Hadoop之倒排索引
前言:
从IT跨度到DT,如今的数据每天都在海量的增长。面对如此巨大的数据,如何能让搜索引擎更好的工作呢?本文作为Hadoop系列的第二篇,将介绍分布式情况下搜索引擎的基础实现,即“倒排索引”。
1.问题描述
将所有不同文件里面的关键词进行存储,并实现快速检索。下面假设有3个文件的数据如下:
file1.txt:MapReduce is simple
file2.txt:mapReduce is powerful is simple
file3.txt:Hello MapReduce bye MapReduce
最终应生成如下索引结果:
Hello file3.txt:
MapReduce file3.txt:;file2.txt:;file1.txt:
bye file3.txt:
is file2.txt:;file1.txt:
powerful file2.txt:
simple file2.txt:;file1.txt:
--------------------------------------------------------
2.设计
首先,我们对读入的数据利用Map操作进行预处理,如图1:
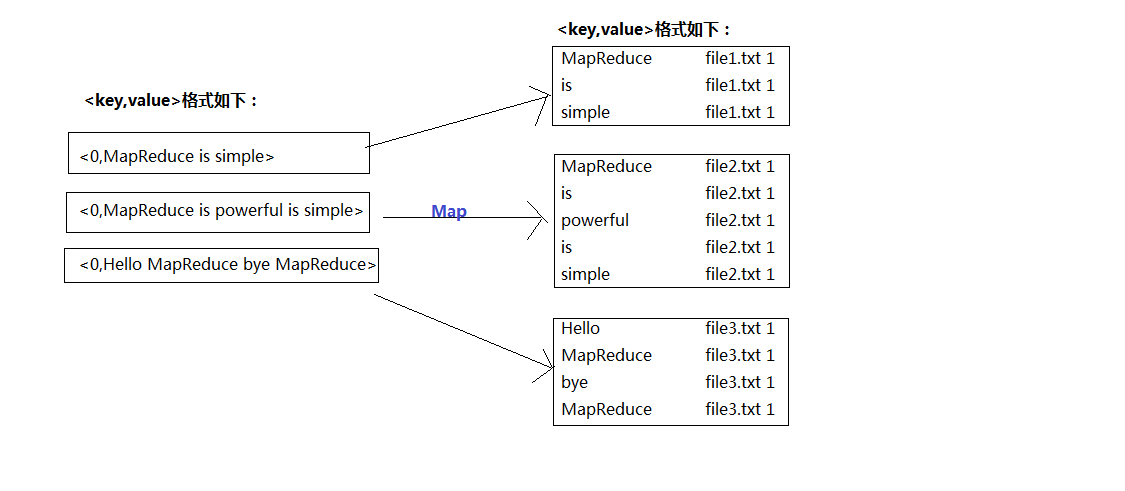
对比之前的单词计数(WorldCount.java),要实现倒排索引单靠Map和Reduce操作明显无法完成,因此中间我们加入'Combine',即合并操作;具体如图2: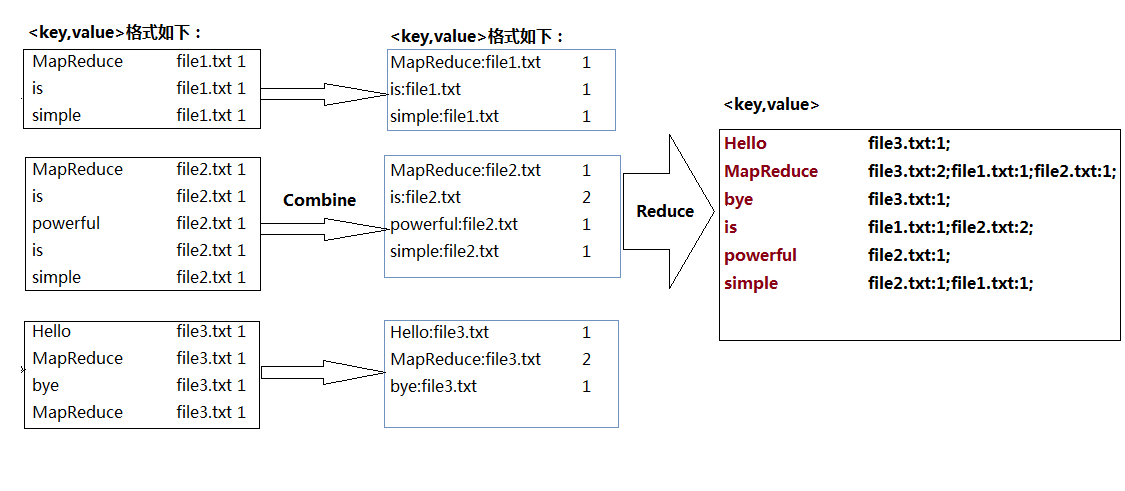
--------------------------------------------------------------
3.代码实现
package pro; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class InvertedIndex {
final static String INPUT_PATH = "hdfs://hadoop0:9000/index_in";
final static String OUTPUT_PATH = "hdfs://hadoop0:9000/index_out"; public static class Map extends Mapper<Object, Text, Text, Text> { private Text keyInfo = new Text(); // 存储单词和URL组合
private Text valueInfo = new Text(); // 存储词频
private FileSplit split; // 存储Split对象 // 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// 获得<key,value>对所属的FileSplit对象
split = (FileSplit) context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) { // 只获取文件的名称。
int splitIndex = split.getPath().toString().indexOf("file");
keyInfo.set(itr.nextToken() + ":"
+ split.getPath().toString().substring(splitIndex));
// 词频初始化为1
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
} public static class Combine extends Reducer<Text, Text, Text, Text> {
private Text info = new Text(); // 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 统计词频
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
} int splitIndex = key.toString().indexOf(":");
// 重新设置value值由URL和词频组成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新设置key值为单词
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
} public static class Reduce extends Reducer<Text, Text, Text, Text> {
private Text result = new Text(); // 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList); context.write(key, result);
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "Inverted Index");
job.setJarByClass(InvertedIndex.class); // 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class); // 设置Map输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); // 设置Reduce输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); // 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.测试结果
Hello file3.txt:1;
MapReduce file3.txt:2;file1.txt:1;file2.txt:1;
bye file3.txt:1;
is file1.txt:1;file2.txt:2;
powerful file2.txt:1;
simple file2.txt:1;file1.txt:1;
Reference:
[1]Hadoop权威指南【A】Tom Wbite
[2]深入云计算·Hadoop应用开发实战详解【A】万川梅 谢正兰
--------------
结语:
从上面的Map---> Combine ----> Reduce操作过程中,我们可以体会到“倒排索引”的过程其实也就是不断组合并拆分字符串的过程,而这也就是Hadoop中MapReduce并行计算的体现。在现今的大部分企业当中,Hadoop主要应用之一就是针对日志进行处理,所以想进军大数据领域的朋友,对于Hadoop的Map/Reduce实现原理可以通过更多的实战操作加深理解。本文仅仅只是牛刀小试,对于Hadoop的深层应用本人也正在慢慢摸索~~
Hadoop之倒排索引的更多相关文章
- hadoop实现倒排索引
hadoop实现倒排索引 本文用hadoop实现倒排索引算法,用基本的分两步完成,不使用combine 第一步 读入文档,统计文档中各个单词的个数,与word count类似,但这里把word-fil ...
- hadoop学习笔记之倒排索引
开发工具:eclipse 目标:对下面文档phone_numbers进行倒排索引: 13599999999 1008613899999999 12013944444444 13800138000137 ...
- hadoop倒排索引
1.前言 学习hadoop的童鞋,倒排索引这个算法还是挺重要的.这是以后展开工作的基础.首先,我们来认识下什么是倒拍索引: 倒排索引简单地就是:根据单词,返回它在哪个文件中出现过,而且频率是多少的结果 ...
- Hadoop 倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎.它主要是用来存储某个单词(或词组)在一个文档或一组文档中存储位置的映射,即提供了一种根据内容来查找文档的方式.由于不是根据文档来确 ...
- Hadoop学习笔记(8) ——实战 做个倒排索引
Hadoop学习笔记(8) ——实战 做个倒排索引 倒排索引是文档检索系统中最常用数据结构.根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index).结构如 ...
- Hadoop案例(四)倒排索引(多job串联)与全局计数器
一. 倒排索引(多job串联) 1. 需求分析 有大量的文本(文档.网页),需要建立搜索索引 xyg pingping xyg ss xyg ss a.txt xyg pingping xyg pin ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- Hadoop实战-MapReduce之倒排索引(八)
倒排索引 (就是key和Value对调的显示结果) 一.需求:下面是用户播放音乐记录,统计歌曲被哪些用户播放过 tom LittleApple jack YesterdayO ...
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
随机推荐
- WWDC 后苹果最新 App Store 审核条款!
WWDC 2016 大会之后,苹果公司发布了四个全新平台:iOS,macOS,watchOS 和 tvOS.并且在此之后,苹果应用商店审核条款也同时进行了更新——貌似不算进行了更新,简直就是重 ...
- 基于Ruby的watir-webdriver自动化测试方案与实施(一)
基于Ruby的watir-webdriver自动化测试方案与实施(五) 基于Ruby的watir-webdriver自动化测试方案与实施(四) 基于Ruby的watir-webdriver自动 ...
- Nginx反向代理和负载均衡部署指南
1. 安装 1) 从Nginx官网下载页面(http://nginx.org/en/download.html)下载Nginx最新版本(目前是1.5.13版本)安装包: ...
- MongoDB学习笔记~客户端命令行的使用
回到目录 当我们从MongoDB网站下载安装包之后,它会伴随有一系列的工具,服务器程序mongod是我们耳熟能详的了,客户端mongo和性能检测mongostat我们可能就没有用过了,今天主要是介绍一 ...
- mysql 安装问题
针对免安装版的mysql: 1.启动CMD,在mysql安装目录下 ~\bin\目录下,输入: mysqld -install 安装msyql服务: 2.启动MySQL服务,输入: net st ...
- [转]html超链接打开的窗口大小
<a href="#" onclick="javascript:window.open('http://www.baidu.com','','height=20,w ...
- [Django]数据批量导入
前言:历经一个月的复习,考试终于结束了.这期间上班的时候有研究了Django网页制作过程中,如何将数据批量导入到数据库中. 这个过程真的是惨不忍睹,犯了很多的低级错误,这会在正文中说到的.再者导入数据 ...
- sudo 命令情景分析
Linux 下使用 sudo 命令,可以让普通用户也能执行一些或者全部的 root 命令.本文就对我们常用到 sudo 操作情景进行简单分析,通过一些例子来了解 sudo 命令相关的技巧. 情景一:用 ...
- 【2016-11-2】【坚持学习】【Day17】【通过反射自动将datareader转为实体info】
通过ADO.net 查询到数据库的数据后,通过DataReader转为对象Info public class BaseInfo { /// <summary> /// 填充实体 /// & ...
- NOIP2010关押罪犯[并查集|二分答案+二分图染色 | 种类并查集]
题目描述 S 城现有两座监狱,一共关押着N 名罪犯,编号分别为1~N.他们之间的关系自然也极不和谐.很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突.我们用“怨气值”(一个正整数值)来表示 ...