使用 conda 和 Jupyter 在 R 中实现数据科学分析
前两篇文章我们介绍了 Jupyter Notebook 的一些基础用法,今天我们来介绍一下如何使用 conda 和 Jupyter 在 R 中开始一个数据科学项目。
在开始之前我们先要明确一个概念:Kernel,即内核。内核是以特定的编程语言运行交互式代码并将输出返回给用户的进程,基于 Kernel,Jupyter Notebook 可以支持包括 R、Python 在内的多种编程语言。由于 Jupyter Notebook 和 Kernel 是分开的,任何语言的代码都可以在它们之间发送。使用 R 内核,用 R 编写的代码将被发送到执行的 R 内核,与在 Python 内核上运行 Python 的代码道理是一样的。
创建 “R Essentials”
Anaconda 团队已经创建了一个 “R Essentials”把 IRKernel 和数据科学分析中最常用的超过 80 个 R 包捆绑在了一起,这些包包括:dplyr, shiny, ggplot2, tidyr, caret 和 nnet 。
“R Essentials” 的下载需要用到 conda。幸运的是,Miniconda 已经包含了 conda、Python 以及其他的一些必须包,而 Anaconda 则包含了 miniconda 的所有东西,以及用于科学,数学,工程和数据分析的 200多个最受欢迎的 Python 软件包。用户可以选择安装 Anaconda 一次安装所有的包;也可以先安装 Miniconda ,然后再使用 conda 命令安装他们需要的包(包括在 Anaconda 中的任何包)。
如果你已经拥有了 conda,你可以为当前环境安装 "R Essentials":
conda install -c r r-essentials
或者创建一个专门用于 “R essentials” 的新环境:
conda create -n my-r-env -c r r-essentials
Jupyter
Jupyter 提供了一个强大的笔记本交互界面来写你的分析,并与同行分享。打开一个 shell 并运行下面这个命令来启动浏览器中的 Jupyter 笔记本界面:
jupyter notebook
创建一个新的 R 笔记:
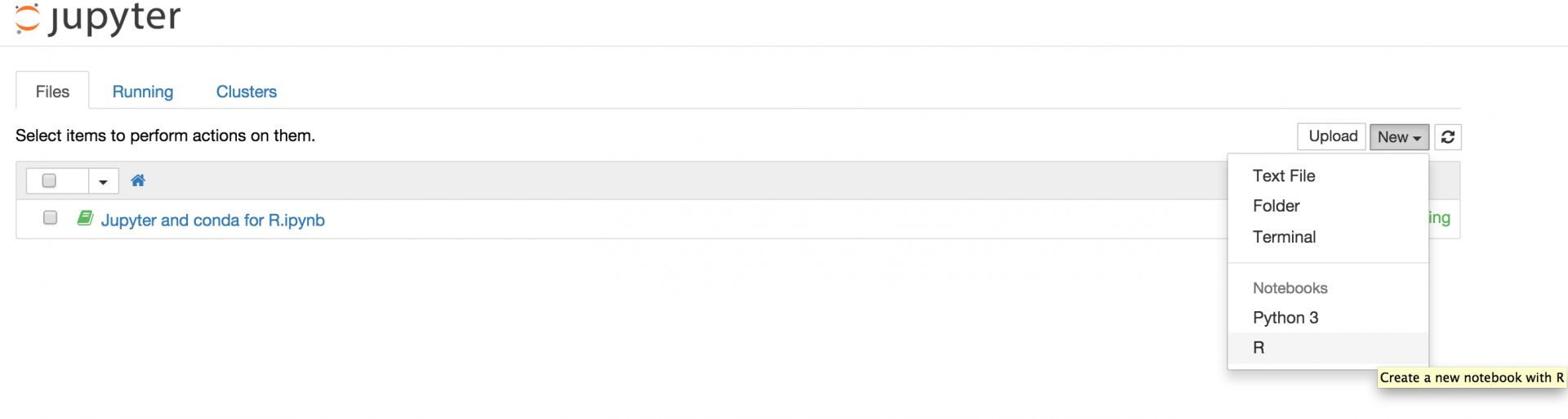
接下来,你就可以在 notebook cells 中编写和运行你的 R 代码了。
R 笔记示例
① 导入数据整理 R 包,dplyr:
In [1]: library(dplyr)
② 调用一个可用的数据集,如 iris:
In [2]: iris
Out[2]:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
...
③ 计算物种的平均萼片宽度
In [3]: iris %>%
group_by(Species) %>%
summarise(Sepal.Width.Avg = mean(Sepal.Width)) %>%
arrange(Sepal.Width.Avg)
Out [3]:
Species Sepal.Width.Avg
1 versicolor 2.77
2 virginica 2.974
3 setosa 3.428
④ 导入可视化 R 包 ggplot2:
In [4]: library(ggplot2)
⑤ 绘图 Sepal.Width vs. Sepal.Length:
In [5]: ggplot(data=iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) + geom_point(size=3)
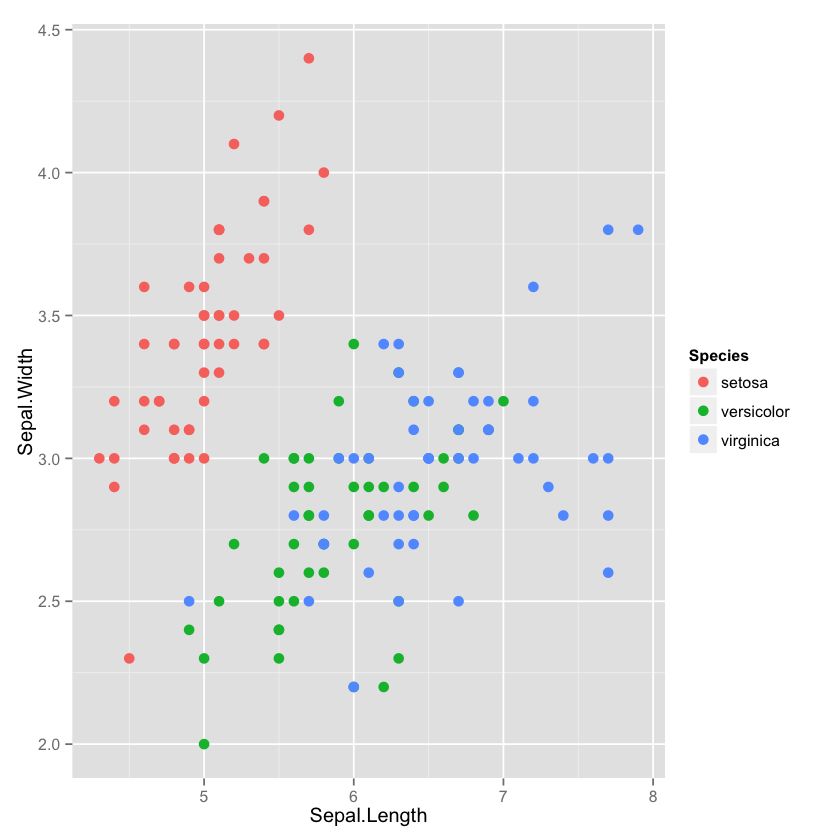
ok,今天就到这里。下一篇我们将会介绍如何使用 conda 创建我们的自定义的 R 集合包并上传与他人共享,以及介绍一下如何通过 Jupyter 把笔记转换为在线幻灯片,供讲座和教程使用。
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
使用 conda 和 Jupyter 在 R 中实现数据科学分析的更多相关文章
- 在R中整理数据
原始数据一般分散杂乱,并含有缺失和错误值,因此在进行数据分析前首先要对数据进行整理. 一.首先,了解原始数据的结构. 可使用如下函数(归属baseR)来查看数据结构: class(dataobject ...
- 如何使用Hive&R从Hadoop集群中提取数据进行分析
一个简单的例子! 环境:CentOS6.5 Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 1.分析题目 --有一个用户数据样本(表名huserinfo)10万数据左右: ...
- R中的数据重塑函数
1.去除重复数据 函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一 ...
- hive向表格中插入数据并分析语句
1,---导入mds_imei_month_info ; //最大的动态分区表 set hive.support.concurrency=false; //是否支持并发 ; //each mapper ...
- Ubuntu 18.04安装Conda、Jupyter Notebook、Anaconda
1.Conda是一个开源的软件包管理系统和环境管理系统,它可以作为单独的纯净工具安装在系统环境中,有的python库无法用conda获得时,conda允许在conda环境中利用Pip获取包文件.可以将 ...
- 第二篇:智能电网(Smart Grid)中的数据工程与大数据案例分析
前言 上篇文章中讲到,在智能电网的控制与管理侧中,数据的分析和挖掘.可视化等工作属于核心环节.除此之外,二次侧中需要对数据进行采集,数据共享平台的搭建显然也涉及到数据的管理.那么在智能电网领域中,数据 ...
- ROWID面试题-删除表中重复数据(重复数据保留一个)
/* ROWID是行ID,通过它一定可以定位到r任意一行的数据记录 ROWID DNAME DEPTNO LOC ------------------ ------------------------ ...
- (数据科学学习手札07)R在数据框操作上方法的总结(初级篇)
上篇我们了解了Python中pandas内封装的关于数据框的常用操作方法,而作为专为数据科学而生的一门语言,R在数据框的操作上则更为丰富精彩,本篇就R处理数据框的常用方法进行总结: 1.数据框的生成 ...
- 系统评价——数据包络分析DEA的R语言实现(七)
数据包络分析(Data envelopment analysis,DEA)是运筹学中用于测量决策部门生产效率的一种方法,它是基于相对效率发展的崭新的效率评估方法. 详细来说,通过使用数学规划模型,计算 ...
- 在centos 7 中 conda 环境和Python2.7 中安装远程jupyter
折腾了半天,为了能够方便学习TensorFlow,搞了远程的jupyter,方便在本地使用它,今天填了不少坑. 装完后截图: 下面是一些步骤: 检查 Python 环境 CentOS 7.2 中默认集 ...
随机推荐
- 主板芯片组驱动和Win系统版本互相关联
主板芯片组驱动和Win系统版本互相关联,过早的系统安装较新版的芯片组驱动,或者较新版本的操作系统安装旧版的芯片组驱动,都可能导致系统不稳定蓝屏.解决方案就是安装最新的芯片组驱动和最新版的操作系统.
- 谁能真正替代你?AI辅助编码工具深度对比(chatGPT/Copilot/Cursor/New Bing)
写在开头 这几个月AI相关新闻的火爆程度大家都已经看见了,作为一个被裹挟在AI时代浪潮中的程序员,在这几个月里我也是异常兴奋和焦虑.甚至都兴奋的不想拖更了.不仅仅兴奋于AI对于我们生产力的全面提升,也 ...
- 列表、sort、reverse、元组、字典、
1.列表是一种有序可变的容器.通过[]来标识 1)定义一个空列表list = [] 2.列表的添加 1)末尾添加append() list = ['张三',,'王五'] list.append('刘六 ...
- P6185 [NOI Online #1 提高组] 序列
给定两个长度为n的序列\(A\),\(B\). 有m个可用的操作\((t_i,u_i,v_i)\). \(t\)代表操作类型. 当\(t=1\)时,表示能够将\(A_{u_i}\)和\(A_{v_i} ...
- LeeCode链表问题(二)
LeeCode 19: 删除链表的倒数第n个节点 题目描述: 给你一个链表,删除链表的倒数第 n 个节点,并返回链表的头节点. 标签:链表,双指针 时间复杂度:O(N) 建立模型: 定义虚拟头节点,使 ...
- day47:Bootstrap
什么是Bootstrap? Bootstrap是一个开源框架,是对html\css\js\jquery等的封装,用法,复制黏贴一把梭. 关于Bootstrap的一些常用网址 网址: https://w ...
- java 回行矩阵的打印
n=3 n=4 1 2 3 1 2 3 4 8 9 4 12 13 14 5 7 6 5 11 16 15 6 10 9 ...
- JS 对输入框进行限制(常用的都有)
文章来源 http://www.soso.io/article/24096.html 1.文本框只能输入数字代码(小数点也不能输入) 代码如下: <input οnkeyup="thi ...
- 如何建设一个用于编译 iOS App 的 macOS 云服务器集群?
作者:京东零售 叶萌 现代软件开发一般会借助 CI/CD 来提升代码质量.加快发版速度.自动化重复的事情,iOS App 只能在 mac 机器上编译,CI/CD 工具因此需要有一个 macOS 云服务 ...
- Rust -- 模式与匹配
1. 模式 用来匹配类型中的结构(数据的形状),结合 模式和match表达式 提供程序控制流的支配权 模式组成内容 字面量 解构的数组.枚举.结构体.元祖 变量 通配符 占位符 流程:匹配值 --&g ...