python爬虫实战以及数据可视化
需要准备的环境:
(1)python3.8
(2)pycharm
(3)截取网络请求信息的工具,有很多,百度一种随便用即可。
第一:首先通过python的sqlalchemy模块,来新建一个表。
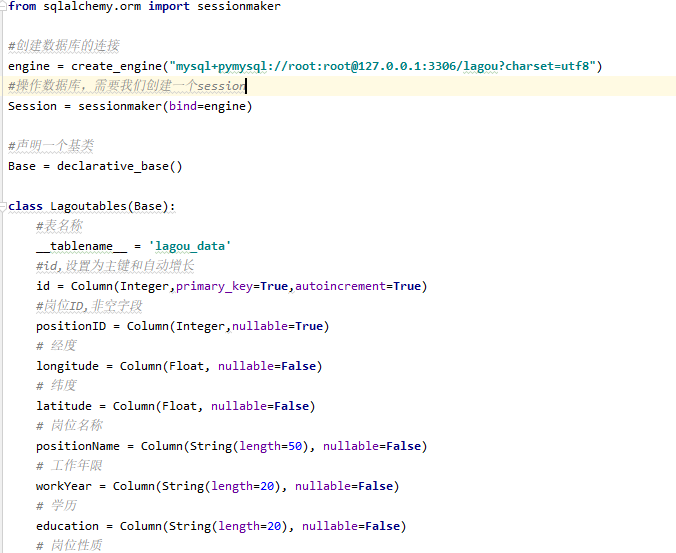
第二:通过python中的request模块接口的形式调取数据。
思路:(1)先获取所有城市信息:需要用request模块中的【requests.session()】session对象保存访问接口需要用到的信息:例如cookies等信息。
(2)通过城市分组,再用正则表达式筛选来获取python的岗位信息。
其中多次用到列表生成器,以后要多注意这方面的冷知识;不然会有莫名的错误。、 代码思路:只要保证可复用即可,其实很简单,毕竟Python是一门”干净“的语言。
(1)先把请求方法抽集到一个方法中:
session.get(url(地址),headers(头信息),,timeout(时间),proxies(代理信息))
(2)先获取所有城市,利用列表生成器生成一个list把数据装进去。
(3)利用循环以城市分组拉去Python岗位信息。
for city in lagou.city_list:
调用拉取岗位信息的方法。
(4)导入multiprocessing模块,设置多线程加速抓取:multiprocessing.Pool(自定 int or long)
需要注意的是:必须利用代理,以及多线程拉取。否则效率低下,可能导致信息不全,时间太慢。

第三:将拉取的数据存入表中
思路:(1)由于拉取的是JSON格式,所以解读JSON格式,也是很繁琐的,需要把要的数据一条一条对应到固定的Key里,如图:

(2)利用session对象的query方法,可以过滤查询想要的数据。
session.query(Lagoutables.workYear).filter(Lagoutables.crawl_date==self.date).all()
第四:利用前台模板,将数据可视化。
(1)首先需要通过编写JS文件,将几个图的数据放在一个方法里提高聚合,抽取出来提高可复用性。 (2)然后通过拼接把获取到的JSON格式的数据,按key:balue格式分配出来。
代码如下:
利用Ajax通信

结果展示:

主要代码展示:
第一部分:拉取数据。
(1)使用session保存cokkies信息。
self.lagou_session = requests.session()
(2)写一个request方法;用于请求数据。使用多线程,以及代理的方式来;否则会记录恶意IP,不能爬虫。
def handle_request(self,method,url,data=None,info=None):
while True:
#加入阿布云的动态代理
proxyinfo = "http://%s:%s@%s:%s" % ('H1V32R6470A7G90D', 'CD217C660A9143C3', 'http-dyn.abuyun.com', '9020')
proxy = {
"http":proxyinfo,
"https":proxyinfo
}
try:
if method == "GET":
# response = self.lagou_session.get(url=url,headers=self.header,proxies=proxy,timeout=6)
response = self.lagou_session.get(url=url,headers=self.header,timeout=6)
elif method == "POST":
# response = self.lagou_session.post(url=url,headers=self.header,data=data,proxies=proxy,timeout=6)
response = self.lagou_session.post(url=url,headers=self.header,data=data,timeout=6)
except:
# 需要先清除cookies信息
self.lagou_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=" % info
self.handle_request(method="GET", url=first_request_url)
time.sleep(10)
continue
response.encoding = 'utf-8'
if '频繁' in response.text:
print(response.text)
#需要先清除cookies信息
self.lagou_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%info
self.handle_request(method="GET",url=first_request_url)
time.sleep(10)
continue
return response.text
(3)写一个具体的URL来拉取网页信息。比如:
#获取全国所有城市列表的方法
def handle_city(self):
city_search = re.compile(r'www\.lagou\.com\/.*\/">(.*?)</a>')
city_url = "https://www.lagou.com/jobs/allCity.html"
city_result = self.handle_request(method="GET",url=city_url)
#使用正则表达式获取城市列表
self.city_list = set(city_search.findall(city_result))
self.lagou_session.cookies.clear()
第二部分:将拉取的数据存入数据库。
将数据库字段与获取到的JSON数据对应,代码简单就不举例了。
主要是用到数据库的session信息;通过导包,获得该数据库连接的Session对象,然后操作数据库。
#插入数据
self.mysql_session.add(data)
#提交数据到数据库
self.mysql_session.commit()
第三部分:将数据库数据以Echarts工具展示出来。
可以查看官网有教学: https://www.echartsjs.com/zh/index.html
主要也是去修改js文件,比较简单;这里就不做示范了。
全部代码,可以去本人的Githup上下载。
注意:本次爬虫教学并不是本人所原创,只是分享一下学习结果。
python爬虫实战以及数据可视化的更多相关文章
- PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二手急速响应捡垃圾平台_3(附源码持续更新)
说明 文章首发于HURUWO的博客小站,本平台做同步备份发布. 如有浏览或访问异常图片加载失败或者相关疑问可前往原博客下评论浏览. 原文链接 PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- Python 爬虫实战(二):使用 requests-html
Python 爬虫实战(一):使用 requests 和 BeautifulSoup,我们使用了 requests 做网络请求,拿到网页数据再用 BeautifulSoup 解析,就在前不久,requ ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
随机推荐
- 协议 UARST & 数据发送与接收
STM32具有的协议 UASRT是通用异步/同步收发器,UART是通用异步收发器 串口空闲状态时高电平,开始传输数据时,第一个数据为固定的低电平: 数据:最后为高电平的停止位 奇偶校验:通过+1或者不 ...
- live [lɪv , laɪv] 动词读lɪv 形容词读laɪv
live [lɪv , laɪv] 动词读lɪv 形容词读laɪv live 英 [lɪv , laɪv] 美 [lɪv , laɪv] v. 居住;住;生存;(尤指在某时期)活着;(以某种方式)生活 ...
- 添加 alt + d 打开 dicts.cn 网址
代码 autohotkey 代码 限制在双核浏览器 内部使用 #IfWinActive ahk_exe ChromeCore.exe !d:: Run, http://www.dicts.cn/ Re ...
- 快速搭建Web安全测试环境
快速搭建Web安全测试环境 1.虚拟机安装 2.网站搭建 一.虚拟机安装 下载VMware虚拟机,Windows 虚拟机 | Workstation Pro | VMware | CN 安装VMwar ...
- Android 开发Day7
<project version="4"> <component name="ExternalStorageConfigurationManager&q ...
- 运行xxl-job,整合xxl-job至jeecg-boot项目
1.前言:xxl-job是一个分布式任务调度平台,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并接入多家公司线上产品线,开箱即用. 源码仓库地址:https://gitee.co ...
- KingbaseES V8R6 fillfactor 对于表的影响
前言 fillfactor 表的填充因子是一个介于 10 和 100 之间的百分数.100是默认值.如果指定了较小的填充因子,INSERT操作仅按照填充因子指定的百分率填充表页.每个页上的剩余空间将用 ...
- KingbaseES file_dw 介绍
file_dw简介 file_fdw模块提供外部数据包装器file_fdw, 它能被用来访问服务器的文件系统中的数据文件,或者在服务器上执行程序并读取它们的输出. 数据文件或程序输出必须是能够被C ...
- Linux电脑如何下载QGIS?
本文介绍在Linux操作系统Ubuntu版本中,通过命令行的方式,配置QGIS软件的方法. 在Ubuntu等Linux系统中,可以对空间信息加以可视化的遥感.GIS软件很少,比如ArcGIS下 ...
- gRPC入门学习之旅(四)
gRPC入门学习之旅(一) gRPC入门学习之旅(二) gRPC入门学习之旅(三) 实现定义的服务 9.在"解决方案资源管理器"中,使用鼠标左键选中"Services&q ...