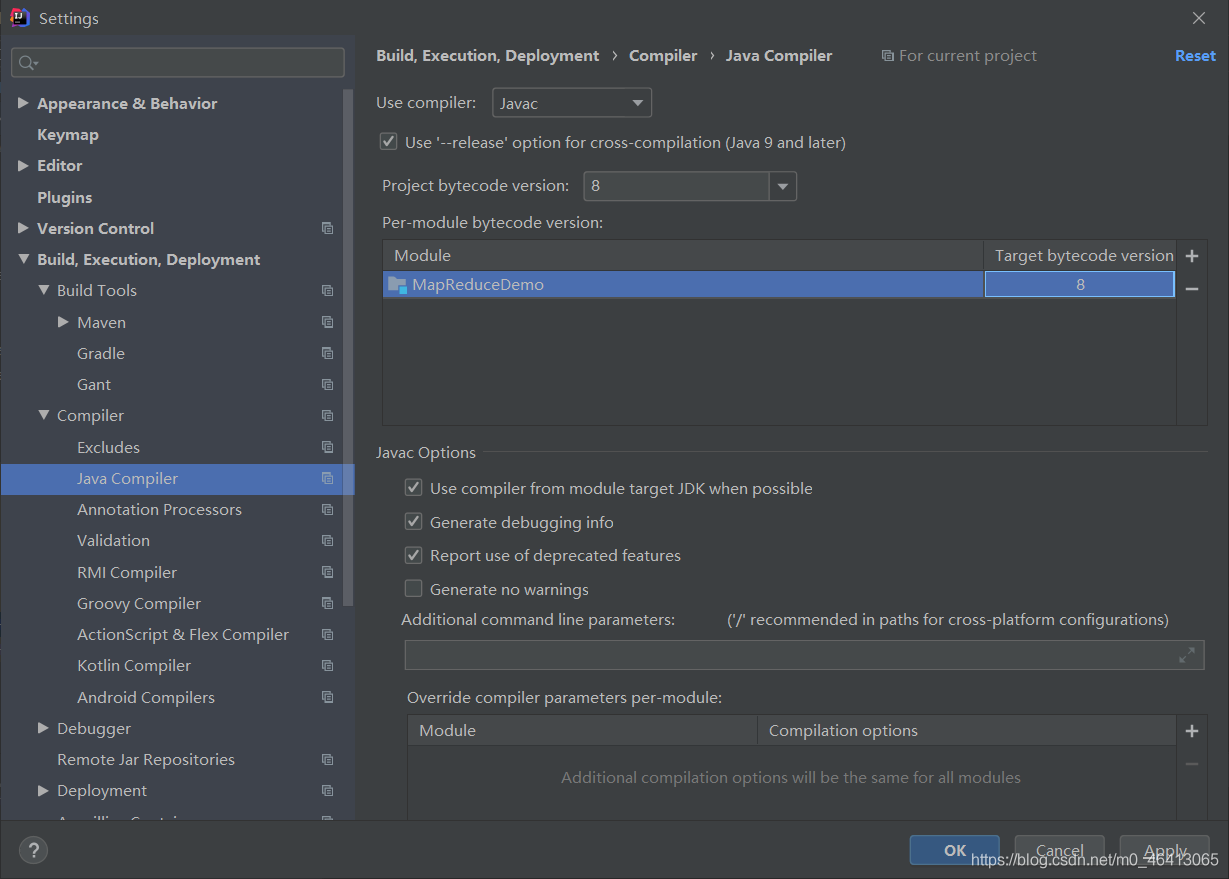
注意
打包用的JDK8,hadoop里面是JDK8,但是本地安装的是JDK11、Maven使用的是JDK11。
所以执行命令的时候会报错。
hadoop3.x目前只支持jdk1.8。修改版本到JDK8。
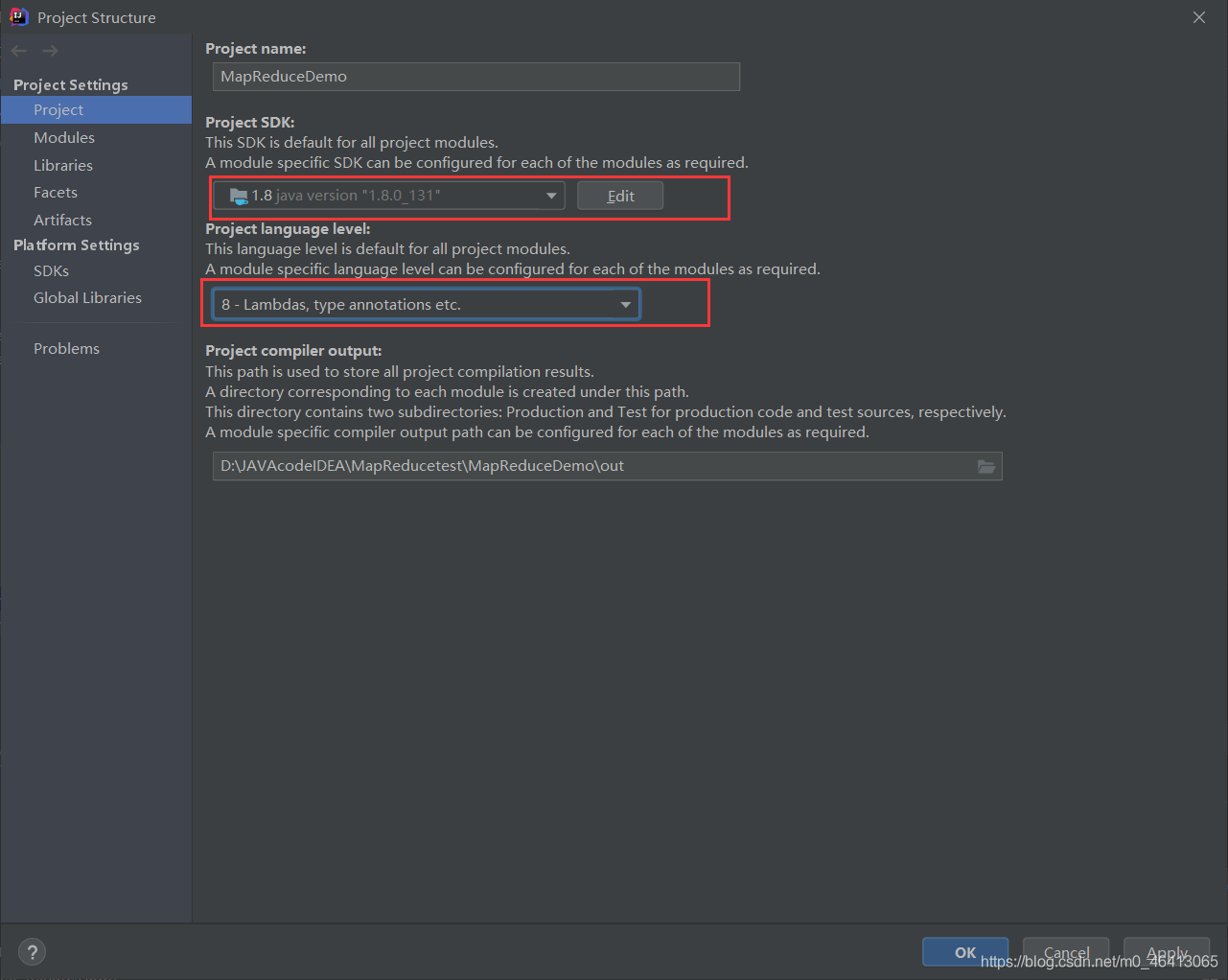
然后再重新生成jar包,导入jar包到集群,再重新运行程序。
MapReduce01 概述的更多相关文章
- Hadoop| MapReduce01 概述
概述 分布式运算程序: 优点:易于编程:良好扩展性:高容错性:适合PB级以上海量数据的离线处理: 缺点:不擅长实时计算:不擅长流式计算:不擅长DAG有向图计算: 核心思想: 1)分布式的运算程序往往需 ...
- 【AR实验室】ARToolKit之概述篇
0x00 - 前言 我从去年就开始对AR(Augmented Reality)技术比较关注,但是去年AR行业一直处于偶尔发声的状态,丝毫没有其"异姓同名"的兄弟VR(Virtual ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Swift3.0服务端开发(一) 完整示例概述及Perfect环境搭建与配置(服务端+iOS端)
本篇博客算是一个开头,接下来会持续更新使用Swift3.0开发服务端相关的博客.当然,我们使用目前使用Swift开发服务端较为成熟的框架Perfect来实现.Perfect框架是加拿大一个创业团队开发 ...
- .Net 大型分布式基础服务架构横向演变概述
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
- [C#] 进阶 - LINQ 标准查询操作概述
LINQ 标准查询操作概述 序 “标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法.大多数这些方法都在序列上运行,其中的序列是一个对象,其类型实现了IEnumerable<T> ...
- 【基于WinForm+Access局域网共享数据库的项目总结】之篇一:WinForm开发总体概述与技术实现
篇一:WinForm开发总体概述与技术实现 篇二:WinForm开发扇形图统计和Excel数据导出 篇三:Access远程连接数据库和窗体打包部署 [小记]:最近基于WinForm+Access数据库 ...
- Java消息队列--JMS概述
1.什么是JMS JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送 ...
- [AlwaysOn Availability Groups]健康模型 Part 1——概述
健康模型概述 在成功部署AG之后,跟踪和维护健康状况是很重要的. 1.AG健康模型概述 AG的健康模型是基于策略管理(Policy Based Management PBM)的.如果不熟悉这个特性,可 ...
随机推荐
- JVM:Hotspot虚拟机中的对象
在HotSpot虚拟机中,对象在内存中存储的布局可以被分为3个区域:对象头(Header).实例数据(Instance data)和对齐填充(Padding).对象头包括两部分信息,第一部分存储自身的 ...
- Vue面试题01
说出vue常用的指令: v-text, v-html, v-bind, v-for, v-if, v-else, v-else-if, v-show, v-on, 谈谈你对MVC ...
- 设计模式学习-使用go实现单例模式
单例模式 定义 优点 缺点 适用范围 代码实现 懒汉模式 饿汉模式 双重检测 sync.Once 参考 单例模式 定义 什么是单例模式:保证一个类仅有一个实例,并提供一个全局访问它的全局访问点. 例如 ...
- The art of multipropcessor programming 读书笔记-3. 自旋锁与争用(2)
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现.并根据个人的查资料以 ...
- 微服务之十四如何在 Ocelot 网关中配置多实例 Swagger 访问
一.介绍 当我们开发基于微服务的应用程序的时候,有一个环节总是跳不过去的,那就是要创建 WebApi,然后,我们的应用程序基于 WebApi 接口去访问.在没有 Swagger 以前,我们开发好了 W ...
- Iceberg概述
背景 随着大数据领域的不断发展, 越来越多的概念被提出并应用到生产中而数据湖概念就是其中之一, 其概念参照阿里云的简介: 数据湖是一个集中式存储库, 可存储任意规模结构化和非结构化数据, 支持大数据和 ...
- ArrayList 源码分析和自定义ArrayList实现
概述 ArrayList 是基于数组实现的,是一个能自动扩展的动态数组. ArrayList 是线程不安全的,多线程情况下添加元素会出现数组越界的情况,而且数组赋值操作不是原子操作,会导致多线程情况下 ...
- 『学了就忘』Linux基础命令 — 38、Linux中光盘的挂载
目录 步骤一:创建一个空目录 步骤二:找到光盘的设备文件名称 步骤三:挂载光盘 步骤四:访问关盘中的数据 步骤五:卸载挂载点 问题:挂载点为什么要使用空目录 提示:关于Linux系统中光盘的挂载,我们 ...
- Java学习(十一)
今天学习了this和static关键字,这两个都是c++中学过的,但讲师还是讲了2个小时... 学得东西大部分都知道吧. this是当前对象的地址,类中带有static的方法不能使用this. 类中带 ...
- Typora下载安装教程
Typoa下载和安装 Typora---程序员记事本!!! 这里我们选择Typora作为我们的编辑器,功能的强大需要各位自己去体会. Typora下载地址 点击链接打开,然后选择Download! 根 ...