Table.NestedJoin合并…Join(Power Query 之 M 语言)
数据源:
“销量表”和“部门表”两个查找表,每个表中都有“姓名”列
目标:
根据“姓名列”将“部门表”中对应的部门合并到“销量表”中。
操作过程:
选取“销量表”》【主页】》【合并查询】/【将查询合并为新查询】》选取“部门表”》选取匹配列》【确定】
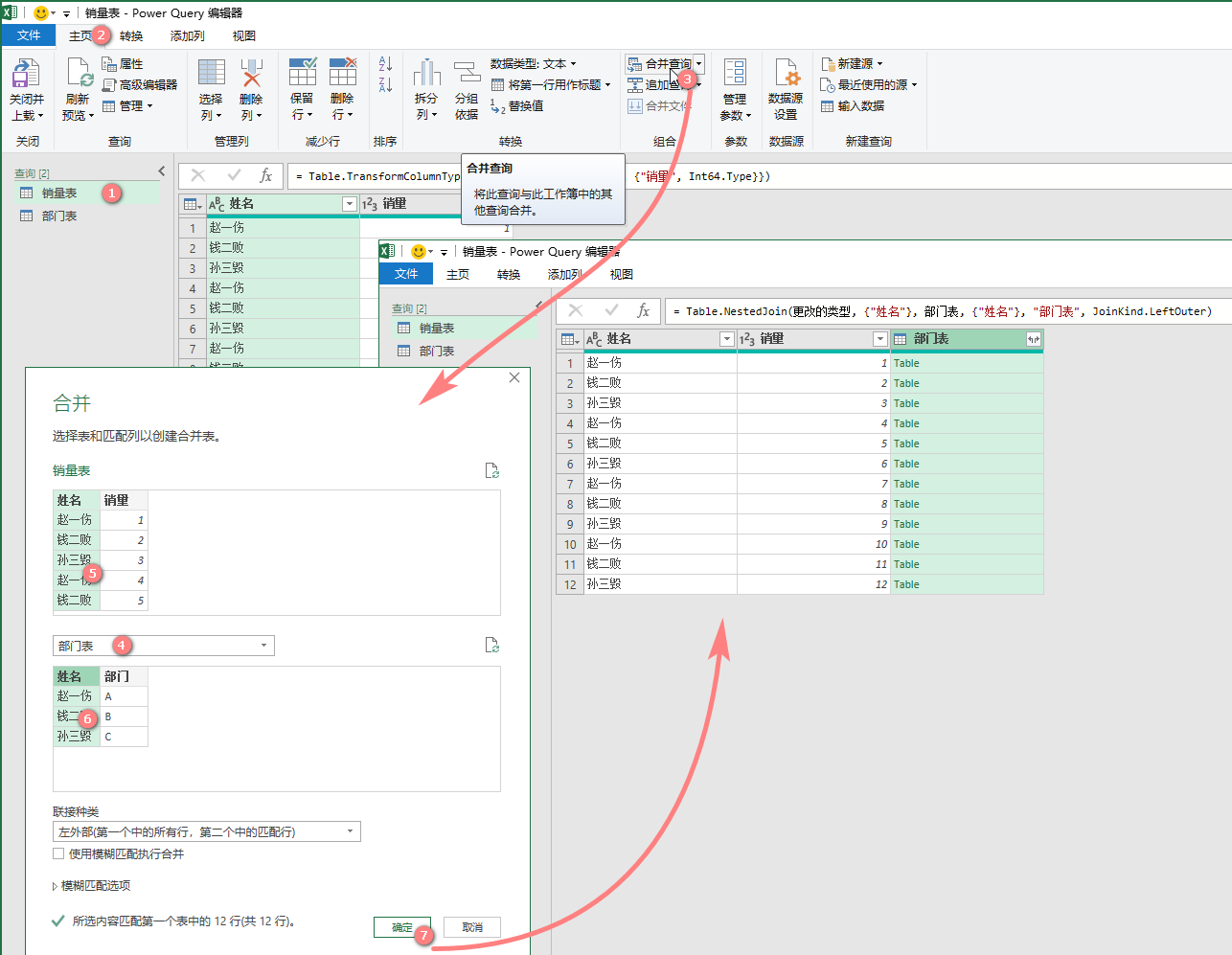
M公式:
= Table.NestedJoin( 表1, {"表1匹配列1",...,"表1匹配列n"}, 表2, {"表2匹配列1",...,"表2匹配表n"}, "新列名", 匹配函数)
匹配函数:
JoinKind.LeftOuter / 1 / 缺省:左外部
JoinKind.RightOuter / 2:右外部
JoinKind.FullOuter /3:完全外部
JoinKind.Inner / 0:内部
JoinKind.LeftAnti / 4:左反
JoinKind.RightAnti / 5:右反
JoinSide.Left:相当于内部的效果
JoinSide.Right:相当于左外部的效果
扩展:
左外部合并查询
= Table.AddJoinColumn( 表1, {"表1匹配列1",...,"表1匹配列n"}, 表2, {"表2匹配列1",...,"表2匹配表n"}, "新列名")
模糊匹配的合并查询
= Table.FuzzyNestedJoin( 表1, {"表1匹配列1",...,"表1匹配列n"}, 表2, {"表2匹配列1",...,"表2匹配表n"}, "新列名", 匹配函数, 匹配选项)
匹配选项:[IgnoreCase=true / false, IgnoreSpace=true / false, NumberOfMatches=数字, Threshold=0到1之间的数字, TransformationTable=表名]
IgnoreCase:区分大小写
IgnoreSpace:忽略空格
NumberOfMatches:指定可为每个输入行返回的最大匹配行数
Threshold:指定两个值将按其进行匹配的相似性分数。
TransformationTable:允许根据自定义值映射来匹配记录的表
一步到位的合并查询
= Table.Join( 表1, {"表1匹配列1",...,"表1匹配列n"}, 表2, {"表2匹配列1",...,"表2匹配表n"}, 匹配函数)
各表匹配列名不重复时才可加上匹配函数
一步到位的模糊匹配合并查询
= Table.FuzzyJoin( 表1, {"表1匹配列1",...,"表1匹配列n"}, 表2, {"表2匹配列1",...,"表2匹配表n"}, 匹配函数, 匹配选项)
Table.NestedJoin合并…Join(Power Query 之 M 语言)的更多相关文章
- M函数目录(Power Query 之 M 语言)
2021-12-11更新 主页(选项卡) 管理列(组) 选择列 选择列Table.SelectColumns 删除列 删除列Table.RemoveColumns 删除其他列Table.SelectC ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- 自定义函数(Power Query 之 M 语言)
数据源: 任意工作簿 目标: 使用自定义函数实现将数据源导入Power Query编辑器 操作过程: PowerQuery编辑器>主页>新建源>其他源>空查询 编辑栏内写入公式 ...
- M语言的写、改、删(Power Query 之 M 语言)
M语言基本上和其他语言一样,用敲键盘的方式写入.修改.删除,这个是废话. M语言可以在[编辑栏]或[高级编辑器]里直接写入.修改.删除,这个也是废话. M语言还有个地方可以写入.修改.删除,就是[自定 ...
- M语言的藏身之地(Power Query 之 M 语言)
M函数和M公式是Power Query专用的函数与公式,M代码是Power Query专用的用于实现查询功能的代码.M函数公式和M代码统称M语言. 查看M公式:[编辑栏] 查看方法:在Power Qu ...
- Table.CombineColumns合并…Combine…(Power Query 之 M 语言)
数据源: 任意表,表中列数超过两列 目标: 其中两列合并为一列 操作过程: 选取两列>[转换]>[合并列]>选取或输入分隔符>输入新列名>[确定] M公式: = T ...
- Table.Skip删除前面N….Skip/RemoveFirstN(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.Combine追加…Combine(Power Query 之 M 语言)
数据源: 销量表和部门表 目标: 其中一表的数据追加到另一表后面,相同列直接追加,不同列增加新列 操作过程: 选取销量表>[主页]>[追加查询]/[将查询追加为新查询]>选择要追加的 ...
- Table.ReorderColumns移动…Reorder…(Power Query 之 M 语言)
数据源: 至少两列 目标: 列顺序重新排列 操作过程: 选取待移动的列>鼠标拖放列标题 选取待移动的列>[转换]>[移动]>选取 M公式: = Table.ReorderCo ...
随机推荐
- 【.NET 与树莓派】MPD 的 Mini-API 封装
在前面的水文中,一方面,老周向各位同学介绍了通过 TCP 连接来访问 MPD 服务:另一方面,也简单演示了 ASP.NET Core 的"极简 API"(Mini API).本篇老 ...
- 洛谷 P7323 - [WC2021] 括号路径(启发式合并)
题面传送门 emmmm----怎么评价这个题嘛...感觉纯论算法,此题根本谈不上难题,不过 WC 时候太智障只拿了个 48pts 就走人了.总之,技不如人,甘拜吓疯( 首先要注意到几件事情: 如果 \ ...
- 洛谷 P3750 - [六省联考2017]分手是祝愿(期望 dp)
题面传送门 首先我们需注意到这样一个性质:那就是对于任何一种状态,将其变为全 \(0\) 所用的最小步数的方案是唯一的--考虑编号为 \(n\) 的灯,显然如果它原本是暗着的就不用管它了,如果它是亮着 ...
- 决策单调性&wqs二分
其实是一个还算 trivial 的知识点吧--早在 2019 年我就接触过了,然鹅当时由于没认真学并没有把自己学懂,故今复学之( 1. 决策单调性 引入:在求解 DP 问题的过程中我们常常遇到这样的问 ...
- C语言小练习 微型学生管理系统
很简陋,没有做输入校验,以写出来为第一目的,中间出了不少问题,尤其是结构体内字符串赋值的时候(理解不透彻),字符串比较用strcmp不能直接==判定,逻辑也很重要,不然会出现莫名其妙的问题. 涉及知识 ...
- 半主机模式和_MICROLIB 库
半主机是这么一种机制,它使得在ARM目标上跑的代码,如果主机电脑运行了调试器,那么该代码可以使用该主机电脑的输入输出设备. 这点非常重要,因为开发初期,可能开发者根本不知道该 ARM 器件上有什么 ...
- Mysql索引数据结构详解(1)
慢查询解决:使用索引 索引是帮助Mysql高效获取数据的排好序的数据结构 常见的存储数据结构: 二叉树 二叉树不适合单边增长的数据 红黑树(又称二叉平衡树) 红黑树会自动平衡父节点两边的 ...
- Java、Scala类型检查和类型转换
目录 Java 1.类型检查 2.类型转换 Scala 1.类型检查 2.类型转换 Java 1.类型检查 使用:变量 instanceof 类型 示例 String name = "zha ...
- d3 CSS
CSS的inline.block与inline-block 块级元素(block):独占一行,对宽高的属性值生效:如果不给宽度,块级元素就默认为浏览器的宽度,即就是100%宽. 行内元素(inline ...
- lambda表达式快速创建
Java 8十个lambda表达式案例 1. 实现Runnable线程案例 使用() -> {} 替代匿名类: //Before Java 8: new Thread(new Runnable( ...