基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719
1、基于Spark自动扩展scikit-learn(spark-sklearn)
1.1 导论
Spark MLlib 将传统的单机机器学习算法改造成分布式机器学习算法,比如在梯度下降算法中,单机做法是计算所有样本的梯度值,单机算法是以全体样本为计算单位;而分布式算法的逻辑是以每个样本为单位,在集群上分布式的计算每个样本的梯度值,然后再对每个样本的梯度进行聚合操作等。在Spark Mllib中分布式的计算单位可以是:一个样本数据、一个分区的样本数据,一个矩阵等等,分布式的计算单位根据算法的需求而不同,前提条件是每个单位的计算应该是可独立,不依赖于其它单位的计算结果,所以一般在分布式算法设计时,需要把每个单位计算时所需要的数据放在一个单位里,例如在ALS的分布式设计中,将U和V的数据进行重新分区,并建立新的数据集。
Spark Mllib实现了在大数据训练样本下的分布式计算,适应于工程化的实践项目中,如果当计算模型中需要涉及到各种模型参数的调优时,Spark Mllib就会显得有些不足,那我们能否设想下:在小样本训练集下,我在Spark上随机生成1千万个计算模型,把这1千万个计算模型分布式的运行在Spark集群上对训练集进行模型测试计算,是不是可以得到一个结果最优的模型,该模型对应的参数就是最优参数,然后我们根据最优化参数应用在工程化的实践中。
我们可以对Spark Mllib 进行扩展,把我们的带有参数的机器学习模型当作分布的计算单位,每个单位的元素包括:(带参数的模型,训练样本,测试样本),每个单位的计算过程就是将对训练样本训练带参数的模型,得到模型,然后计算测试样本的精度,在集群中对各个单位进行分布式的计算,最终取得最优结果的那个模型。
这就是我下面要介绍的:Auto-scaling scikit-learn with Spark。
1.2 spark-sklearn背景
数据科学家经常花几个小时或几天来调优模型使得计算的精度最高。这种调优通常是在Python或R中运行大量的单机机器学习(ML)任务。
目前Spark集成了Scikit-learn包,这样可以极大的简化了Python数据科学家们的工作,这个包可以在Spark集群上自动分配模型参数优化计算任务,而且不影响现有的工作流程:
如果在单个机器上使用时, Spark可以使用scikit-learn(Joblib)替代默认的多线程框架。
如果需要工作在多台机器上,也不需要修改代码,可以在单机和集群中运行。
1.3 轻松应对大规模模型计算
对于数据分析处理,Python是一种最流行的编程语言,这在很大程度上是由于高质量的计算库,比如数据分析的Pandas 和机器学习orscikit-learn等。Scikit-learn提供快速、健壮的标准ML算法如集群、分类和回归等。
Scikit-learn的优势通常是在单个节点上进行机器学习的计算,。对于一些常见的场景,如参数调优,大量小任务可以并行地运行。这些场景可以完美使用Spark来解决。
1.4 随机森林的分布优化
采用图像识别数字的一个经典例子。数据包括:数字图像的数据集与对应的标签:

我们通过训练随机森林分类器来识别数字。这个分类器有许多参数需要调整,但是没有简单的方法来知道哪个参数效果的好与坏,除了尝试大量的不同组合。Scikit-learn提供了GridSearchCV接口,一个搜索算法,自动搜索最优参数设置。如下图示例,GridSearchCV采用交叉验证的方式进行参数选择,每个参数设置产生一个模型,最终选择表现最好的模型。
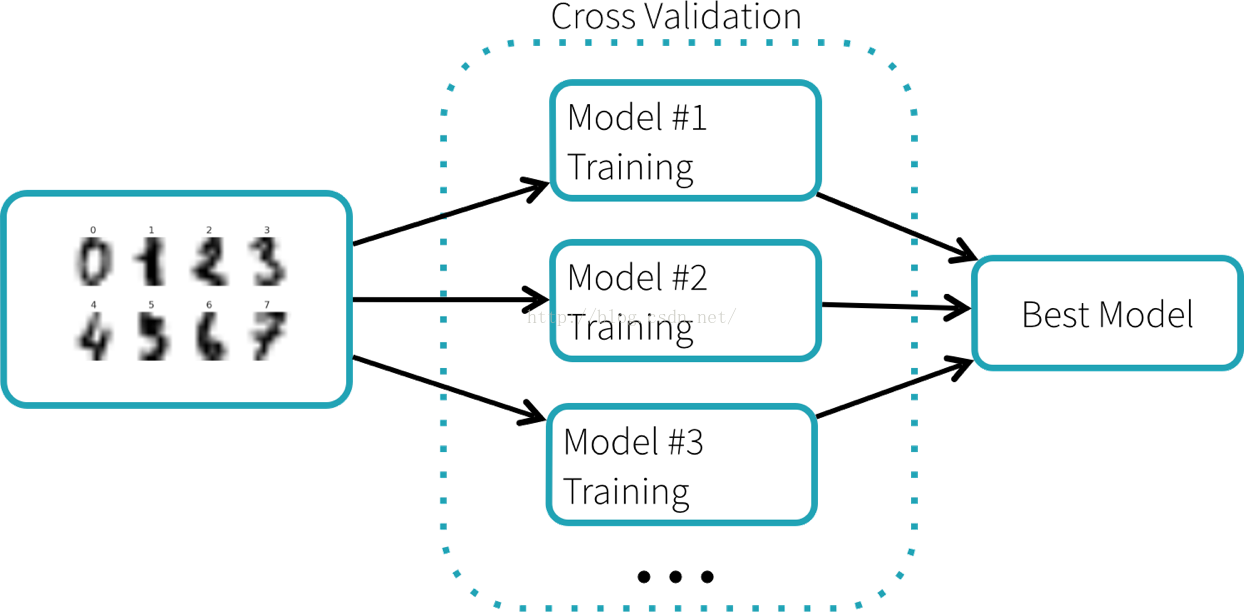
使用scikit-learn的原代码如下:
from sklearn import grid_search, datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
digits = datasets.load_digits()
X, y = digits.data, digits.target
param_grid = {"max_depth": [, None],
"max_features": [, , ],
"min_samples_split": [, , ],
"min_samples_leaf": [, , ],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [, , , ]}
gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
gs.fit(X, y)
训练数据集很小(数百kb),但探索所有的组合大约需要5分钟。Spark的scikit-learn包提供了一种在Spark集群上进行分布式的交叉验证算法计算工作。每个节点运行训练算法使用的本地的scikit-learn库,并且向集群的master报告最佳模型:
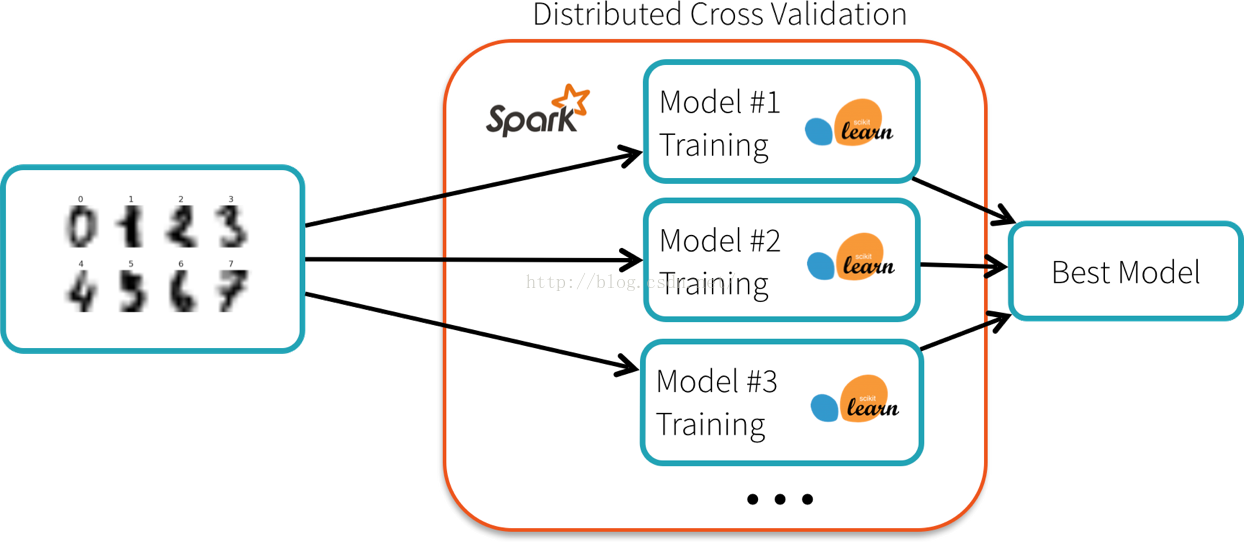
他之前的代码是一样的,除了一行变化:
from sklearn import grid_search, datasets
from sklearn.ensemble import RandomForestClassifier
# Use spark_sklearn’s grid search instead:
from spark_sklearn import GridSearchCV
digits = datasets.load_digits()
X, y = digits.data, digits.target
param_grid = {"max_depth": [, None],
"max_features": [, , ],
"min_samples_split": [, , ],
"min_samples_leaf": [, , ],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [, , , ]}
gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
gs.fit(X, y)
这个例子在4个节点(16 cpu)的集群上运行时间小于30秒。对于大数据集和更多的参数设置,效率的提升则更大。
如果你想试试这个包,需要:
https://pypi.python.org/pypi/spark-sklearn
http://spark-packages.org/package/databricks/spark-sklearn
实例地址:http://go.databricks.com/hubfs/notebooks/Samples/Miscellaneous/blog_post_cv.html
详细见API:
http://pythonhosted.org/spark-sklearn/
基于Spark自动扩展scikit-learn (spark-sklearn)(转载)的更多相关文章
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
场景 好的,假设项目数据调研与需求分析已接近尾声,马上进入Coding阶段了,辣么在Coding之前需要干马呢?是的,“统一开发工具.开发环境的搭建与本地测试.测试环境的搭建与测试” - 本文详细记录 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 【Spark深入学习 -14】Spark应用经验与程序调优
----本节内容------- 1.遗留问题解答 2.Spark调优初体验 2.1 利用WebUI分析程序瓶颈 2.2 设置合适的资源 2.3 调整任务的并发度 2.4 修改存储格式 3.Spark调 ...
- 【Spark深入学习-11】Spark基本概念和运行模式
----本节内容------- 1.大数据基础 1.1大数据平台基本框架 1.2学习大数据的基础 1.3学习Spark的Hadoop基础 2.Hadoop生态基本介绍 2.1Hadoop生态组件介绍 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- spark第六篇:Spark Streaming Programming Guide
预览 Spark Streaming是Spark核心API的扩展,支持高扩展,高吞吐量,实时数据流的容错流处理.数据可以从Kafka,Flume或TCP socket等许多来源获取,并且可以使用复杂的 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
随机推荐
- laravel 汇总数据
public function userInfluenceCollect(Request $request) { $types = ['logins', "checkins", & ...
- python数据分析实例(1)
1.获取数据: 想要获得道指30只成分股的最新股价 import requests import re import pandas as pd def retrieve_dji_list(): try ...
- apache安装软负载的配置说明
安装Apache:yum -y install httpd 首先要查看apache的安装版本 命令:httpd –v 第一种: 若安装是2.2版本,则把复制 mod_wl_22.so和mod_wl.s ...
- Actor消息发送及等待结果关键字
class Task extends Actor{ override def act(): Unit = { while(true){ receive({ case SmTask(file) => ...
- Python_多进程
Python 多进程库 multiprocessing ,支持子进程.通信.数据共享.执行不同形式的同步 多进程,绕过gil ,实现多核的利用,多进程也是原生进程,由操作系统维护 在pycharm中, ...
- 习题集1b: 额外练习 (可选)
1.练习:4.样本特点 用来描述样本的数字叫做? □ 参数 (√)□ 统计量 □ 变量 □ 常数 2.练习:5.大一学生体重情况 Freidman 博士在一所大学任教,她记录了所在大学每位大一新生 ...
- String,StringBuffer,StringBudilder区别--2019-04-13
String,StringBuffer,StringBudilder区别: 1String 是字符串常量,创建内容不可以变, final修饰意味着String类型不能被继承,减少被修改的可能,从而最大 ...
- 理解ActivityManagerService
--摘自<Android进阶解密> *AMS家族* 1.Android 7.0的AMS家族 2.AMP和AMS进行通信 3.(Android 7.0)AMP是AMN的内部类,它们都实现了I ...
- [是男人就过8题——Pony.ai]Perfect N-P Arrays
[是男人就过8题--Pony.ai]Perfect N-P Arrays 题目大意: 一棵\(n(\sum n\le5\times10^6)\)个结点的树,每个结点都有一个括号.求树上一个合法的括号序 ...
- js 类数组对象arguments
function Add() { for (var i = 0; i < arguments.length; i++) { console.log(arguments[i]); } } Add( ...