Langchain-Chatchat项目:1.2-Baichuan2项目整体介绍
由百川智能推出的新一代开源大语言模型,采用2.6万亿Tokens的高质量语料训练,在多个权威的中文、英文和多语言的通用、领域benchmark上取得同尺寸最佳的效果,发布包含有7B、13B的Base和经过PPO训练的Chat版本,并提供了Chat版本的4bits量化。
一.Baichuan2模型
Baichuan2模型在通用、法律、医疗、数学、代码和多语言翻译六个领域的中英文和多语言权威数据集上对模型进行了广泛测试。

二.模型推理
1.Chat模型
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "解释一下“温故而知新”"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。
2.Base模型
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
>>> inputs = inputs.to('cuda:0')
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
登鹳雀楼->王之涣
夜雨寄北->李商隐
3.命令行工具方式和网页demo方式
python cli_demo.py
streamlit run web_demo.py
三.模型微调
1.依赖安装
如需使用LoRA等轻量级微调方法需额外安装peft,如需使用xFormers进行训练加速需额外安装xFormers,如下所示:
git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt
2.单机训练
下面是一个微调Baichuan2-7B-Base的单机训练例子,训练数据data/belle_chat_ramdon_10k.json来自multiturn_chat_0.8M采样出的1万条,如下所示:
hostfile=""
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True
3.多机训练
多机训练只需要给一下hostfile,同时在训练脚本里面指定hosftfile的路径:
hostfile="/path/to/hostfile"
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True
其中,hostfile内容如下所示:
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
4.轻量化微调
如需使用仅需在上面的脚本中加入参数--use_lora True,LoRA具体的配置可见fine-tune.py脚本。使用LoRA微调后可以使用下面的命令加载模型:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained("output", trust_remote_code=True)
四.其它
1.对Baichuan1的推理优化迁移到Baichuan2
用户只需要利用以下脚本离线对Baichuan2模型的最后一层lm_head做归一化,并替换掉lm_head.weight即可。替换完后,就可以像对Baichuan1模型一样对转换后的模型做编译优化等工作:
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch.load(os.path.join(ori_model_dir, 'pytorch_model.bin'))
lm_head_w = model['lm_head.weight']
lm_head_w = torch.nn.functional.normalize(lm_head_w)
model['lm_head.weight'] = lm_head_w
torch.save(model, os.path.join(new_model_dir, 'pytorch_model.bin'))
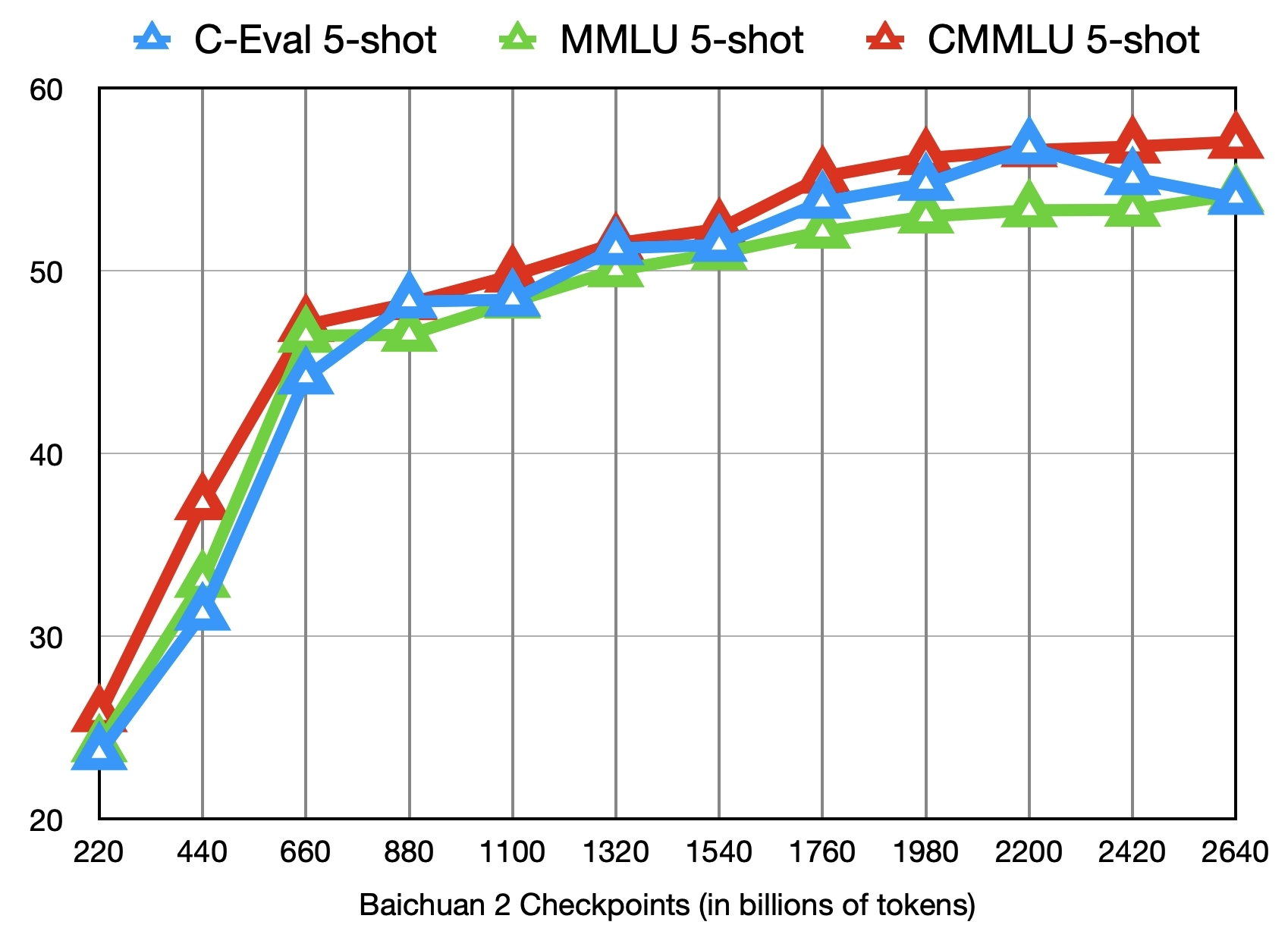
2.中间Checkpoints
下图给出了这些checkpoints在C-Eval、MMLU、CMMLU三个benchmark上的效果变化:
参考文献:
[1]https://github.com/baichuan-inc/Baichuan2
[2]baichuan-inc:https://huggingface.co/baichuan-inc
[3]https://huggingface.co/baichuan-inc/Baichuan2-7B-Intermediate-Checkpoints
[4]Baichuan 2: Open Large-scale Language Models:https://arxiv.org/abs/2309.10305
Langchain-Chatchat项目:1.2-Baichuan2项目整体介绍的更多相关文章
- Maven搭建SpringMVC+MyBatis+Json项目(多模块项目)
一.开发环境 Eclipse:eclipse-jee-luna-SR1a-win32; JDK:jdk-8u121-windows-i586.exe; MySql:MySQL Server 5.5; ...
- Java项目转换成Web项目
阐述:有时候我们在Eclipse中导入一个web项目,发现导入到项目中后变成一个Java项目,这让人很蛋疼.本篇主要讲述怎样将这个本该为web项目的Java项目变身回去,以及一些在导入过程中遇到的一些 ...
- (转)项目迁移_.NET项目迁移到.NET Core操作指南
原文地址:https://www.cnblogs.com/heyuquan/p/dotnet-migration-to-dotnetcore.html 这篇文章,汇集了大量优秀作者写的关于" ...
- Android快乐贪吃蛇游戏实战项目开发教程-01项目概述与目录
一.项目简介 贪吃蛇是一个很经典的游戏,也很适合用来学习.本教程将和大家一起做一个Android版的贪吃蛇游戏. 我已经将做好的案例上传到了应用宝,无病毒.无广告,大家可以放心下载下来把玩一下.应用宝 ...
- Mysql查找所有项目开始时间比之前项目结束时间小的项目ID
这是之前遇到过的一道sql面试题,供参考学习: 查找所有项目开始时间比之前项目结束时间小的项目ID mysql> select * from t2; +----+---------------- ...
- 如何把maven项目转成web项目
创建Web工程,使用eclipse ee创建maven web工程 1.右键项目,选择Project Facets,点击Convert to faceted from 2.更改Dynamic Web ...
- Mvc项目架构分享之项目扩展
Mvc项目架构分享之项目扩展 Contents 系列一[架构概览] 0.项目简介 1.项目解决方案分层方案 2.所用到的技术 3.项目引用关系 系列二[架构搭建初步] 4.项目架构各部分解析 5.项目 ...
- eclipse 项目修改和更新项目,回退版本,解决分支的冲突的办法
一个关于git的图 1.我在github建立了3个分支. 2.把其中一个分支拉到本地. 项目修改提交到远程库 3.修改完代码以后commit项目,点击项目右击->team->commit ...
- MVC+Ef项目(2) 如何更改项目的生成顺序;数据库访问层Repository仓储层的实现
我们现在先来看看数据库的生成顺序 居然是 Idal层排在第一,而 web层在第二,model层反而在第三 了 我们需要把 coomon 公用层放在第一,Model层放在第二,接下来是 Idal ...
- maven3常用命令、java项目搭建、web项目搭建详细图解
http://blog.csdn.net/edward0830ly/article/details/8748986 ------------------------------maven3常用命令-- ...
随机推荐
- SQLPLUS使用及Oracle表空间设定自动扩展
起因:ERP不能登陆,Oracle无法访问,报错如下 后联系鼎捷se提供以下解决方案: 该问题是由于Oracle审计表AUD$数据过大导致数据库异常,现已登录DB服务器使用oracle账号执行语句tr ...
- 强化学习的一周「GitHub 热点速览」
当强化学习遇上游戏,会擦出什么样的火花呢?PokemonRedExperiments 将经典的 Pokeman 游戏接上了强化学习,效果非同凡响,不然能一周获得 4.5k star 么?看看效果图就知 ...
- 详解GuassDB数据库权限命令:GRANT和REVOKE
本文分享自华为云社区<GuassDB数据库的GRANT & REVOKE>,作者: Gauss松鼠会小助手2 . 一.GaussDB的权限概述 在数据库中,对象的创建者将成为该对象 ...
- P9481 [NOI2023] 贸易 题解
题目链接 题目要求我们求出任意两点间最短路径之和,由于图比较特殊,除树边外只有祖先到其子树内的边,我们首先考虑最短路径有没有什么特殊性质. 注意到两点之间的最短路分为一下三种: 节点到其祖先的最短路: ...
- JavaScript:用户代理检测:通过浏览器识别平台、操作系统等(Windows, Mac, iOS,iPad等)
客户端检测经常用的方法:能力检测.怪癖检测和用户代理检测. 能力检测:在写代码前先检测浏览器的能力. 怪癖检测:实际上是浏览器现存的bug. 用户代理检测:通过检测用户代理字符串来识别浏览器. 一般优 ...
- [Python急救站课程]日期和时间的输出
日期和时间的输出 from datetime import datetime # 引用datetime 库 now = datetime.now() # 获得当前日期和时间信息 print(now) ...
- offscreenCanvas+worker+IndexedDB实现无感大量图片缓存
一个有必要实现的需求 因为项目中需要使用canvasTexture(一个threejs3d引擎中的材质类型),绘制大量的图片,每次使用都会请求大量的oss图片资源,虽然重复请求会有磁盘缓存但毕竟这个磁 ...
- 基于 TCP 协议写的 FTP 管理小工具
这是一个FTP(文件传输协议)管理工具,能够支持文件上传下载以及操作服务端的文件. 该工具由客户端和服务端组成.客户端与服务端通过Socket连接实现通信,客户端发送命令,服务端解析并执行相应的操作. ...
- python函数定义、调用、参数、返回
python函数定义语法: 定义: Def foo(): print('bar') print('bar2') 如果函数内容特别少,可以一行定义 : Def foo(): print('bar') ...
- C语言源码的陷波器设计及调试总结
一 前记 音频信号处理中,限波器是一个常用的算法.这个算法难度不是很高,可用起来却坑很多. 二 源码解析 1 滤波器的核心函数,这里注意两点,一个是带宽不能太宽了,太宽了杀伤力太大了,容易出问题.另外 ...