Logistics Regression (对数几率回归)及numpy实现
Logistics Regression
我们知道线性回归模型可以处理回归问题,但是如何处理分类问题?
对于一个二分类问题,或许我们可以认为w*x+b > 0为正类,其他情况为负类。
那么模型不就变成了:y = f(z) ,z = w*x+b,即 y = f(w*x+b)
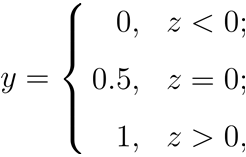
z大于零就判为正例,小于零就判为反例,z为临界值零则可任意判别 。
不难发现我们提出了一个新的函数 f ,也就是阶跃函数作为一个联系函数,把 z = w*x+b一个线性模型和 y 联系起来了。
于是我们把这种加入了联系函数的新的线性模型称之为广义线性模型。
广义线性模型的一般形式为:

在这里,g 称为联系函数,因此我们刚才说的 f 是联系函数是有点区别的,f 函数应该是 g 的反函数,g 是关于y 的一个函数,也就 g(y) = w*x+b,不难发现,广义线性模型的目的是希望用线性模型w*x+b来逼近y 的衍生物 g(y)。
Why logistic ?
从阶跃函数的图像上看,不难发现它是一个不是一个严格单调的函数(ps:西瓜书上说是因为连续,并未说明要求单调,但是笔者认为是因为不是严格单调所以才不能使用阶跃函数),因此不能作为 g 的反函数。于是我们想引入一个单调可微的函数,sigmoid函数。
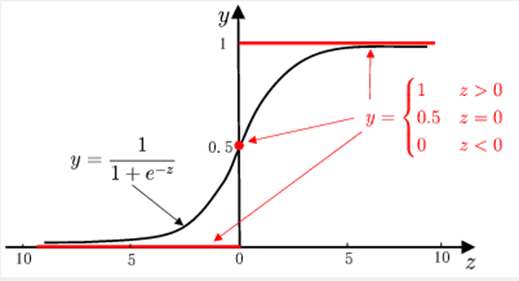
所以 :
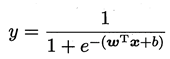
若将 y 视为样本 x 下作为正例的可能性,则1-y 则是负例的可能性(这里其实我们使用了一个假设,在给定x的情况下y服从Bernoulli分布)。我们称
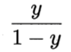
为几率(odds) ,几率反映了x作为正例的相对可能性,对几率取对数得到对数几率(log odds,也称 logit):
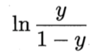
此处我们进行一番推导:
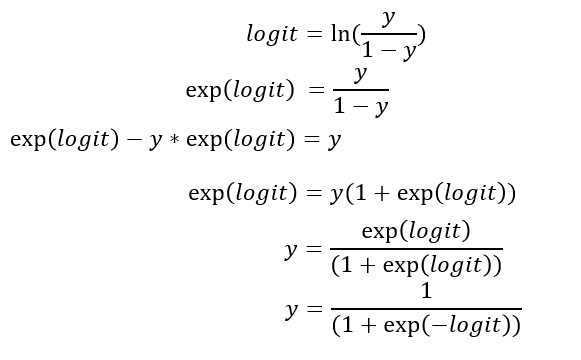
至此,我们发现对数几率 logit 和 y 的关系是sigmoid函数关系,这也是开头为什么我们要用sigmoid函数原因。
接着我们根据这个式子,我们提出假设: 对数几率 logit 和 x 满足线性相关,即 logit = w*x+b。
因此呼应了我们提出的对数几率回归模型,使用sigmoid函数作为联系函数,用线性模型去逼近真实的对数几率。
因此这就是为什么该模型称为对数几率回归模型。
当我们不知道数据分布的情况下,我们得到的模型输出不仅仅是预测的类别,而是近似的概率。
什么时候能够确定我们的输出是概率呢?
需要满足两个条件:
1. y服从Bernoulli分布(只有分类问题0,1值,经常会选择该假设。该假设的意义在于对每一个确定的x,y仍然是一个随机变量,给出的x不同,y服从的Bernoulli分布参数也不同)
2. 对数几率 logit 和 x 满足线性相关。
只有这两个条件满足输出的才是概率,否则输出的是一种近似概率的置信度。
代码实现:
数据集:德国信用数据集:UCI German Credit
训练集和测试集按9:1划分。
笔者没有进行特征归一化的测试结果准确率是64%,归一化后,同一个验证集上准确率达到了73%,数据归一化确实提升了模型的泛化能力。
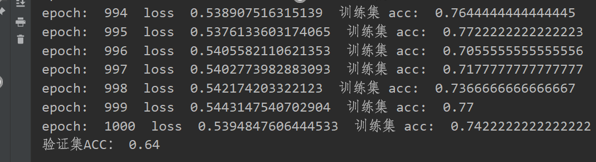
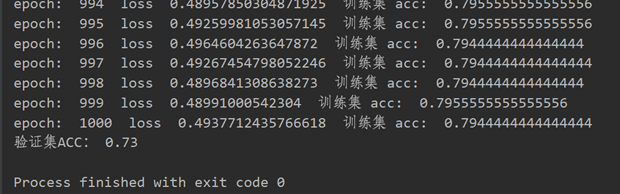
代码如下:
1 import numpy as np
2 import math
3
4 class LR(object):
5 def __init__(self,nums_feature,lr = 0.001,batch = 32,epoch=1000):
6 self.lr=lr
7 self.nums_class = 2 # y的分类数,这里只有二分类,所以是2
8 self.nums_feature = nums_feature # x 的特征数
9 self.w = np.random.normal(0, 1,nums_feature).reshape(nums_feature,1)
10 self.b = np.zeros(1)
11 self.batch_size = batch
12 self.epoch = epoch
13
14 def sigmoid(self,x):
15 return 1 / (1 + np.exp(-x))
16
17 def delta_sigmoid(self,x): # sigmoid 导数
18 s = self.sigmoid(x)
19 return (1-s)*s
20
21 def calculate_loss(self,xx,yy):
22 # xx shape: nums*f
23 # yy shape: nums*1
24 nums = xx.shape[0]
25 mat = np.matmul(xx, self.w) + self.b.repeat(nums).reshape(nums,1)
26 # mat shape : nums*1
27 loss = (np.log(1+np.exp(mat))-mat*yy).sum()
28 return loss/nums # float
29
30 def get_grad(self,xx,yy):
31 nums = xx.shape[0]
32 mat = np.matmul(xx, self.w)+self.b.repeat(nums).reshape(nums,1)
33 active_mat = self.sigmoid(mat)
34 delta = np.repeat(yy - active_mat,repeats= self.nums_feature).reshape(nums,self.nums_feature)
35 w_grad = delta*xx
36 w_grad = -1*np.sum(w_grad,axis=0)/nums
37 b_grad = -1*(yy - active_mat).sum()/nums
38 return w_grad.reshape(self.nums_feature,1) , b_grad
39
40 def fit(self,X,Y):
41 # 输入X,Y为numpy的格式
42 samples_num = X.shape[0]
43 SX = X
44 SY = Y
45 Y = Y.reshape(samples_num,1)
46 for epoch in range(1,self.epoch+1):
47 shuffle_ix = np.random.permutation(np.arange(samples_num))
48 X = X[shuffle_ix] # nums*f
49 Y = Y[shuffle_ix] # nums*1
50 loss = 0.0
51 for idx in range(0,samples_num,self.batch_size):
52 xx = X[idx:idx+self.batch_size]
53 yy = Y[idx:idx+self.batch_size]
54 loss = loss + self.calculate_loss(xx,yy)
55 w_grad,b_grad = self.get_grad(xx,yy) # 计算梯度
56 self.w = self.w - self.lr*w_grad # w 权值更新
57 self.b = self.b - self.lr*b_grad # b 权值更新
58 acc= self.predict(SX,SY)
59 print('epoch: ',epoch,' loss ',loss/(samples_num//self.batch_size),' 训练集 acc: ',acc)
60 pass
61
62 def predict(self,X,Y):
63 nums = X.shape[0]
64 prey = self.sigmoid(np.matmul(X, self.w) + self.b.repeat(nums).reshape(nums,1)).squeeze()
65 pre_label = np.where(prey > 0.5,1,0)
66 acc = np.where(pre_label==Y,1,0).sum()
67 return acc/nums
68
69 np.random.seed(123)
70 data = np.loadtxt("german.data-numeric")
71 print(data)
72 # 数据归一化
73 # n, l = data.shape
74 # for j in range(l-1):
75 # meanVal = np.mean(data[:, j])
76 # stdVal = np.std(data[:, j])
77 # data[:, j] = (data[:, j]-meanVal) / stdVal
78
79 shuffle_ix = np.random.permutation(np.arange(data.shape[0])) # 打乱数据集
80 data = data[shuffle_ix]
81 X = data[:900,:-1]
82 Y = data[:900,-1]-1 # Y label = 1 or 2 , Y = Y-1 get label = 0 or 1
83 print(data.shape)
84 print(X.shape)
85 print(Y.shape)
86 LR = LR(24)
87 LR.fit(X,Y)
88 X =data[900:,:-1]
89 Y =data[900:,-1] -1
90 print('验证集ACC:',LR.predict(X,Y))
参考资料:
1、周志华——《机器学习》
2、逻辑回归输出的值是真实的概率吗?——https://www.jianshu.com/p/a8d6b40da0cf
3、李航——《统计学习方法》
4、实战-logistic 回归二元分类——https://zhuanlan.zhihu.com/p/99473017
Logistics Regression (对数几率回归)及numpy实现的更多相关文章
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 对数几率回归(逻辑回归)原理与Python实现
目录 一.对数几率和对数几率回归 二.Sigmoid函数 三.极大似然法 四.梯度下降法 四.Python实现 一.对数几率和对数几率回归 在对数几率回归中,我们将样本的模型输出\(y^*\)定义 ...
- 机器学习总结-LR(对数几率回归)
LR(对数几率回归) 函数为\(y=f(x)=\frac{1}{1+e^{-(w^{T}x+b)}}\). 由于输出的是概率值\(p(y=1|x)=\frac{e^{w^{T}x+b}}{1+e^{w ...
- 学习笔记TF009:对数几率回归
logistic函数,也称sigmoid函数,概率分布函数.给定特定输入,计算输出"success"的概率,对回题回答"Yes"的概率.接受单个输入.多维数据或 ...
- 机器学习5- 对数几率回归+Python实现
目录 1. 对数几率回归 1.1 求解 ω 和 b 2. 对数几率回归进行垃圾邮件分类 2.1 垃圾邮件分类 2.2 模型评估 混淆举证 精度 交叉验证精度 准确率召回率 F1 度量 ROC AUC ...
- Popular generalized linear models|GLMM| Zero-truncated Models|Zero-Inflated Models|matched case–control studies|多重logistics回归|ordered logistics regression
============================================================== Popular generalized linear models 将不同 ...
- 1.1、Logistics Regression模型
1.线性可分VS线性不可分 对于一个分类问题,通常可以分为线性可分与线性不可分两种 .如果一个分类问题可以使用线性判别函数正确的分类,则称该问题为线性可分.如图所示为线性可分,否则为线性不可分: 下图 ...
- ogistic regression (逻辑回归) 概述
:http://hi.baidu.com/hehehehello/blog/item/0b59cd803bf15ece9023d96e.html#send http://en.wikipedia.or ...
- 【转】Logistic regression (逻辑回归) 概述
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性.比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等 ...
- 转:Logistic regression (逻辑回归) 概述
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性.比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等 ...
随机推荐
- 图解Spark Graphx基于connectedComponents函数实现连通图底层原理
原创/朱季谦 第一次写这么长的graphx源码解读,还是比较晦涩,有较多不足之处,争取改进. 一.连通图说明 连通图是指图中的任意两个顶点之间都存在路径相连而组成的一个子图. 用一个图来说明,例如,下 ...
- 升讯威在线客服系统的并发高性能数据处理技术:高性能TCP服务器技术
我在业余时间开发维护了一款免费开源的升讯威在线客服系统,也收获了许多用户.对我来说,只要能获得用户的认可,就是我最大的动力. 最近客服系统成功经受住了客户现场组织的压力测试,获得了客户的认可. 客户组 ...
- 升讯威在线客服系统的并发高性能数据处理技术:PLINQ并行查询技术
我在业余时间开发维护了一款免费开源的升讯威在线客服系统,也收获了许多用户.对我来说,只要能获得用户的认可,就是我最大的动力. 最近客服系统成功经受住了客户现场组织的压力测试,获得了客户的认可. 客户组 ...
- git命令和遇到的问题
命令 1.快速关联/修改Git远程仓库地址 (1).删除本地仓库当前关联的无效远程地址,再为本地仓库添加新的远程仓库地址 git remote -v //查看git对应的远程仓库地址 git remo ...
- Cplex混合整数规划求解(Python API)
绝对的原创!罕见的Cplex-Python API混合整数规划求解教程!这是我盯了一天的程序一条条写注释一条条悟出来的•́‸ก 一.问题描述 求解有容量限制的的设施位置问题,使用Benders分解.模 ...
- MySQL系列之主从复制基础——企业高可用性标准、主从复制简介、主从复制前提(搭建主从的过程)、主从复制搭建、主从复制的原理、主从故障监控\分析\处理、主从延时监控及原因
文章目录 0.企业高可用性标准 *** 0.1 全年无故障率(非计划内故障停机) 0.2 高可用架构方案 1. 主从复制简介 ** 2. 主从复制前提(搭建主从的过程) *** 3. 主从复制搭建(C ...
- 关于tiptop gp5.2采购模块,价格变更的随笔
采购价格变更要看具体环节,你可以把他当作是三张表,采购价格表.收货价格表.入库价格表,这些还好处理,如果已抛砖到财务端生成账款再要求改价格就更复杂,会产生更多张表了,改起来也就更复杂. 用apmt91 ...
- 【XXE漏洞】原理及实践演示
一.原理 XML是用于传输和存储数据的一种格式,相当于一种信息传输工具,其中包含了XML声明,DTD文档类型定义.文档元素. XXE是xml外部实体注入漏洞,发生在应用程序解析XML输入时,没有禁止外 ...
- SSH 免秘钥登录
yum -y install expect ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa for i in 192.168.1.11 1 ...
- 源码搭建zabbix平台
1.基于lnmp部署zabbix监控平台; zabbix优点: 1.支持自动发现服务器和网络设备: 2.分布式的监控体系和集中式的WEB管理: 3.支持主动监控和被动监控模式: 4.基于SNMP.IP ...