CentOS:操作系统级监控及常用计数器解析
我相信有一些人看到这篇文章的标题肯定有种不想看的感觉,因为这样的内容实在被写得太多太多了。操作系统分析嘛,无非就是 CPU 使用率、I/O 使用率、内存使用率、网络使用率等各种使用率的描述。
然而因为视角的不同,在性能测试和分析中,这始终是我们绕不过去的分析点。我们得知道什么时候才需要去分析操作系统,以及要分析操作系统的什么内容。
首先,我们前面在性能分析方法中提到,性能分析要有起点,通常情况下,这个起点就是响应时间、TPS 等压力工具给出来的信息。
我们判断了有瓶颈之后,通过拆分响应时间就可以知道在哪个环节上出了问题,再去详细分析这个操作系统。这就需要用到我们的分析决策树了。
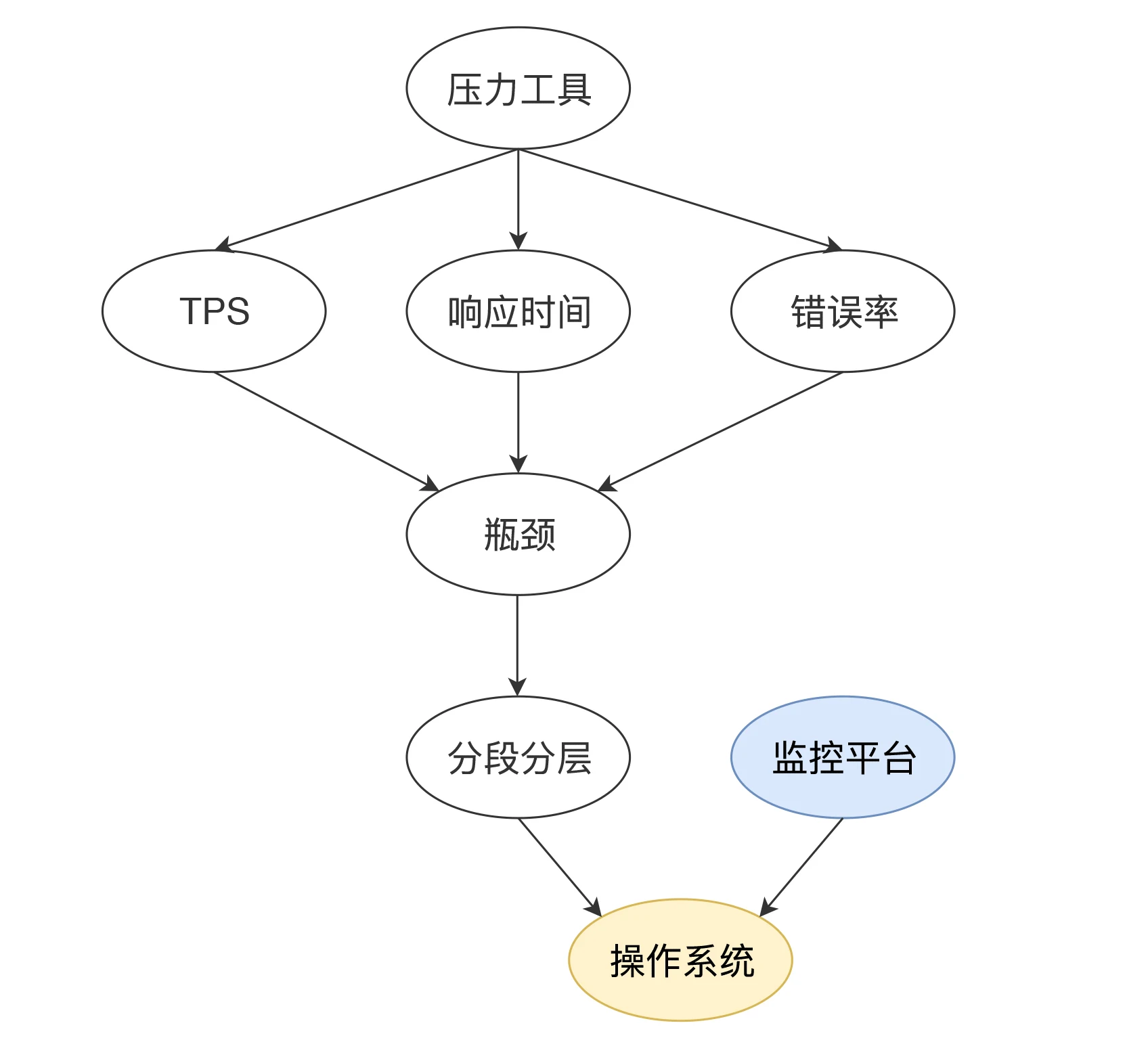
在分段分层确定了这个系统所运行的应用有问题之后,还要记起另一件事情,就是前面提到的“全局—定向”的监控思路。
既然说到了全局,我们得先知道操作系统中,都有哪些大的模块。这里就到了几乎所有性能测试人员看到就想吐的模块了,CPU、I/O、Memory、Network…
没办法,谁让操作系统就这么点东西呢。我先画一个思维导图给你看一下。
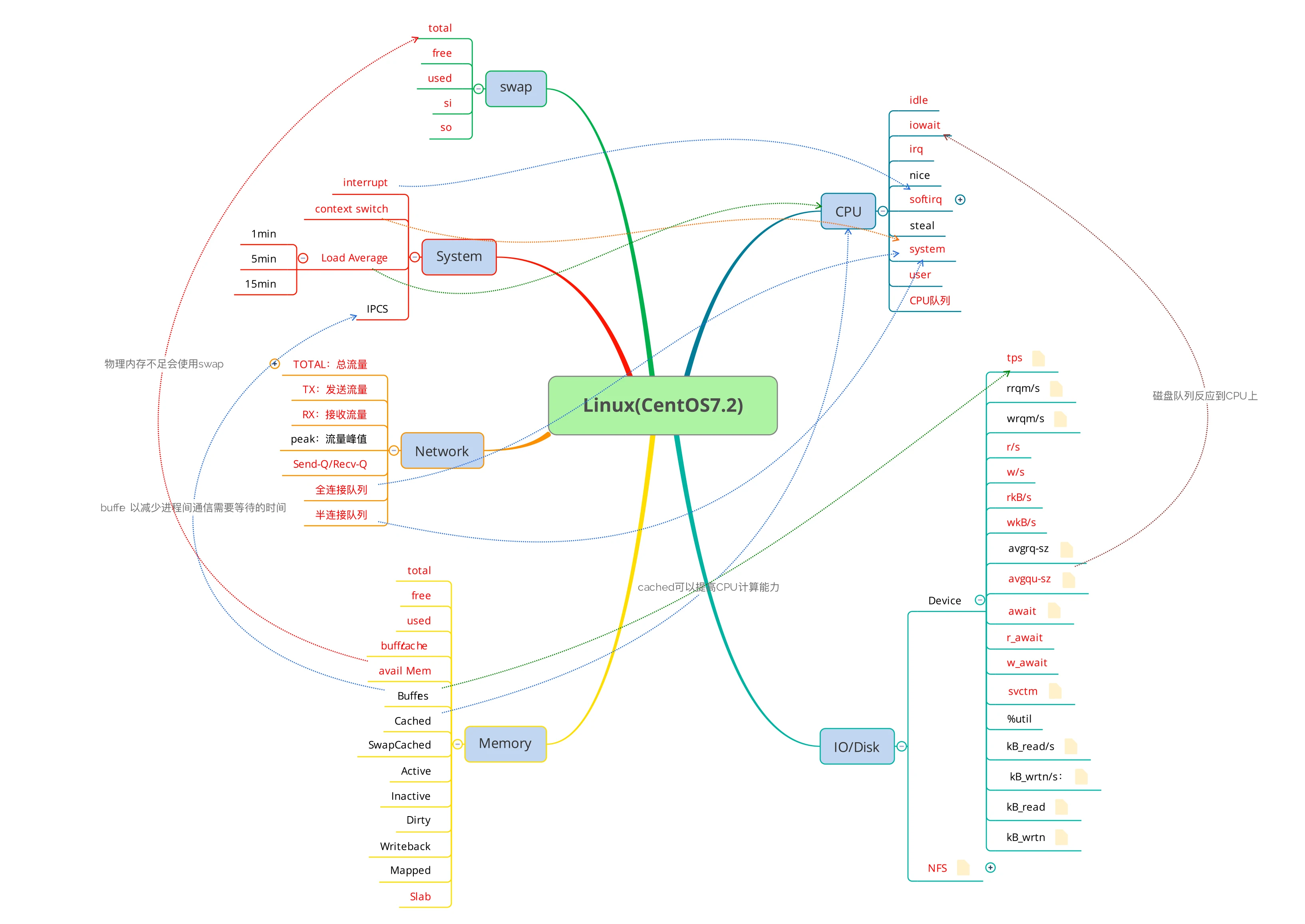
我很努力地把一些常见指标的相应关系都画到了图中,你是不是已经看晕了?看晕就对了,别着急。我们先要知道的是,面对这些大的模块,到底要用什么的监控手段来实现对它们的监控呢?
要知道,在一篇文章中不可能详尽地描述操作系统,我会尽量把我工作中经常使用到的一些和性能分析相关的、使用频度高的知识点整理给你。
监控命令
我们经常用到的 Linux 监控命令大概有这些:top、atop、vmstat、iostat、iotop、dstat、sar等……
请你注意我这里列的监控命令是指可以监控到相应模块的计数器,而不是说只能监控这个模块,因为大部分命令都是综合的工具集。
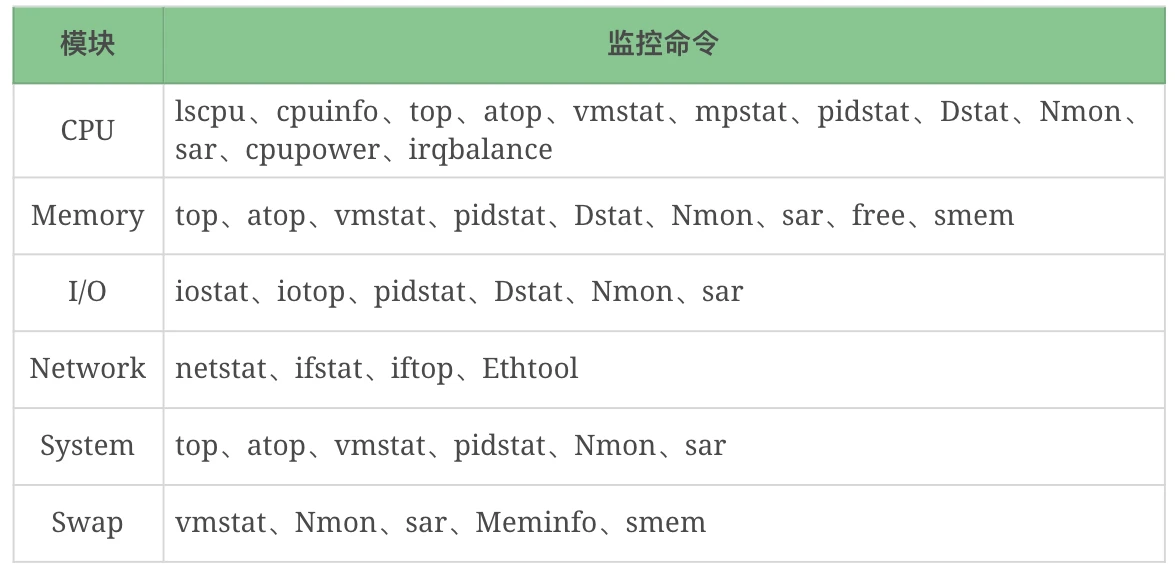
像这样的监控工具还能列上一堆,但这并不是关键,关键的是我们在什么时候能想起来用这些工具,以及知道这些工具的局限性。
比如说 top,它能看 CPU、内存、Swap、线程列表等信息,也可以把 I/O 算进去,因为它有 CPU 的 wa 计数器,但是它看不了 Disk 和 Network,这就是明显的局限性。之后出现的atop对很多内容做了整理,有了 Disk 和 Net 信息,但是呢,在一些 Linux 发行版中又不是默认安装的。vmstat呢?它能看 CPU、内存、队列、Disk、System、Swap 等信息,但是它又看不了线程列表和网络信息。
像这样的局限,我还能说上两千字。当工具让你眼花缭乱的时候,不要忘记最初的目标,我们要监控的是这几大模块:CPU、I/O、Memory、Network、System、Swap。
然后,我们再来对应前面提到的“全局—定向”监控的思路。如果你现在仅用命令来监控这个系统,你要执行哪几个呢?
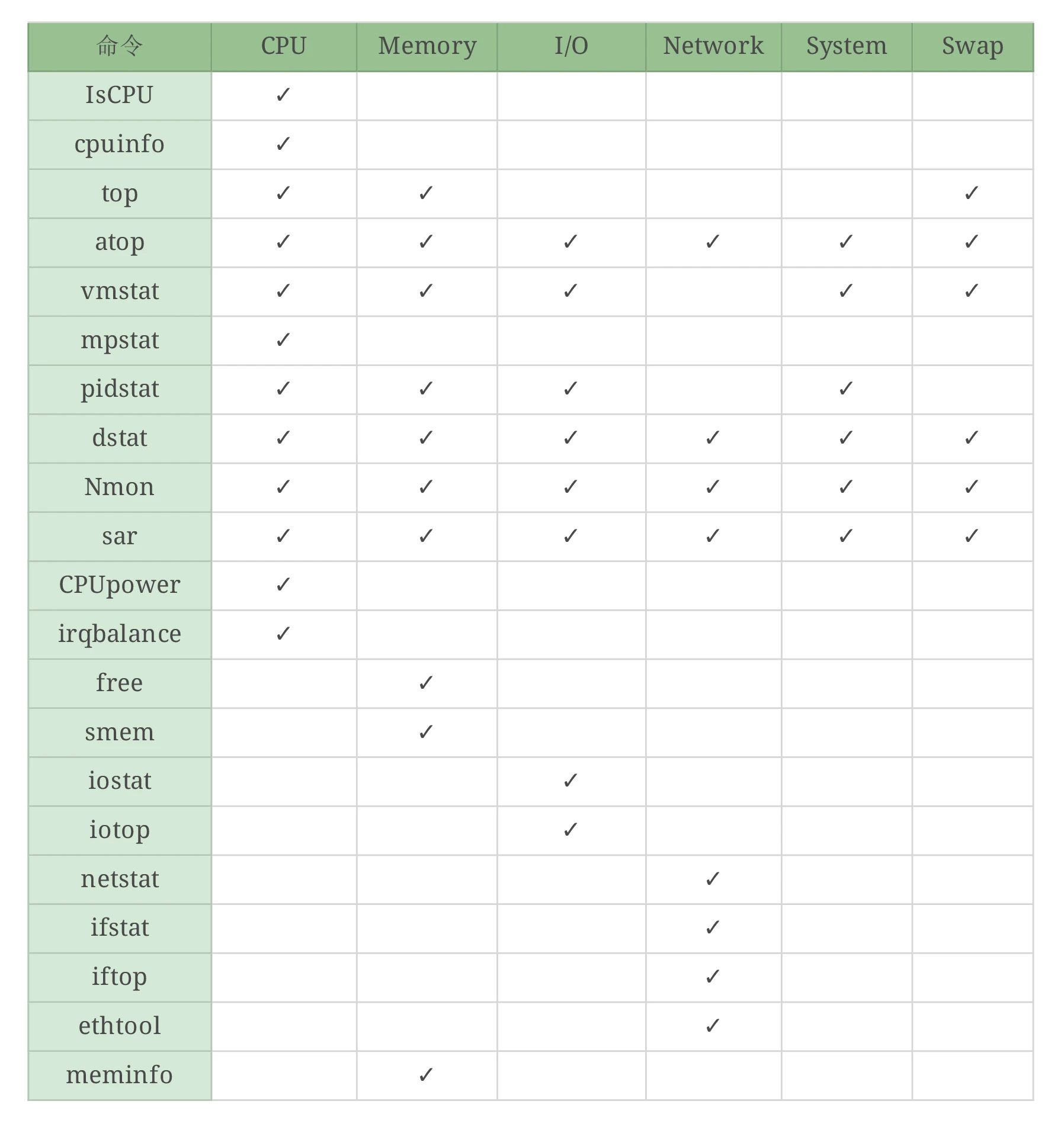
对应文章前面的思维导图,我们做一个细致的表格。
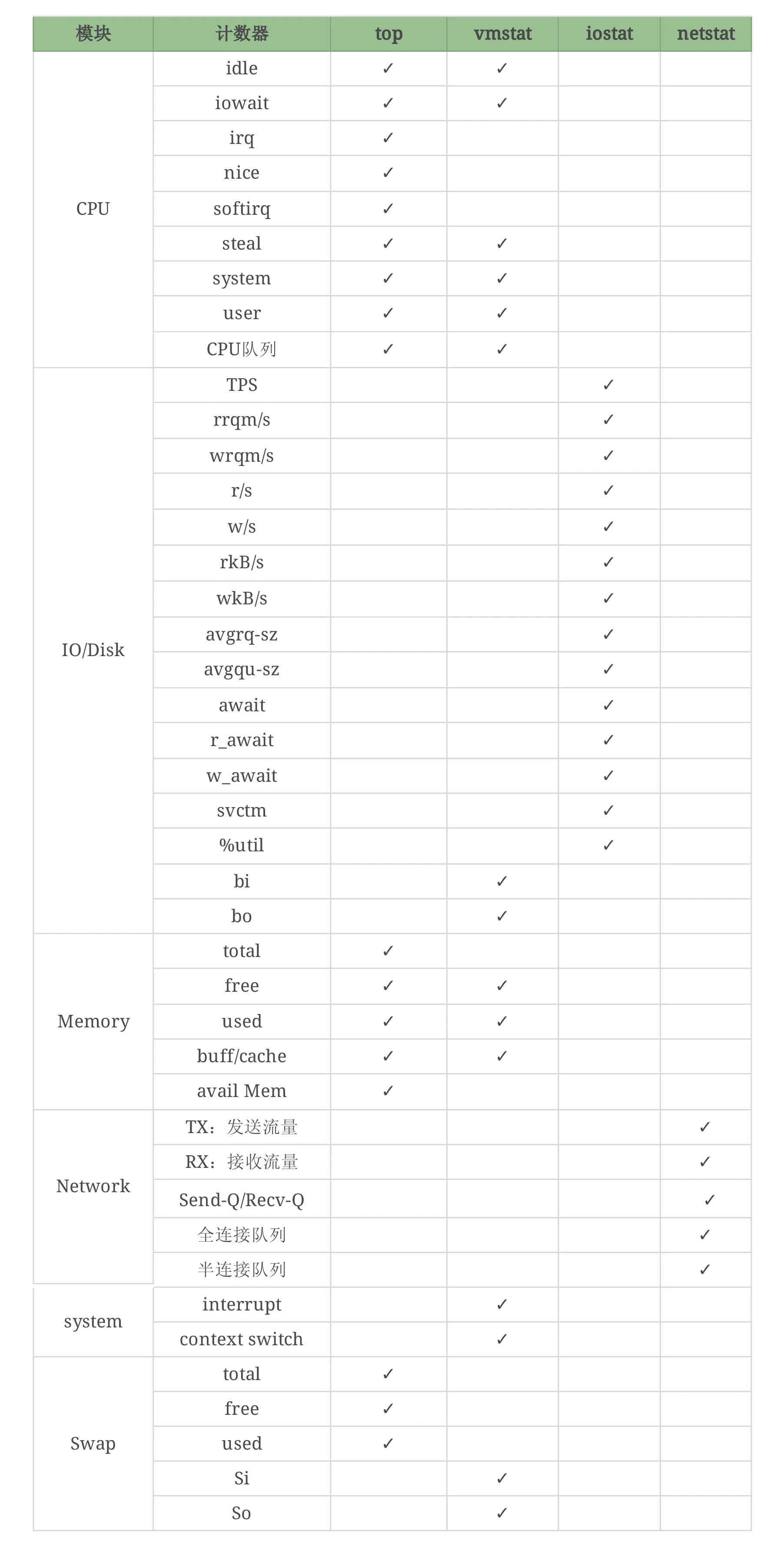
你会发现,vmstat可以看 Swap,但它能看的是si和so,看不到其他的计数器,但是top可以看到这些计数器……像这样的细节还有很多。
因为计数器非常多,又不是每个都常用。但是万一某个时候就需要用了呢?这个时候如果你不知道的话,就无法继续分析下去。
这里我主要想告诉你什么呢?就是用命令的时候,你要知道这个命令能干什么,不能干什么。你可能会说,有这些么多的计数器,还有这么多的命令,光学个 OS 我得学到啥时候去?
我要告诉你的是监控的思考逻辑。你要知道的是,正是因为你要监控 CPU 的某个计数器才执行了这个命令,而不是因为自己知道这个命令才去执行。这个关系我们一定要搞清楚。
那么逻辑就是这样的:

比如说,我想看下 OS 各模块的性能表现,所以执行 top 这个命令看了一些计数器,同时我又知道,网络的信息在top中是看不到的,所以我要把 OS 大模块看完,还要用netstat看网络,以此类推。
如果你还是觉得这样不能直接刺激到你的神经,懵懂不知道看哪些命令。那么在这里,我用上面的工具给你做一个表格。
命令模块对照表:
有了这些命令垫底之后,下面我们来看常用的监控平台。
监控平台 Grafana+Prometheus+node_exporter
这是现在用得比较多的监控平台了。在微服务时代,再加上 Kubernetes+Docker 的盛行,这个监控套装几乎是干 IT 的都知道。我们来看一下常用的 Dashboard。
为了理解上的通用性,我这里都用默认的信息,不用自己定制的。Grafana.com 官方 ID:8919 的模板内容如下:
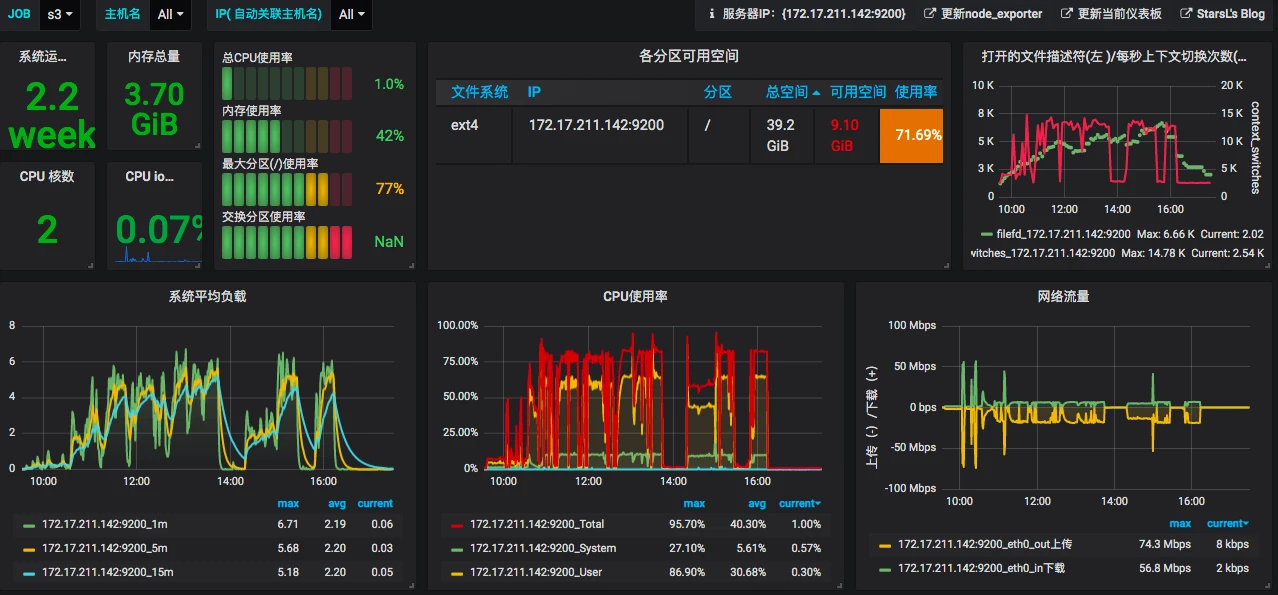
还记得我们要看系统的模块是哪几个吗?
- CPU
- Memory
- I/O
- Network
- System
- Swap
你可以自己对一下,是不是大模块都没有漏掉?确实没有。但是!上面的计数器你得理解。
我们先来看一下 CPU。
上图中有了 System、User、I/O Wait、Total,还记得我们上面说 top 里有 8 个 CPU 计数器吧,这里就 4 个怎么办?
Total 这个值的计算方式是这样的:
1 - avg(irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[30m])) by (instance)
也就是说,它包括除了空闲 CPU 的其他所有 CPU 使用率,这其实就有 ni、hi、si、st、guest、gnice 的值。当我们在这个图中看到 System、User、I/O Wait 都不高时,如果 Total 很高,那就是 ni、hi、si、st、guest、gnice 计数器中的某个值大了。这时你要想找问题,就得自己执行命令查看了。
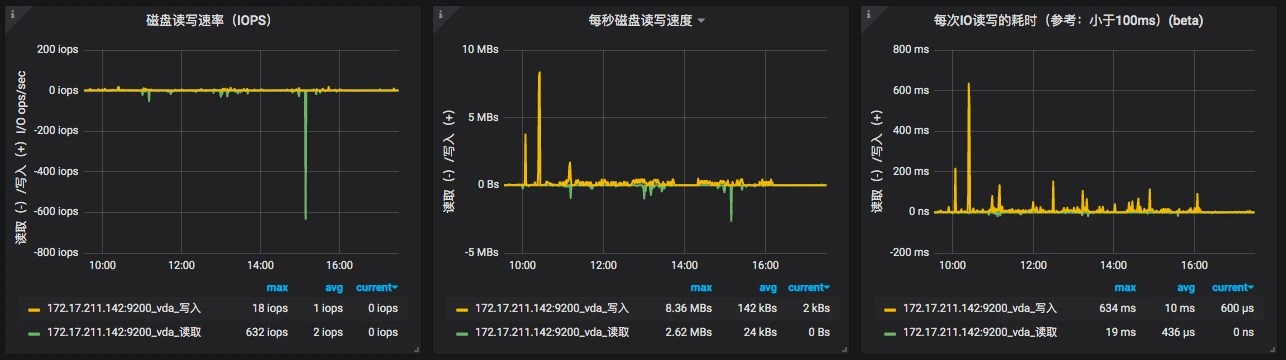
看完 CPU 之后,再看一下 Network。
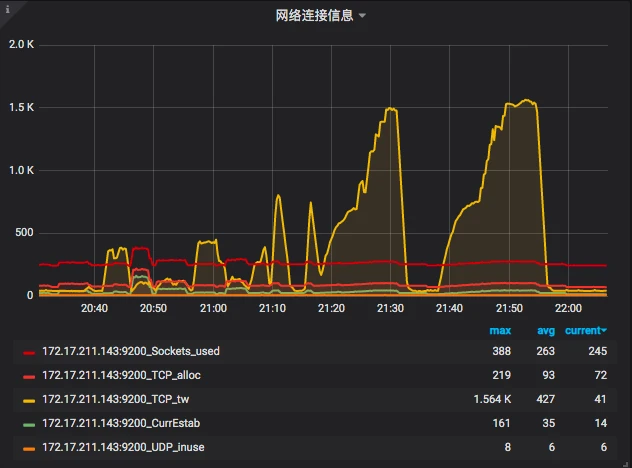
上图中有网络流量图。可以看到只有“上传下载”,这个值似乎容易理解,但是不够细致。node_exportor 还提供了一个“网络连接信息”图。可以看到 Sockets_used、CurrEstab、TCP_alloc、TCP_tw、UDP_inuse 这些值,它们所代表的含义如下:
- Sockets_used:已使用的所有协议套接字总量
- CurrEstab:当前状态为 ESTABLISHED 或 CLOSE-WAIT 的 TCP 连接数
- TCP_alloc:已分配(已建立、已申请到 sk_buff)的 TCP 套接字数量
- TCP_tw:等待关闭的 TCP 连接数
- UDP_inuse:正在使用的 UDP 套接字数量
这些值也可以通过查看“cat /proc/net/sockstat”知道。这是监控工具套装给我们提供的便利,然后我们再来看下 Memory。
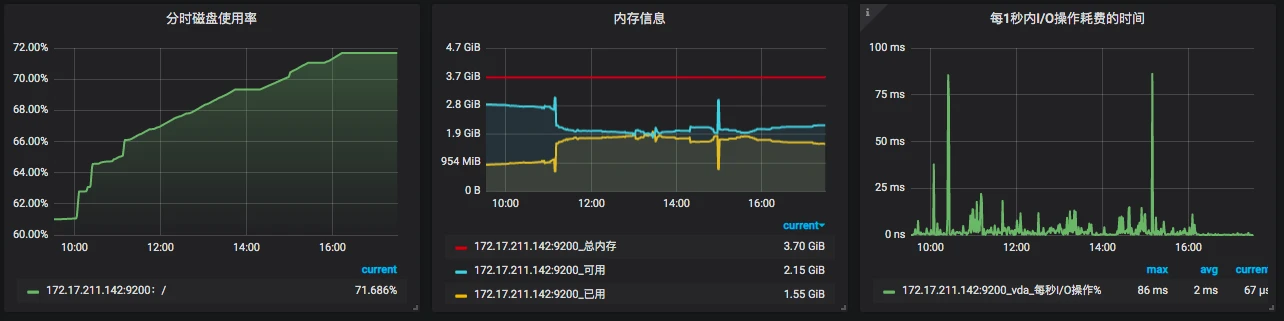
上图中有总内存、可用内存、已用内存这三个值。如果从应用的角度来看,我们现在对内存的分析,就要和语言相关了。像 Java 语言,一般会去分析 JVM。我们对操作系统的物理内存的使用并不关注,在大部分场景下物理内存并没有成为我们的瓶颈点,但这并不是说在内存上就没有调优的空间了。
关于内存这一块,我不想展开太多。因为展开之后内容太多了,如果你有兴趣的话,可以找内存管理的资料来看看。其他几个模块我就不再一一列了,I/O、System、Swap 也都是有监控数据的。
从全局监控的角度上看,这些计数器也基本够看。但是对于做性能分析、定位瓶颈来说,这些值显然是不够的。
还记得我在前面提到的“先全局监控再定向监控”找证据链的理念吧。像 node_exporter 这样的监控套装给我们提供的就是全局监控的数据,就是大面上覆盖了,细节上仍然不够。那怎么办呢?
下面我就来一一拆解一下。
CPU
CentOS:操作系统级监控及常用计数器解析的更多相关文章
- CentOS:操作系统级监控及常用计数器解析---除CPU以外
I/O I/O 其实是挺复杂的一个逻辑,但我们今天只说在做性能分析的时候,应该如何定位问题. 对性能优化比较有经验的人(或者说见过世面比较多的人)都会知道,当一个系统调到非常精致的程度时,基本上会卡在 ...
- 互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
上篇博文中,我们介绍了做互联网级监控系统的必备-Influxdb的关键特性.数据读写.应用场景: 互联网级监控系统必备-时序数据库之Influxdb 本文中,我们介绍Influxdb数据库集群的搭建, ...
- Apache入门 篇(二)之apache 2.2.x常用配置解析
一.httpd 2.2.x目录结构 Cnetos 6.10 YUM安装httpd 2.2.x # yum install -y httpd 程序环境 主配置文件: /etc/httpd/conf/ht ...
- linux 操作系统级别监控 TOP命令
Top命令是Linux下一个实时的.交互式的,对操作系统整体监控的命令,可以对CPU.内存.进程监控. 是Linux下最常用的监控命令. 第一行是任务队列信息 1 user 当前登录用户数load a ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- CentOS 配置OOM监控报警
由于程序设计不合理或者瞬间高并发访问时,很有可能会触发OOM(Out of memory),这里指的是操作系统级别的OOM.具体什么是OOM,以及怎样发生这里不在赘述,因为笔者认为这是IT从业工作者的 ...
- 安装Linux的CentOS操作系统 - 初学者系列 - 学习者系列文章
Linux系统对于一些熟悉Windows操作系统的用户来说可能比较陌生,但是它也是一种多用户.多任务的操作系统,现在也发展成为了多种版本的操作系统了.如果想对该系统进行学习,请下载这个学习文档:htt ...
- python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器 ...
- Ext 常用组件解析
Ext 常用组件解析 Panel 定义&常用属性 //1.使用initComponent Ext.define('MySecurity.view.resource.ResourcePanel' ...
随机推荐
- URL分发器(视图层)
目录 视图 URL映射 path函数 URL中传入参数 普通传入参数 变量形式传入参数 URL中包含另一个urls模块 URL命名.URL反转.应用命名空间 视图 视图一般都写在 app 的 vi ...
- Redis数据结构—链表与字典的结构
目录 Redis数据结构-链表与字典的结构 链表 Redis链表节点的结构 Redis链表的表示 Redis链表用在哪 字典 Redis字典结构总览 Redis字典结构分解 Redis字典的使用 Re ...
- 【opencv】获取摄像头rstp视频流地址方法
1.rstp通用地址格式为 : 通用格式 // user : 登录摄像头的用户名 // password:登录摄像头的密码 // ip:摄像头的ip地址 // port:端口号,常用的为554 &qu ...
- L SERVER 数据库被标记为“可疑”的解决办法
问题背景: 日常对Sql Server 2005关系数据库进行操作时,有时对数据库(如:Sharepoint网站配置数据库名Sharepoint_Config)进行些不正常操作如数据库在读写时而无故停 ...
- Python数模笔记-Sklearn(4)线性回归
1.什么是线性回归? 回归分析(Regression analysis)是一种统计分析方法,研究自变量和因变量之间的定量关系.回归分析不仅包括建立数学模型并估计模型参数,检验数学模型的可信度,也包括利 ...
- 笔记·RCNN系相关
这篇博客总述了从RCNN到Mask RCNN的发展过程 https://blog.csdn.net/heavenpeien/article/details/80534963 简单的说,Fast RCN ...
- HUGO 创建属于自己的博客
Hugo 拥有超快的速度,强大的内容管理和强大的模板语言,使其非常适合各种静态网站.可以轻松安装在macOS,Linux,Windows等平台上,在开发过程中使用LiveReload可即时渲染更改 一 ...
- Objective-C 中不带加减号的方法
显而易见的事实是,Objective-C 中,+ 表示类方法,- 表示实例方法. 但看别人代码过程中,还会发现一种,不带加减号的方法. @implementation MyViewController ...
- [算法] 单链表插入排序(java)
实现 首先保证插入前的链表是个完整的,最后一个节点要断开 然后在插入前链表中找到比待插入节点大的最小元素,插到前面即可 Link.java class Link { private class Nod ...
- [刷题] 206 Reverse Linked List
要求 反转一个链表 不得改变节点的值 示例 head->1->2->3->4->5->NULL NULL<-1<-2<-3<-4<-5 ...