神经网络优化篇:详解梯度检验(Gradient checking)
梯度检验
梯度检验帮节省了很多时间,也多次帮发现backprop实施过程中的bug,接下来,看看如何利用它来调试或检验backprop的实施是否正确。
假设的网络中含有下列参数,\(W^{[1]}\)和\(b^{[1]}\)……\(W^{[l]}\)和\(b^{[l]}\),为了执行梯度检验,首先要做的就是,把所有参数转换成一个巨大的向量数据,要做的就是把矩阵\(W\)转换成一个向量,把所有\(W\)矩阵转换成向量之后,做连接运算,得到一个巨型向量\(\theta\),该向量表示为参数\(\theta\),代价函数\(J\)是所有\(W\)和\(b\)的函数,现在得到了一个\(\theta\)的代价函数\(J\)(即\(J(\theta)\))。接着,得到与\(W\)和\(b\)顺序相同的数据,同样可以把\(dW^{[1]}\)和\({db}^{[1]}\)……\({dW}^{[l]}\)和\({db}^{[l]}\)转换成一个新的向量,用它们来初始化大向量\(d\theta\),它与\(\theta\)具有相同维度。
同样的,把\(dW^{[1]}\)转换成矩阵,\(db^{[1]}\)已经是一个向量了,直到把\({dW}^{[l]}\)转换成矩阵,这样所有的\(dW\)都已经是矩阵,注意\(dW^{[1]}\)与\(W^{[1]}\)具有相同维度,\(db^{[1]}\)与\(b^{[1]}\)具有相同维度。经过相同的转换和连接运算操作之后,可以把所有导数转换成一个大向量\(d\theta\),它与\(\theta\)具有相同维度,现在的问题是\(d\theta\)和代价函数\(J\)的梯度或坡度有什么关系?
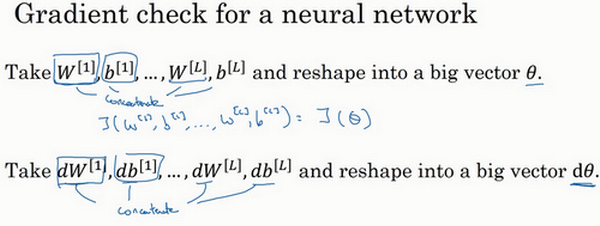
这就是实施梯度检验的过程,英语里通常简称为“grad check”,首先,要清楚\(J\)是超参数\(\theta\)的一个函数,也可以将J函数展开为\(J(\theta_{1},\theta_{2},\theta_{3},\ldots\ldots)\),不论超级参数向量\(\theta\)的维度是多少,为了实施梯度检验,要做的就是循环执行,从而对每个\(i\)也就是对每个\(\theta\)组成元素计算\(d\theta_{\text{approx}}[i]\)的值,使用双边误差,也就是
\(d\theta_{\text{approx}}\left[i \right] = \frac{J\left( \theta_{1},\theta_{2},\ldots\theta_{i} + \varepsilon,\ldots \right) - J\left( \theta_{1},\theta_{2},\ldots\theta_{i} - \varepsilon,\ldots \right)}{2\varepsilon}\)
只对\(\theta_{i}\)增加\(\varepsilon\),其它项保持不变,因为使用的是双边误差,对另一边做同样的操作,只不过是减去\(\varepsilon\),\(\theta\)其它项全都保持不变。

之前了解到这个值(\(d\theta_{\text{approx}}\left[i \right]\))应该逼近\(d\theta\left[i \right]\)=\(\frac{\partial J}{\partial\theta_{i}}\),\(d\theta\left[i \right]\)是代价函数的偏导数,然后需要对i的每个值都执行这个运算,最后得到两个向量,得到\(d\theta\)的逼近值\(d\theta_{\text{approx}}\),它与\(d\theta\)具有相同维度,它们两个与\(\theta\)具有相同维度,要做的就是验证这些向量是否彼此接近。

具体来说,如何定义两个向量是否真的接近彼此?一般做下列运算,计算这两个向量的距离,\(d\theta_{\text{approx}}\left[i \right] - d\theta[i]\)的欧几里得范数,注意这里(\({||d\theta_{\text{approx}} -d\theta||}_{2}\))没有平方,它是误差平方之和,然后求平方根,得到欧式距离,然后用向量长度归一化,使用向量长度的欧几里得范数。分母只是用于预防这些向量太小或太大,分母使得这个方程式变成比率,实际执行这个方程式,\(\varepsilon\)可能为\(10^{-7}\),使用这个取值范围内的\(\varepsilon\),如果发现计算方程式得到的值为\(10^{-7}\)或更小,这就很好,这就意味着导数逼近很有可能是正确的,它的值非常小。
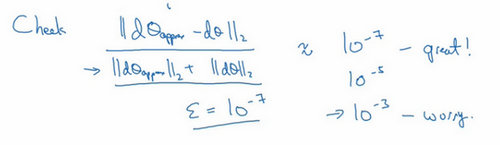
如果它的值在\(10^{-5}\)范围内,就要小心了,也许这个值没问题,但会再次检查这个向量的所有项,确保没有一项误差过大,可能这里有bug。
如果左边这个方程式结果是\(10^{-3}\),就会担心是否存在bug,计算结果应该比\(10^{- 3}\)小很多,如果比\(10^{-3}\)大很多,就会很担心,担心是否存在bug。这时应该仔细检查所有\(\theta\)项,看是否有一个具体的\(i\)值,使得\(d\theta_{\text{approx}}\left[i \right]\)与$ d\theta[i]$大不相同,并用它来追踪一些求导计算是否正确,经过一些调试,最终结果会是这种非常小的值(\(10^{-7}\)),那么,的实施可能是正确的。

在实施神经网络时,经常需要执行foreprop和backprop,然后可能发现这个梯度检验有一个相对较大的值,会怀疑存在bug,然后开始调试,调试,调试,调试一段时间后,得到一个很小的梯度检验值,现在可以很自信的说,神经网络实施是正确的。
神经网络优化篇:详解梯度检验(Gradient checking)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 【零基础】神经网络优化之dropout和梯度校验
一.序言 dropout和L1.L2一样是一种解决过拟合的方法,梯度检验则是一种检验“反向传播”计算是否准确的方法,这里合并简单讲述,并在文末提供完整示例代码,代码中还包含了之前L2的示例,全都是在“ ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
- CentOS 7 下编译安装lnmp之MySQL篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.MySQL下载 MySQL ...
- CentOS 7 下编译安装lnmp之nginx篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:CentOS Linux release 7.5.1804 (Core),ip地址 192.168.1.168 ...
- Linux netstat命令详解(检验本机各端口的网络连接情况)
netstat命令用于显示与IP.TCP.UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况.netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP ...
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- java提高篇-----详解java的四舍五入与保留位
转载:http://blog.csdn.net/chenssy/article/details/12719811 四舍五入是我们小学的数学问题,这个问题对于我们程序猿来说就类似于1到10的加减乘除那么 ...
随机推荐
- Oracle:Ora-01652无法通过128(在temp表空间中)扩展temp段的过程-解决步骤
现象:查询select * from v$sql时提示"Ora-01652无法通过128(在temp表空间中)扩展temp段的过程" 临时文件是不存储的,可以将数据库重启,重启后重 ...
- Biwen.QuickApi代码生成器功能上线
[QuickApi("hello/world")] public class MyApi : BaseQuickApi<Req,Rsp>{} 使用方式 : dotnet ...
- c语言代码练习10
//判断输入的数字是否为素数#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> int main() { int n = 0; int ...
- Python基础——函数的理解、函数对象、函数嵌套、闭包函数、及其应用
文章目录 函数也是变量 可以赋值 可以当做函数当做参数传给另外一个函数 可以当做函数当做另外一个函数的返回值 可以当做容器类型的一个元素 函数对象应用示范 原始版 修正版 函数嵌套 函数的嵌套调用 函 ...
- 背景图片随机API
在美化博客园的时候,遇到了一个问题:博客背景图片只支持一张图片,看到有道友说可以用API随机图片. 于是就有了这篇文章. 本文主要整理了一些随机图片API,希望对你有帮助. 岁月小筑 https:// ...
- DHorse v1.4.2 发布,基于 k8s 的发布平台
版本说明 优化特性 在集群列表增加集群版本: 修改Jvm的GC指标名: 解决问题 解决shell脚本换行符的问题: 解决部署历史列表页,环境名展示错误的问题: 解决指标收集功能的异常: 升级指南 升级 ...
- 深入探讨I/O模型:Java中的阻塞和非阻塞和其他高级IO应用
引言 I/O(Input/Output)模型是计算机科学中的一个关键概念,它涉及到如何进行输入和输出操作,而这在计算机应用中是不可或缺的一部分.在不同的应用场景下,选择正确的I/O模型是至关重要的,因 ...
- 探索CPU的黑盒子:解密指令执行的秘密
引言 在我们之前的章节中,我们着重讲解了CPU内部的处理过程,以及与之密切相关的数据总线知识.在这个基础上,我们今天将继续深入探讨CPU执行指令的相关知识,这对于我们理解计算机的工作原理至关重要. C ...
- springboot项目在docker中运行
前端时间需要把项目打包到docker中运行,于是就让组员去探索,最后整个过程是这样的. 首先我们做java开发,一般都是使用springboot开发,开发完成,我们需要把springboot项目打包成 ...
- [vue]精宏技术部试用期学习笔记 II
精宏技术部试用期学习笔记(vue) router : vue的模拟路由 前置准备 安装 vue-router pnpm i vue-router@4 //安装版本4的 vue-router 可以在 p ...