使用 conda 和 Jupyter 在 R 中实现数据科学分析
前两篇文章我们介绍了 Jupyter Notebook 的一些基础用法,今天我们来介绍一下如何使用 conda 和 Jupyter 在 R 中开始一个数据科学项目。
在开始之前我们先要明确一个概念:Kernel,即内核。内核是以特定的编程语言运行交互式代码并将输出返回给用户的进程,基于 Kernel,Jupyter Notebook 可以支持包括 R、Python 在内的多种编程语言。由于 Jupyter Notebook 和 Kernel 是分开的,任何语言的代码都可以在它们之间发送。使用 R 内核,用 R 编写的代码将被发送到执行的 R 内核,与在 Python 内核上运行 Python 的代码道理是一样的。
创建 “R Essentials”
Anaconda 团队已经创建了一个 “R Essentials”把 IRKernel 和数据科学分析中最常用的超过 80 个 R 包捆绑在了一起,这些包包括:dplyr, shiny, ggplot2, tidyr, caret 和 nnet 。
“R Essentials” 的下载需要用到 conda。幸运的是,Miniconda 已经包含了 conda、Python 以及其他的一些必须包,而 Anaconda 则包含了 miniconda 的所有东西,以及用于科学,数学,工程和数据分析的 200多个最受欢迎的 Python 软件包。用户可以选择安装 Anaconda 一次安装所有的包;也可以先安装 Miniconda ,然后再使用 conda 命令安装他们需要的包(包括在 Anaconda 中的任何包)。
如果你已经拥有了 conda,你可以为当前环境安装 "R Essentials":
conda install -c r r-essentials
或者创建一个专门用于 “R essentials” 的新环境:
conda create -n my-r-env -c r r-essentials
Jupyter
Jupyter 提供了一个强大的笔记本交互界面来写你的分析,并与同行分享。打开一个 shell 并运行下面这个命令来启动浏览器中的 Jupyter 笔记本界面:
jupyter notebook
创建一个新的 R 笔记:
接下来,你就可以在 notebook cells 中编写和运行你的 R 代码了。
R 笔记示例
① 导入数据整理 R 包,dplyr:
In [1]: library(dplyr)
② 调用一个可用的数据集,如 iris:
In [2]: iris
Out[2]:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
...
③ 计算物种的平均萼片宽度
In [3]: iris %>%
group_by(Species) %>%
summarise(Sepal.Width.Avg = mean(Sepal.Width)) %>%
arrange(Sepal.Width.Avg)
Out [3]:
Species Sepal.Width.Avg
1 versicolor 2.77
2 virginica 2.974
3 setosa 3.428
④ 导入可视化 R 包 ggplot2:
In [4]: library(ggplot2)
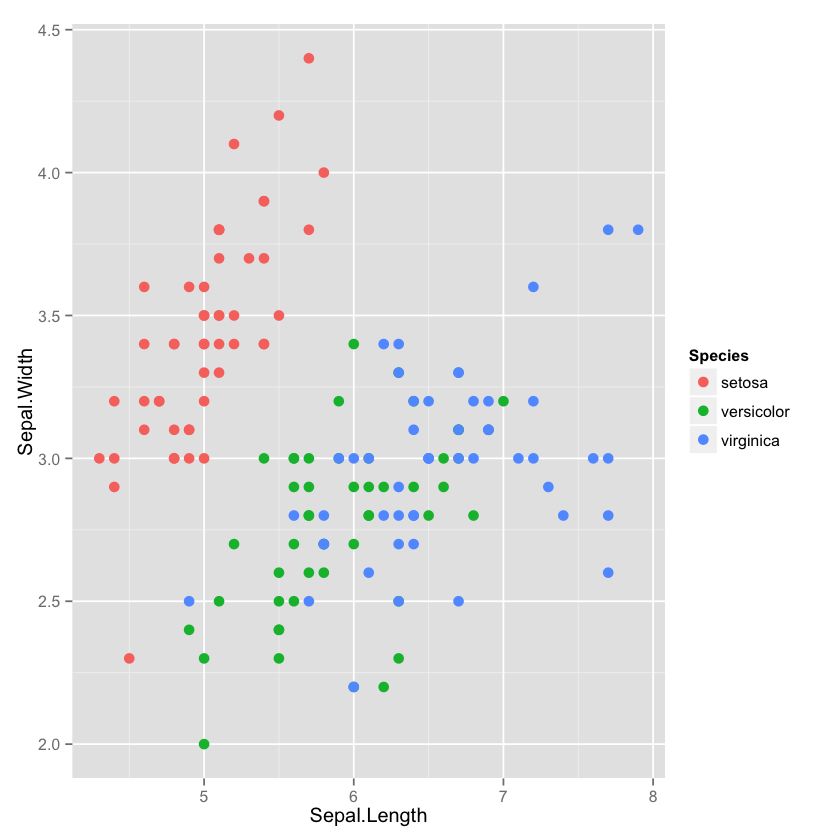
⑤ 绘图 Sepal.Width vs. Sepal.Length:
In [5]: ggplot(data=iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) + geom_point(size=3)
ok,今天就到这里。下一篇我们将会介绍如何使用 conda 创建我们的自定义的 R 集合包并上传与他人共享,以及介绍一下如何通过 Jupyter 把笔记转换为在线幻灯片,供讲座和教程使用。
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
使用 conda 和 Jupyter 在 R 中实现数据科学分析的更多相关文章
- 在R中整理数据
原始数据一般分散杂乱,并含有缺失和错误值,因此在进行数据分析前首先要对数据进行整理. 一.首先,了解原始数据的结构. 可使用如下函数(归属baseR)来查看数据结构: class(dataobject ...
- 如何使用Hive&R从Hadoop集群中提取数据进行分析
一个简单的例子! 环境:CentOS6.5 Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 1.分析题目 --有一个用户数据样本(表名huserinfo)10万数据左右: ...
- R中的数据重塑函数
1.去除重复数据 函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一 ...
- hive向表格中插入数据并分析语句
1,---导入mds_imei_month_info ; //最大的动态分区表 set hive.support.concurrency=false; //是否支持并发 ; //each mapper ...
- Ubuntu 18.04安装Conda、Jupyter Notebook、Anaconda
1.Conda是一个开源的软件包管理系统和环境管理系统,它可以作为单独的纯净工具安装在系统环境中,有的python库无法用conda获得时,conda允许在conda环境中利用Pip获取包文件.可以将 ...
- 第二篇:智能电网(Smart Grid)中的数据工程与大数据案例分析
前言 上篇文章中讲到,在智能电网的控制与管理侧中,数据的分析和挖掘.可视化等工作属于核心环节.除此之外,二次侧中需要对数据进行采集,数据共享平台的搭建显然也涉及到数据的管理.那么在智能电网领域中,数据 ...
- ROWID面试题-删除表中重复数据(重复数据保留一个)
/* ROWID是行ID,通过它一定可以定位到r任意一行的数据记录 ROWID DNAME DEPTNO LOC ------------------ ------------------------ ...
- (数据科学学习手札07)R在数据框操作上方法的总结(初级篇)
上篇我们了解了Python中pandas内封装的关于数据框的常用操作方法,而作为专为数据科学而生的一门语言,R在数据框的操作上则更为丰富精彩,本篇就R处理数据框的常用方法进行总结: 1.数据框的生成 ...
- 系统评价——数据包络分析DEA的R语言实现(七)
数据包络分析(Data envelopment analysis,DEA)是运筹学中用于测量决策部门生产效率的一种方法,它是基于相对效率发展的崭新的效率评估方法. 详细来说,通过使用数学规划模型,计算 ...
- 在centos 7 中 conda 环境和Python2.7 中安装远程jupyter
折腾了半天,为了能够方便学习TensorFlow,搞了远程的jupyter,方便在本地使用它,今天填了不少坑. 装完后截图: 下面是一些步骤: 检查 Python 环境 CentOS 7.2 中默认集 ...
随机推荐
- 学习在UMG中创建列表(List View)
原理 列表中的元素被称为 "Item",每个Item都是一个UObject.你需要为列表指定它的Entry.Entry也是个控件蓝图,它指定了针对于一个Item,它的界面是什么样子 ...
- Python的安装与配置(图文教程)
安装Python 想要进行Python开发,首先需要下载和配置Python解释器. 下载Python 访问Python官网: https://www.python.org/ 点击downloads按钮 ...
- 第一次博客:PTA题目集1-3总结
第一次博客:PTA题目集1-3总结 前言:JAVA是一门非常好的语言,因其面向对象的思想,在解决问题时思路与上学期学习的C语言截然不同,但是其优势也是显然易见的,特别是在写大型程序时其面向对象的思想, ...
- JAVA基础——常用类(一)
首先认识到--String是不可以变性(final) String:字符串,使用一对""引起来表示. * 1.String声明为final的,不可被继承 * ...
- Django之form表单相关操作
目录 摘要 form表单 form表单的action参数 form表单的method参数 request.method方法 简介 get请求传递数据 post请求传递数据 GET/POST实际应用,简 ...
- 创建SVN和设置密码以及SVN自动更新
重新创建版本库: svnadmin create /usr/local/svn/month_exam //创建一个svn版本仓库month_exam(month_exam可以随便起名字) cd ...
- Semantic Kernel 入门系列:🥑Memory内存
了解的运作原理之后,就可以开始使用Semantic Kernel来制作应用了. Semantic Kernel将embedding的功能封装到了Memory中,用来存储上下文信息,就好像电脑的内存一样 ...
- 移除List的统一逻辑写法 LeetCode 203
原理:通过创建一个新的结点,放在头结点的前面,作为真正头结点的前驱结点,这样头结点就成为了意义上的非头结点,这样就可以统一操作结点的删除操作. 需要注意的是:这个新的结点是虚拟头结点,真的的头结点依然 ...
- C# List转SqlServer、MySql中in字符串
var oneList = new List<string> { "1", "2", "3" }; var oneString ...
- vue中watch的详细用法(深度侦听)
vsCode插件 在vue中,使用watch来响应数据的变化.watch的用法大致有三种.下面代码是watch的一种简单的用法: <input type="text" v-m ...