[转帖]oracle ZHS16GBK的数据库导入到字符集为AL32UTF8的数据库(转载+自己经验总结)
字符集子集向其超集转换是可行的,如此例 ZHS16GBK转换为AL32UTF8。
导出使用的字符集将会记录在导出文件中,当文件导入时,将会检查导出时使用的字符集设置,如果这个字符集不同于导入客户端的NLS_LANG
设置,字符集将根据导入客户端NLS_LANG设置进行转换,如果必要,在数据插入数据库之前会进行进一步转换。
通常在导出时最好把客户端字符集设置得和数据库端相同,这样可以避免在导出时发生不必要的数据转换,导出文件将和数据库具有相同的字符集。
即使将来会把导出文件导入到不同字符集的数据库中,这样做也可以把转换延缓至导入时刻。
当进行数据导入时,主要存在以下两种情况:
1.源数据库和目标数据库具有相同字符集设置
这时,只需要设置NLS_LANG等于数据库字符集即可导入(前提是,导出使用的是和源数据库相同字符集,即三者相同)
2.源数据库和目标数据库字符集不同
如果我们导出时候使用的NLS_LANG是和源数据库相同的字符集,那么导入时就可以设置客户端NLS_LANG等于导出时使用的字符集,这
样转换只发生在数据库端,而且只发生一次。
例如:
如果进行从ZHS16GBK到UTF8的转换
1)使用NLS_LANG=AMERICAN_AMERICA.ZHS16GBK导出数据库。
这时创建的导出文件包含ZHS16GBK的数据
2)导入时使用NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
这时转换仅发生在insert数据到UTF8的数据库中。
以上假设的转换只在目标数据库字符集是源数据库字符集的超集时才能转换。
参考文章:
http://www.itpub.net/thread-538197-1-1.html
http://www.itpub.net/viewthread.php?tid=276524&extra=page%3D1&page=1
http://www.eygle.com/archives/2004/09/nls_character_set_04.html
含有汉字的固定字符由ZHS16GBK数据库导入到AL32UTF8的数据库
此文章是对于上一个实验的补充,上一次实验仅仅考虑的 varchar2 的情况。这次考虑到对于char类型的含有中文数据的情况。
对于英文:
对英文,在al32utf8中仍然和zhs16gbk一样用1个字节表示,因此导入固定长度英文字符数据时不会出错。
对于中文:
例如在字符集为zhs16gbk 数据库中创建表时指定字段 val char(15),该字段含有数据 ‘阿里云计算公司’在字符集为zhs16gbk 数据库中占用14个字
节,而在字符集为al32utf8 数据库中占用21个字节 大于 char(15)所指定的长度15.此时导入数据就会失败。
对于英文字符可以实现由zhs16gbk 到 al32utf8的转换。
解释:用UTF-8,UNICODE的2字节字符用变长个(1-3个字节)表示:
1. 对英文,仍然和ASCII一样用1个字节表示,这个字节的值小于128(\x80);
2. 扩展的ASCII字符(主要是西欧),第一字节用C2 - DF之间的范围,双字节表示。
3.对其他语言,比如亚洲语系,还有各种特殊符号,使用3个字节表示;
因此,在应用中程序处理过程中所有字符都是16位(双字节),但在存取转换成字节流时使用UTF-8格式转换,对于英文字符来说和原来用ASCII方式存取
时相比大小仍然是一样的,而对中文来说和原来的GB2312编码方式相比,大小为:(3字节/2字节)=1.5倍,这也是下面导入数据失败的原因。
总结
1.当源端字符编码为ZHS16GBK,目标端编码为AL32UTF8,客户端随便为其中的一种编码,迁移数据不会出现乱码,但是会出现列长度不够现象。反过来不行,因为utf8中的部分字符转换到gbk中肯定会不支持
2.设置了源端客户端编码,仅仅是导出来的dmp文件头部有编码字符标示不一样,存储数据还是按照服务端存储
3.打破神话,exp/imp导入要不乱码,导出和导入的客户端编码要一致
原因分析,解决建议
在导入过程中,最多会发生三次编码转换:
1、执行exp时,数据库中数据的编码会转换为导出客户端编码
2、执行imp时,dmp文件的编码转换为导入客户端编码
3、导入客户端编码转换为目标端数据库的数据库编码
在exp/imp操作的过程中,经常出现乱码的原因就是编码的相互转换的过程中出现了丢失或者相互不能转换导致。要解决这个问题,最好的办法就是通过NLS_LANG的灵活设置,减少编码转换的次数(如果相邻的转换操作编码一致,那么不会发生编码转换,如试验中的ZHS16GBK编码测试,就没有转换发生),或者使得相互的转换能够兼容,可以最大程度的减少乱码的出现。
如果已经有了exp导出的dmp文件,然后在导入的过程中,出现乱码,一般的处理建议是nls_lang的编码设置和dmp文件的一致,让转换发生在导入客户端和数据库服务器间(要求:编码可以相互转换)
个人总结(非转载)
恢复备份执行(imp)时将客户端设置字符集和目标数据库字符集编码格式一致
(建议源数据库字符集、客户端、目标数据库字符集三者保持一致)
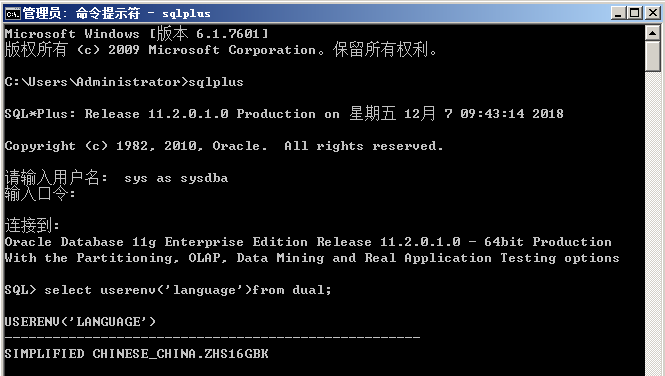
1)查看数据库字符集设置
sql--select userenv(‘language’)from dual; oracle中查询的字符集USERENV('LANGUAGE')
我自己的服务器用的是zhs16gbk 中文字符集
2)客户端操作系统字符--查询--配置
(1) cmd-chcp 查询指定代码页。下表列出了所有支持的代码页及其国家(地区)或者语言:
代码页 国家(地区)或语言
936 中国 - 简体中文(GBk)
Windows XP、Windows7、WIN10、WIN sever 2008 R2 操作系统自带的都是GBK字符集(含2万余汉字)
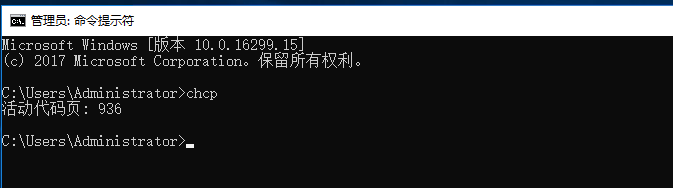
936即为中文GBK字符集
(2 )查看注册表-win+r--regedit
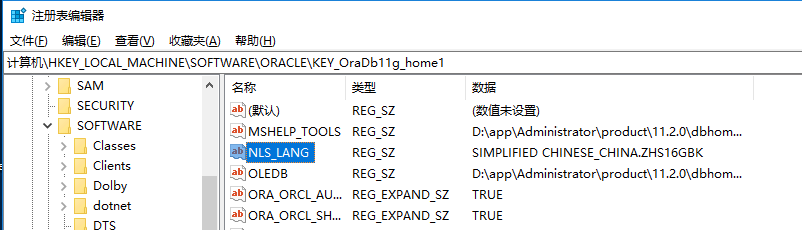
(3)将客户端添加环境变量。
设置环境变量名NLS_LANG
变量值为SIMPLIFIED CHINESE_CHINA.ZHS16GBK (一定重启电脑才生效)

---------------------
作者:白及
来源:CSDN
原文:https://blog.csdn.net/u010098331/article/details/50766454
版权声明:本文为博主原创文章,转载请附上博文链接!
[转帖]oracle ZHS16GBK的数据库导入到字符集为AL32UTF8的数据库(转载+自己经验总结)的更多相关文章
- ZHS16GBK的数据库导入到字符集为AL32UTF8的数据库
字符集为ZHS16GBK的数据库导入到字符集为AL32UTF8的数据库 相信大家都对字符集有相当的了解了,废话就不多说了!直接步入正题:这里主要是测试含有 汉字的数据从ZHS16GBK的数据库导入到 ...
- oracle ZHS16GBK的数据库导入到字符集为AL32UTF8的数据库(转载+自己经验总结)
字符集子集向其超集转换是可行的,如此例 ZHS16GBK转换为AL32UTF8. 导出使用的字符集将会记录在导出文件中,当文件导入时,将会检查导出时使用的字符集设置,如果这个字符集不同于导入客户端的N ...
- 如何进行数据库,比如ORACLE,SQL SERVER的逆向工程,将数据库导入到PowerDesigner中
Oracle的反向工程就是指将Oracle中的数据库,当然也可以是SQL Server中的数据库导入到PD中,这个需要建立一个数据库的链接,然后进行逆向工程的操作. 第一步:建立数据库的链接: Pow ...
- SQLSERVER的逆向工程,将数据库导入到PowerDesigner中
原文:http://blog.csdn.net/linianzhenti/article/details/42938595 PD是一款不错的数据库设计工具,在佩特来这个项目中,起初,合作伙伴用PD大体 ...
- Java实现MySQL数据库导入
距离上班还有一段时间.现在总结一下如何使用Java语言实现MySQL数据库导入: 首先新建名为test的数据库: 其次执行下面Java代码: import java.io.File; import j ...
- Oracle 数据库导入导出 dmp文件
转自: http://hi.baidu.com/ooofcu/blog/item/ec5d1f9580d41f007af48077.html 首先询问对方数据库的表空间名称和大小,然后在你的oracl ...
- Linux下oracle11gR2系统安装到数据库建立配置及最后oracle的dmp文件导入一站式操作记录
简介 之前也在linux下安装过oralce,可每次都是迷迷糊糊的,因为大脑一片空白,网上随便看见一个文档就直接复制,最后搞了乱七八糟,虽然装上了,却乱得很,现在记录下来,希望能给其他网上朋友遇到问题 ...
- Oracle 数据库导入与出
Oracle 数据库导入与出 导出( EXPORT )是用 EXP 将数据库部分或全对象的结构和导出 . 导入( 导入( IMPORT )是用 )是用 IMP IMP将 OS 文件中的对象结构和数据装 ...
- 转载-Oracle 数据库导入导出 dmp文件
首先询问对方数据库的表空间名称和大小,然后在你的oracle中建立相应表空间,最后使用命令导入.导出数据.补充:1.要新建一个数据库: Oracle数据导入导出imp/exp就相当于oracle数据还 ...
- Oracle数据库导入导出命令总结
Oracle数据导入导出imp/exp就相当于oracle数据还原与备份.exp命令可以把数据从远程数据库服务器导出到本地的dmp文件,imp命令可以把dmp文件从本地导入到远处的数据库服务器中.利用 ...
随机推荐
- Typora远程代码执行漏洞 - CVE-2023-2317
Typora - CVE-2023-2317 简介 Typora一个常用的markdown编辑器,在1.6.7之前存在XSS漏洞,可以通过传入参数触发来加载恶意的JavaScript代码 分析 在ty ...
- 字正腔圆,万国同音,coqui-ai TTS跨语种语音克隆,钢铁侠讲16国语言(Python3.10)
按照固有的思维方式,如果想要语音克隆首先得有克隆对象具体的语言语音样本,换句话说,克隆对象必须说过某一种语言的话才行,但现在,coqui-ai TTS V2.0版本做到了,真正的跨语种无需训练的语音克 ...
- VSCode C++开发环境配置: LLVM clang clangd
工欲善其事,必先利其器 llvm/clang 比 VSCode 自带的代码提示功能速度更快,功能更强(支持 clang-tidy). 安装 llvm.clang sudo apt install ll ...
- 文心一言 VS 讯飞星火 VS chatgpt (158)-- 算法导论12.3 5题
五.用go语言,假设为每个结点换一种设计,属性 x.p 指向 x 的双亲,属性 x.succ 指向 x 的后继.试给出使用这种表示法的二叉搜索树 T 上 SEARCH.INSERT 和DELETE 操 ...
- 在线录屏-通过Web API接口轻松实现录屏
在线录屏是指在互联网上进行屏幕录制的过程.它允许用户通过网络连接,将自己的屏幕活动记录下来,并可以在需要时进行播放.共享或存档.在线录屏常用于教育.培训.演示.游戏等场景,可以帮助用户展示操作步骤.解 ...
- Spark Core快速入门
Spark-core快速入门 一.简介 Apache spark是专门为大规模数据处理而设计的快速通用的计算模型,是一种类似于Mapreduce通用并行计算框架,与mapreduce不同的是,spar ...
- Langchain-Chatchat项目:1.2-Baichuan2项目整体介绍
由百川智能推出的新一代开源大语言模型,采用2.6万亿Tokens的高质量语料训练,在多个权威的中文.英文和多语言的通用.领域benchmark上取得同尺寸最佳的效果,发布包含有7B.13B的Bas ...
- Java 插入Excel页眉、页脚
前言 在Excel文档中,我们常用页眉页脚来显示文档的附加信息,例如日期.公司名称.Logo或作者信息等.本文将通过Java程序来介绍如何给Excel文档添加页眉页脚.代码示例主要从以下几方面来演示添 ...
- KubeEdge Sedna v0.6 & Ianvs v0.2 重磅发布:边云协同终身学习全面升级
本文分享自华为云社区<KubeEdge Sedna v0.6 & Ianvs v0.2 重磅发布:边云协同终身学习全面升级>,作者: 云容器大未来 . 本文探讨了边缘智能应用在开放 ...
- 源生创新 云享未来|GOTC全球开源技术峰会华为云云原生精彩时刻
摘要:GOTC 全球开源技术峰会在上海张江科学会堂成功举办. 本文分享自华为云社区<源生创新 云享未来|GOTC全球开源技术峰会华为云云原生精彩时刻>,作者:华为云云原生团队. GOTC ...